







文章目录
一、集成学习(Ensemble learning)
目的
让机器学习效果更好,在机器学习中,很多不同的算法。那些算法都是单打独斗的英雄。而集成学习就是将这些英雄组成团队。实现“3 个臭皮匠顶个诸葛亮”的效果。
二、随机森林(Bagging方法)——民主
2.1什么是随机森林(Random Forest)?
它属于集成学习中的Bagging方法,关系如下图:

解释随机森林之前,需要了解决策树,请移步如下链接。
链接: 决策树
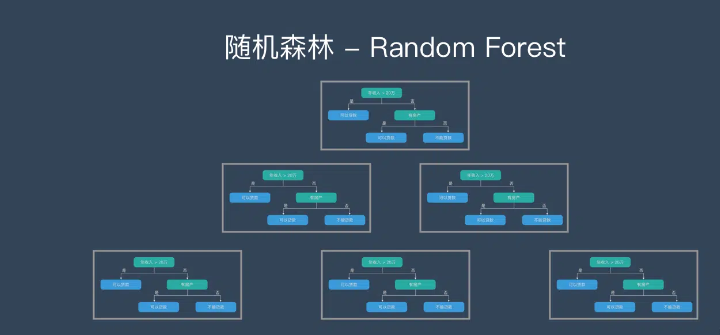
随机森林是由很多决策树构成的,不同决策树之间没有关联。
当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。
2.2思路
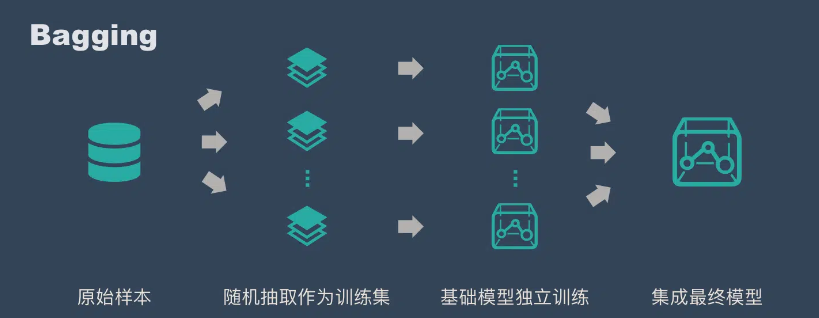
思路:Bagging 的思路是所有基础模型都一致对待,每个基础模型手里都只有一票。然后使用民主投票的方式得到最终的结果。
大部分情况下,经过bagging得到结果方差更小。
2.3过程
具体过程:
- 从原始样本抽取训练集。
每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
Bootstrapping算法: 是利用有限的样本经由多次重复抽样,建立起足以代表母体样本分布之新样本,在机器学习中解决了样本不足的问题。
- 每次使用一个训练集得到一个模型,k个训练集得到k个模型。
- 对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对待回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
举例:bagging+决策树=随机森林
2.4构造随机森林的4个步骤
1.随机抽样 训练决策树
一个样本容量为N的样本,有放回的抽取N次,每次抽取1个,最终形成了N个样本。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
2.随机选取属性,做节点分裂属性
当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
3.重复步骤2,知道不能再分类
决策树形成过程中每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
4.建立大量决策树,形成森林
按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
三、Boosting——挑选精英
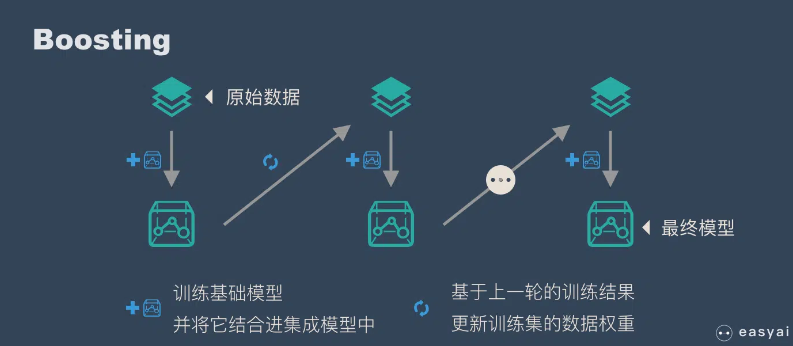
思路: Boosting 和 bagging 最本质的差别在于他对基础模型不是一致对待的,而是经过不停的考验和筛选来挑选出「精英」,然后给精英更多的投票权,表现不好的基础模型则给较少的投票权,然后综合所有人的投票得到最终结果。
大部分情况下,经过 boosting 得到的结果偏差(bias)更小。
具体过程:
- 通过加法模型将基础模型进行线性的组合。
- 每一轮训练都提升那些错误率小的基础模型权重,同时减小错误率高的模型权重。
- 在每一轮改变训练数据的权值或概率分布,通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样例的权值,来使得分类器对误分的数据有较好的效果。
训练多个分类器取平均: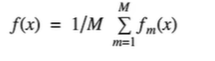
四、Bagging和Boosting的差别
样本选择
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
样例权重
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
预测函数
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
并行计算
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
五、装袋算法(learner)
在机器学习中,分为弱learner和强learner,装袋算法主要用于处理弱learner。
弱learner
像随机森林这样的集合模型使用装袋算法来避免高方差和过度拟合的缺陷,而单个决策树等更简单的模型更容易出现。当算法通过随机数据样本建立决策树时,所有数据都是可以被利用起来的。
综上所述: 随机森林模型使用装袋算法来构建较少的决策树,每个决策树与数据的随机子集同时构建。
随机森林模型中的每个树不仅包含数据的子集,每个树也只使用数据的特征子集。















 1254
1254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









