








分布式一致性哈希
提出
假设我有三台服务器A,B,C,我想把数据分别存储到这三台服务器上,于是进行哈希取余操作:hash(key)%3.
然而,如果我又增加了一台服务器D,哈希取余就得变成hash(key)%4了,数据就很混乱了。
对此,我们对固定值2^32进行取余,并把哈希数组前后两端闭合形成一个圆,将A,B,C三台服务器映射到这个圆上(以字符串:ip:port为key):
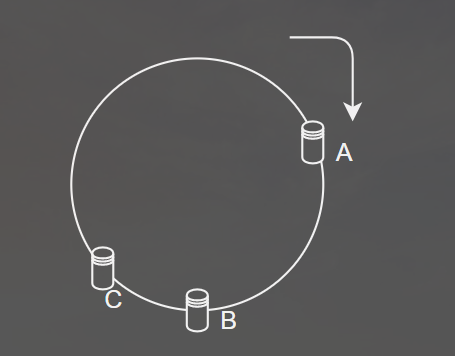
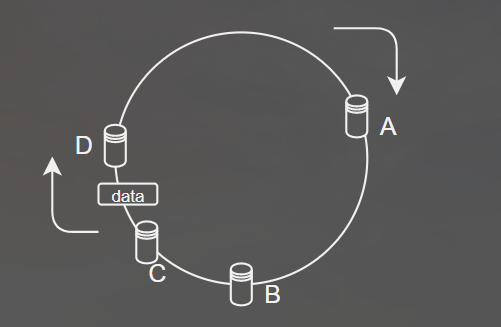
当我们将数据哈希后,落到圆上某一个点,顺时针方向走,存到遇到的第一个服务器上,当我们新增一个服务器D时,操作仍然不变(A中的部分数据需迁移到D中)
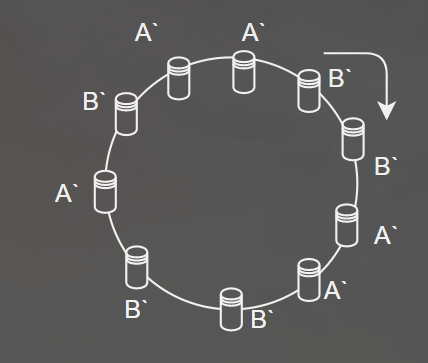
服务器哈希不均匀的问题
由于节点数量太少,服务器可能哈希不均匀,导致有的服务器要存储大部分数据,负载不均,如上图的A,B服务器,对此,可将一个服务器映射成多个虚拟节点,如服务器A可映射成 port:ip:1,port:ip:2,...,port:ip:n (这样取key时能快速得到真实服务器ip和port),这样,各个服务器的虚拟节点将较均匀地分布在圆上(以A,B为例):
tip:
为啥哈希函数里老喜欢用i*31呢
- 31是质数,能让哈希分布更随机(表现比17和101要好)
- i*(1<<5-1)=i<<5-i,转换为位运算计算更快。另外哈希计算经常出现 m%2^n, 也是因为方便转换为位运算m&(2^n-1)















 271
271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









