







迷宫问题是一类经典的搜索策略问题。首先创建一个10*10的迷宫,生成障碍物,寻找从入口到出口的方法。
Cell
我们首先定义存放迷宫的二维数组,为了显示其路径,我们定义了一个枚举类Cell.java
public enum Cell {
EMPTY(" "),
START("S"),
GOAL("G"),
BLOCK("X"),
PATH("*");
private String code; // 用于表示Cell的字符
Cell(String code) {
this.code = code;
}
@Override
public String toString() {
return code; // 返回Cell的字符
}
}其中,空格代表空,“S”表示开始,“G”表示终点,“X”表示障碍,“*”表示走过的路径
MazeLocation
随后,定义表示在迷宫的某一个位置的类MazeLocation,用于取当前位置、向各个方向行走的事件。
该类的equals方法用于判断输入,hashCode由于判断走过的路径是否重复,并构造Getter方法和重写toString方法。
import java.util.Objects;
/**
* 表示迷宫中的一个位置
*/
public class MazeLocation {
private int rowN;
private int colN;
public MazeLocation(int rowN, int colN) {
super();
this.rowN = rowN;
this.colN = colN;
}
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null) return false;
if (getClass() != obj.getClass()) return false;
MazeLocation other = (MazeLocation) obj;
return colN == other.colN && rowN == other.rowN;
}
@Override
public int hashCode() {
return Objects.hash(rowN, colN);
}
public int getRowN() {
return rowN;
}
public int getColN() {
return colN;
}
@Override
public String toString() {
return "MazeLocation [rowN=" + rowN + ", colN=" + colN + "]";
}
}Maze
接下来,定义随机迷宫,需要有以下的参数,行,列,障碍密集度,起始位置,终点位置,一个存储迷宫的二维数组。
int rowCount;
int colCount;
double separseness; // 至少有20%的空白
MazeLocation start;
MazeLocation goal;
Cell[][] grids;定义构造方法:
public Maze() {
this(9,9,0.1,new MazeLocation(0,0),new MazeLocation(8,8));
}
public Maze(int rowCount, int colCount, double separseness, MazeLocation start, MazeLocation goal) {
super();
this.rowCount = rowCount;
this.colCount = colCount;
this.separseness = separseness;
grids = new Cell[rowCount][colCount];
this.start = start;
this.goal = goal;
initMaze();
fillRandomBlock();
fillStartAndGoal();
}在构造方法中,我们需要初始化迷宫(initMaze),随机填充障碍(fillRandomBlock)和填充开始结束为止(fillStartAndGoal),下面定义这些私有方法
private void initMaze() {
for (int i = 0; i < rowCount; i++) {
for (int j = 0; j < colCount; j++) {
grids[i][j] = Cell.EMPTY;
}
}
}
private void fillRandomBlock() { // 初始化迷宫
for (int i = 0; i < rowCount; i++) {
for (int j = 0; j < colCount; j++) {
if (Math.random() < separseness) {
grids[i][j] = Cell.BLOCK;
}
}
}
}
private void fillStartAndGoal() {
int sRowN = start.getRowN(), sColN = start.getColN();
int gRowN = goal.getRowN(), gColN = goal.getColN();
grids[sRowN][sColN] = Cell.START;
grids[gRowN][gColN] = Cell.GOAL;
}初始化迷宫,当生成的随机数小于设定的障碍密集度时就设定障碍。
接下来定义fillStartAndGoal方法里需要的Getter方法和重写toString方法,以及调用测试,标记路径、清除重复走的路径的方法。
public int getRowCount() {
return rowCount;
}
public int getColCount() {
return colCount;
}
public boolean testGoal(MazeLocation loc) {
return loc.equals(goal);
}
public void mark(List<MazeLocation> mls) {
for (MazeLocation loc : mls) { // 标记路径
grids[loc.getRowN()][loc.getColN()] = Cell.PATH;
}
// 标记起点和终点
grids[start.getRowN()][start.getColN()] = Cell.START;
grids[goal.getRowN()][goal.getColN()] = Cell.GOAL;
}
public void clear(List<MazeLocation> mls) {
for (int i = 0; i < rowCount; i++) {
for (int j = 0; j < colCount; j++) {
if (grids[i][j] == Cell.PATH) {
grids[i][j] = Cell.EMPTY;
}
}
}
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < rowCount; i++) {
for (int j = 0; j < colCount; j++) {
sb.append(grids[i][j]);
sb.append(" ");
}
sb.append("\n");
}
return sb.toString();
}随后,定义行走的方法,我们用一个列表来记录行走的路径。
public List<MazeLocation> successor(MazeLocation loc) {
List<MazeLocation> result = new ArrayList<>();
int rowN = loc.getRowN(), colN = loc.getColN();
// 右
if (colN + 1 < colCount && grids[rowN][colN + 1] != Cell.BLOCK) {
result.add(new MazeLocation(rowN, colN + 1));
}
// 左
if (colN - 1 >= 0 && grids[rowN][colN - 1] != Cell.BLOCK) {
result.add(new MazeLocation(rowN, colN - 1));
}
// 上
if (rowN - 1 >= 0 && grids[rowN - 1][colN] != Cell.BLOCK) {
result.add(new MazeLocation(rowN - 1, colN));
}
// 下
if (rowN + 1 < rowCount && grids[rowN + 1][colN] != Cell.BLOCK) {
result.add(new MazeLocation(rowN + 1, colN));
}
return result;
}Maze.java 完整代码如下:
import java.util.*;
public class Maze {
int rowCount;
int colCount;
double separseness; // 至少有20%的空白
MazeLocation start;
MazeLocation goal;
Cell[][] grids;
public Maze() {
this(9,9,0.1,new MazeLocation(0,0),new MazeLocation(8,8));
}
public Maze(int rowCount, int colCount, double separseness, MazeLocation start, MazeLocation goal) {
super();
this.rowCount = rowCount;
this.colCount = colCount;
this.separseness = separseness;
grids = new Cell[rowCount][colCount];
this.start = start;
this.goal = goal;
initMaze();
fillRandomBlock();
fillStartAndGoal();
}
public int getRowCount() {
return rowCount;
}
public int getColCount() {
return colCount;
}
private void initMaze() {
for (int i = 0; i < rowCount; i++) {
for (int j = 0; j < colCount; j++) {
grids[i][j] = Cell.EMPTY;
}
}
}
private void fillRandomBlock() { // 初始化迷宫
for (int i = 0; i < rowCount; i++) {
for (int j = 0; j < colCount; j++) {
if (Math.random() < separseness) {
grids[i][j] = Cell.BLOCK;
}
}
}
}
private void fillStartAndGoal() {
int sRowN = start.getRowN(), sColN = start.getColN();
int gRowN = goal.getRowN(), gColN = goal.getColN();
grids[sRowN][sColN] = Cell.START;
grids[gRowN][gColN] = Cell.GOAL;
}
public List<MazeLocation> successor(MazeLocation loc) {
List<MazeLocation> result = new ArrayList<>();
int rowN = loc.getRowN(), colN = loc.getColN();
// 右
if (colN + 1 < colCount && grids[rowN][colN + 1] != Cell.BLOCK) {
result.add(new MazeLocation(rowN, colN + 1));
}
// 左
if (colN - 1 >= 0 && grids[rowN][colN - 1] != Cell.BLOCK) {
result.add(new MazeLocation(rowN, colN - 1));
}
// 上
if (rowN - 1 >= 0 && grids[rowN - 1][colN] != Cell.BLOCK) {
result.add(new MazeLocation(rowN - 1, colN));
}
// 下
if (rowN + 1 < rowCount && grids[rowN + 1][colN] != Cell.BLOCK) {
result.add(new MazeLocation(rowN + 1, colN));
}
return result;
}
public boolean testGoal(MazeLocation loc) {
return loc.equals(goal);
}
public void mark(List<MazeLocation> mls) {
for (MazeLocation loc : mls) { // 标记路径
grids[loc.getRowN()][loc.getColN()] = Cell.PATH;
}
// 标记起点和终点
grids[start.getRowN()][start.getColN()] = Cell.START;
grids[goal.getRowN()][goal.getColN()] = Cell.GOAL;
}
public void clear(List<MazeLocation> mls) {
for (int i = 0; i < rowCount; i++) {
for (int j = 0; j < colCount; j++) {
if (grids[i][j] == Cell.PATH) {
grids[i][j] = Cell.EMPTY;
}
}
}
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < rowCount; i++) {
for (int j = 0; j < colCount; j++) {
sb.append(grids[i][j]);
sb.append(" ");
}
sb.append("\n");
}
return sb.toString();
}
}
至此,迷宫的构建全部完成
深度优先搜索
我们首先使用深度优先搜索(DFS)算法探索迷宫。深度优先搜索的主要思路是,先一直探索一个结点的某一个子结点,直到没有子结点为止,如果当前结点不是终点,则回溯继续探索其他子结点。
我们知道,DFS使用的是堆栈的数据结构。当该结点有子结点就入栈,直到没有为止。
因此,我们现需要定义一个结点类
Node
public class Node<T> {
Node<T> parent;
T currentNode;
public Node(T currentNode, Node<T> parent) {
super();
this.parent = parent;
this.currentNode = currentNode;
}
public Node<T> getParent() {
return parent;
}
public T getCurrentNode() {
return currentNode;
}
}
Node类是一个泛型类,用于存放迷宫的某一个位置。
BFS
我们会定义一个GenerateSearcher类,存放各种搜过策略的方法。(代码最后给出)
下面展示bfs的具体方法
// 深度优先搜索
public static <T> Node<T> dfs(Function<T, List<T>> successors, Predicate<T> goalTest, T start) {
Node<T> sn = new Node<>(start, null);
Stack<Node<T>> frontier = new Stack<>();
frontier.push(sn);
Set<T> explored = new HashSet<>();
explored.add(start);
while (!frontier.isEmpty()) {
sn = frontier.pop();
T location = sn.getCurrentNode();
if (goalTest.test(location)) {
break;
}
for (T child : successors.apply(location)) {
if (explored.contains(child)) {
continue;
}
Node<T> newNode = new Node<>(child, sn);
explored.add(child);
frontier.push(newNode);
}
}
return sn;
}DFS 算法的主循环在 frontier 栈不为空时运行。在循环内部,方法从栈中弹出一个节点 (sn = frontier.pop()) 并获取其当前状态 (T location = sn.getCurrentNode())。然后检查该状态是否满足目标条件,如果满足则退出循环。
如果当前节点不是目标,方法通过应用 successors 函数来获取后继节点列表。然后遍历这些后继节点。对于每个后继节点,检查该节点是否已经被探索过。如果没有,则为该后继节点创建一个新的 Node 对象,并将当前节点作为其父节点 (new Node<>(child, sn))。然后将该新节点添加到 explored 集合和 frontier 栈中。
最后,一旦循环退出,方法返回表示目标状态的节点或最后一个被探索的节点。
生成单元测试
下面是一个单元测试:
@Test
public void testDFS() {
Maze maze = new Maze(10, 10, 0.2, new MazeLocation(0, 0), new MazeLocation(9, 9));
// MazeLocation goal = new MazeLocation(9, 9); // 终点
MazeLocation start = new MazeLocation(0, 0); // 起点
Node<MazeLocation> node = GenericSearcher.dfs(maze::successor, maze::testGoal, start); // 深度优先搜索
List<MazeLocation> path = GenericSearcher.nodePath(node); // 获得路径
maze.mark(path); // 标记路径
System.out.println(maze); // 输出迷宫
}运行结果
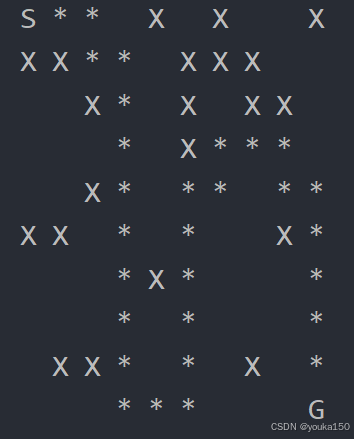
显然dfs不是最短路径,他会绕远路。
广(宽)度优先搜索
广(宽)度优先搜索(BFS)则是一步一步探索该结点的所有子结点。其用到的数据结构则是队列,因此,需要调用Java.util.Quene。
// 广度优先搜索
public static <T> Node<T> bfs(Function<T, List<T>> successors, Predicate<T> goalTest, T start) {
Node<T> sn = new Node<>(start, null);
Queue<Node<T>> frontier = new LinkedList<>(); // 构造一个空队列
frontier.add(sn); // 将初始节点加入队列
Set<T> explored = new HashSet<>(); // 用于记录已经探索过的节点
explored.add(start);
while (!frontier.isEmpty()) {
sn = frontier.poll();
T location = sn.getCurrentNode(); // 取出队列的头节点
if (goalTest.test(location)) { // 判断是否为目标节点,是则退出
break;
}
for (T child : successors.apply(location)) { // 遍历当前节点的所有子节点
if (explored.contains(child)) { // 如果子节点已经探索过,则跳过
continue;
}
Node<T> newNode = new Node<>(child, sn);
explored.add(child); // 标记为已探索
frontier.add(newNode); // 将子节点加入队列
}
}
return sn;
}生成单元测试
@Test
public void testBFS() {
Maze maze = new Maze(10, 10, 0.2, new MazeLocation(0, 0), new MazeLocation(9, 9));
// MazeLocation goal = new MazeLocation(9, 9);
MazeLocation start = new MazeLocation(0, 0);
Node<MazeLocation> node = GenericSearcher.bfs(maze::successor, maze::testGoal, start);
List<MazeLocation> path = GenericSearcher.nodePath(node);
maze.mark(path);
System.out.println(maze);
}测试结果
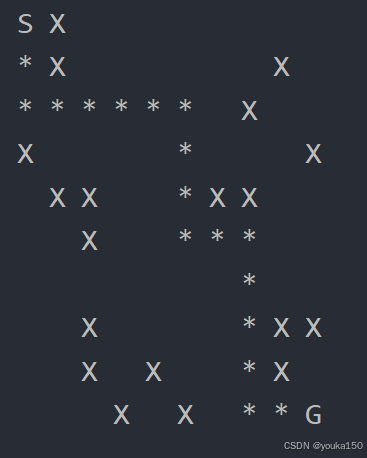
这种方法相比于深度优先搜索,路径较优
GenericSearcher
最后给出存储两种搜索策略的GenericSearcher类
import java.util.*;
import java.util.function.*;
public class GenericSearcher {
// 深度优先搜索
public static <T> Node<T> dfs(Function<T, List<T>> successors, Predicate<T> goalTest, T start) {
Node<T> sn = new Node<>(start, null);
Stack<Node<T>> frontier = new Stack<>();
frontier.push(sn);
Set<T> explored = new HashSet<>();
explored.add(start);
while (!frontier.isEmpty()) {
sn = frontier.pop();
T location = sn.getCurrentNode();
if (goalTest.test(location)) {
break;
}
for (T child : successors.apply(location)) {
if (explored.contains(child)) {
continue;
}
Node<T> newNode = new Node<>(child, sn);
explored.add(child);
frontier.push(newNode);
}
}
return sn;
}
// 获得路径
public static <T> List<T> nodePath(Node<T> node) {
List<T> result = new ArrayList<>();
Node<T> parent = node.getParent();
T currentState = node.getCurrentNode();
result.add(currentState);
while (parent != null) {
currentState = parent.getCurrentNode();
result.add(currentState);
parent = parent.getParent();
}
return result;
}
// 广度优先搜索
public static <T> Node<T> bfs(Function<T, List<T>> successors, Predicate<T> goalTest, T start) {
Node<T> sn = new Node<>(start, null);
Queue<Node<T>> frontier = new LinkedList<>(); // 构造一个空队列
frontier.add(sn); // 将初始节点加入队列
Set<T> explored = new HashSet<>(); // 用于记录已经探索过的节点
explored.add(start);
while (!frontier.isEmpty()) {
sn = frontier.poll();
T location = sn.getCurrentNode(); // 取出队列的头节点
if (goalTest.test(location)) { // 判断是否为目标节点,是则退出
break;
}
for (T child : successors.apply(location)) { // 遍历当前节点的所有子节点
if (explored.contains(child)) { // 如果子节点已经探索过,则跳过
continue;
}
Node<T> newNode = new Node<>(child, sn);
explored.add(child); // 标记为已探索
frontier.add(newNode); // 将子节点加入队列
}
}
return sn;
}
}


















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









