






 本文详细解释了显卡(GPU)的基础知识,包括不同架构的发展历程,如Tesla、Fermi、Kepler等。同时介绍了显卡驱动、CUDA(通用并行计算架构)的作用,cuDNN(深度学习加速库)的功能,以及NVCC和CUDAToolkit的角色。最后提到nvidia-smi工具的作用和CUDA版本管理的注意事项。
本文详细解释了显卡(GPU)的基础知识,包括不同架构的发展历程,如Tesla、Fermi、Kepler等。同时介绍了显卡驱动、CUDA(通用并行计算架构)的作用,cuDNN(深度学习加速库)的功能,以及NVCC和CUDAToolkit的角色。最后提到nvidia-smi工具的作用和CUDA版本管理的注意事项。
关于显卡、显卡驱动、cuda、cuDNN等的区别
刚接触AI或机器学习框架时,经常会被这几个概念搞混,尤其是显卡驱动、cuda、cuDNN这个三个软的东西;此外,NVCC、cudatoolkit又是什么呢?
1. 显卡(GPU)
显卡就是硬件,比较好理解,经常被叫做GPU就是这玩意;以Nvida的GPU为例,硬件显卡一些核心区分类别如下:
GPU架构:Tesla(特斯拉)、Fermi(费米)、Kepler(开普勒)、Maxwell(麦克斯韦)、Pascal(帕斯卡)、Volta(瓦特)、Turing(图灵)、Ampere(安培)
芯片型号:GT200、GK210、GM104、GF104等
架构的具体实现即芯片
显卡系列:GeForce、Quadro、Tesla
系列本质上没什么区别,Nvida为了区分应用而已,通常GeFore用于家庭娱乐,Quadro用于工作站,而Tesla系列用于服务器
GeForce显卡型号:G/GS、GT、GTS、GTX
在显卡性能上,通常 G/GS<GT<GTS<GTX
1.1 GPU架构
gpu架构指的是硬件的设计方式,例如流处理器簇中有多少个core、是否有L1 or L2缓存、是否有双精度计算单元等等。每一代的架构是一种思想,如何去更好完成并行的思想
1、Tesla架构
2006年,英伟达发布首个通用GPU计算架构Tesla。它采用全新的CUDA架构,支持使用C语言进行GPU编程,可以用于通用数据并行计算。Tesla架构具有128个流处理器,带宽高达86GB/s,标志着GPU开始从专用图形处理器转变为通用数据并行处理器。
2、Fermi架构
2009年,英伟达发布Fermi架构,是第一款采用40nm制程的GPU。Fermi架构带来了重大改进,包括引入L1/L2快速缓存、错误修复功能和 GPUDirect技术等。Fermi GTX 480拥有480个流处理器,带宽达到177.4GB/s,比Tesla架构提高了一倍以上,代表了GPU计算能力的提升。
3、Kepler架构
2012年,英伟达发布Kepler架构,采用28nm制程,是首个支持超级计算和双精度计算的GPU架构。Kepler GK110具有2880个流处理器和高达288GB/s的带宽,计算能力比Fermi架构提高3-4倍。Kepler架构的出现使GPU开始成为高性能计算的关注点。
4、Maxwell架构
2014年,英伟达发布Maxwell架构,采用28nm制程。Maxwell架构在功耗效率、计算密度上获得重大提升,一个流处理器拥有128个CUDA核心,而Kepler仅有64个。GM200具有3072个CUDA核心和336GB/s带宽,但功耗只有225W,计算密度是Kepler的两倍。Maxwell标志着GPU的节能计算时代到来。
5、Pascal架构
2016年,英伟达发布Pascal架构,采用16nm FinFETPlus制程,增强了GPU的能效比和计算密度。Pascal GP100具有3840个CUDA核心和732GB/s的显存带宽,但功耗只有300W,比Maxwell架构提高50%以上。Pascal架构使GPU可以进入更广泛的人工智能、汽车等新兴应用市场。
6、Volta架构
2017年,英伟达发布Volta架构,采用12nm FinFET制程。Volta 架构新增了张量核心,可以大大加速人工智能和深度学习的训练与推理。Volta GV100具有5120个CUDA 核心和900GB/s的带宽,加上640个张量核心,AI计算能力达到112 TFLOPS,比Pascal架构提高了近3倍。Volta的出现标志着AI成为GPU发展的新方向。
7、Turing架构
2018年,英伟达发布Turing 架构,采用12nm FinFET制程。Turing架构新增了Ray Tracing核心(RT Core),可硬件加速光线追踪运算。Turing TU102具有4608个CUDA核心、576个张量核心和72个RT核心,支持GPU光线追踪,代表了图形技术的新突破。同时,Turing架构在人工智能方面性能也有较大提升。
8、Ampere架构
2020年,英伟达发布Ampere架构,采用Samsung 8nm制程。Ampere GA100具有6912个CUDA核心、108个张量核心和hr个RT核心,比Turing架构提高约50%。Ampere 架构在人工智能、光线追踪和图形渲染等方面性能大幅跃升,功耗却只有400W,能效比显著提高。
1.2 显卡芯片
芯片就是对上述gpu架构思想的实现,例如芯片型号GT200中第二个字母代表是哪一代架构,有时会有100和200代的芯片,它们基本设计思路是跟这一代的架构一致,只是在细节上做了一些改变,例如GK210比GK110的寄存器就多一倍。有时候一张显卡里面可能有两张芯片,Tesla k80用了两块GK210芯片。
1.3 显卡系列
而显卡系列在本质上并没有什么区别,只是NVIDIA希望区分成三种选择,GeFore用于家庭娱乐,Quadro用于工作站,而Tesla系列用于服务器。Tesla的k型号卡为了高性能科学计算而设计,比较突出的优点是双精度浮点运算能力高并且支持ECC内存,但是双精度能力好在深度学习训练上并没有什么卵用,所以Tesla系列又推出了M型号来做专门的训练深度学习网络的显卡。需要注意的是Tesla系列没有显示输出接口,它专注于数据计算而不是图形显示。
2. 显卡驱动(软件)
显卡驱动即NVIDIA Driver,就是驱动软件,显卡通过显卡驱动直接控制硬件,也可以说显卡驱动作为显卡硬件的最直接的操作接口。
通常,高版本的显卡驱动软件可以一定程度的向下兼容旧的显卡硬件;所以,能选择高版本的显卡驱动软件,尽可能选择高版本的显卡驱动软件.
3. CUDA
有硬件了,也有显卡驱动软件了,还要CUDA来干什么呢?
CUDA英文全称是Compute Unified Device Architecture,是一种由NVIDIA推出的CUDA通用并行计算架构,该架构使GPU能够解决复杂的计算问题。NVIDIA官方介绍说,CUDA是一个并行计算平台和编程模型,能够使得使用GPU进行通用计算变得简单和优雅。
官方对CUDA的定义:CUDA是NVIDIA创建的一个并行计算平台和编程模型,它不是编程语言,也不是一种API。CUDA的官方定义出处,点这里
CUDA is a parallel computing platform and programming model created by NVIDIA. Some people confuse CUDA, launched in 2006, for a programming language — or maybe an API.
显然,CUDA是显卡驱动的上层应用(你要是足够牛逼可以直接基于显卡驱动自己鲁自己的GPU并行计算应用架构)
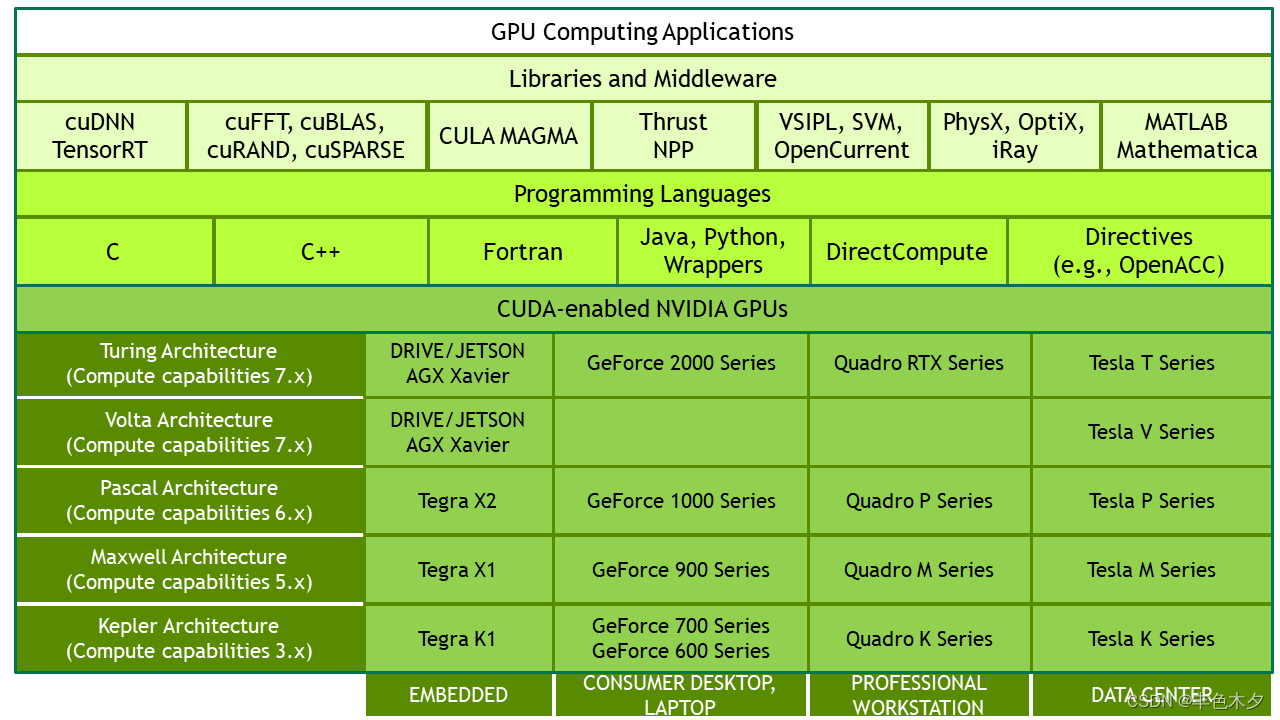
4. cuDNN
官方对cuDNN的定义: NVIDIA CUDA 深度神经网络库(cuDNN)是一个用于深度神经网络的GPU加速库。cuDNN为标准例程(如前向和后向卷积、池化、归一化和激活层)提供了高度优化的实现。
The NVIDIA CUDA® Deep Neural Network library (cuDNN) is a GPU-accelerated library of primitives for deep neural networks. cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers.
5. CUDA Toolkit
CUDA Toolkit可以认为是一个软件安装包,它可以安装cuda driver,nvcc(编译器),libraries, CUDA Samples;
CUDA Toolkit由以下组件组成:
-
Compiler: CUDA-C和CUDA-C++编译器NVCC位于bin/目录中。它建立在NVVM优化器之上,而NVVM优化器本身构建在LLVM编译器基础结构之上。希望开发人员可以使用nvm/目录下的Compiler SDK来直接针对NVVM进行开发。
-
Tools: 提供一些像profiler,debuggers等工具,这些工具可以从bin/目录中获取
-
Libraries: 下面列出的部分科学库和实用程序库可以在lib/目录中使用(Windows上的DLL位于bin/中),它们的接口在include/目录中可获取。
cudart: CUDA Runtime
cudadevrt: CUDA device runtime
cupti: CUDA profiling tools interface
nvml: NVIDIA management library
nvrtc: CUDA runtime compilation
cublas: BLAS (Basic Linear Algebra Subprograms,基础线性代数程序集)
cublas_device: BLAS kernel interface
…
- CUDA Samples: 演示如何使用各种CUDA和library API的代码示例。可在Linux和Mac上的samples/目录中获得,Windows上的路径是C:ProgramDataNVIDIA CorporationCUDA Samples中。在Linux和Mac上,samples/目录是只读的,如果要对它们进行修改,则必须将这些示例复制到另一个位置。
- CUDA Driver: 运行CUDA应用程序需要系统至少有一个具有CUDA功能的GPU和与CUDA工具包兼容的驱动程序。每个版本的CUDA工具包都对应一个最低版本的CUDA Driver,也就是说如果你安装的CUDA Driver版本比官方推荐的还低,那么很可能会无法正常运行。CUDA Driver是向后兼容的,这意味着根据CUDA的特定版本编译的应用程序将继续在后续发布的Driver上也能继续工作。通常为了方便,在安装CUDA Toolkit的时候会默认安装CUDA Driver。在开发阶段可以选择默认安装Driver,但是对于像Tesla GPU这样的商用情况时,建议在官方安装最新版本的Driver。
最新的Toolkit(CUDA 12.3 Update 2 Release)包组件清单如下所示
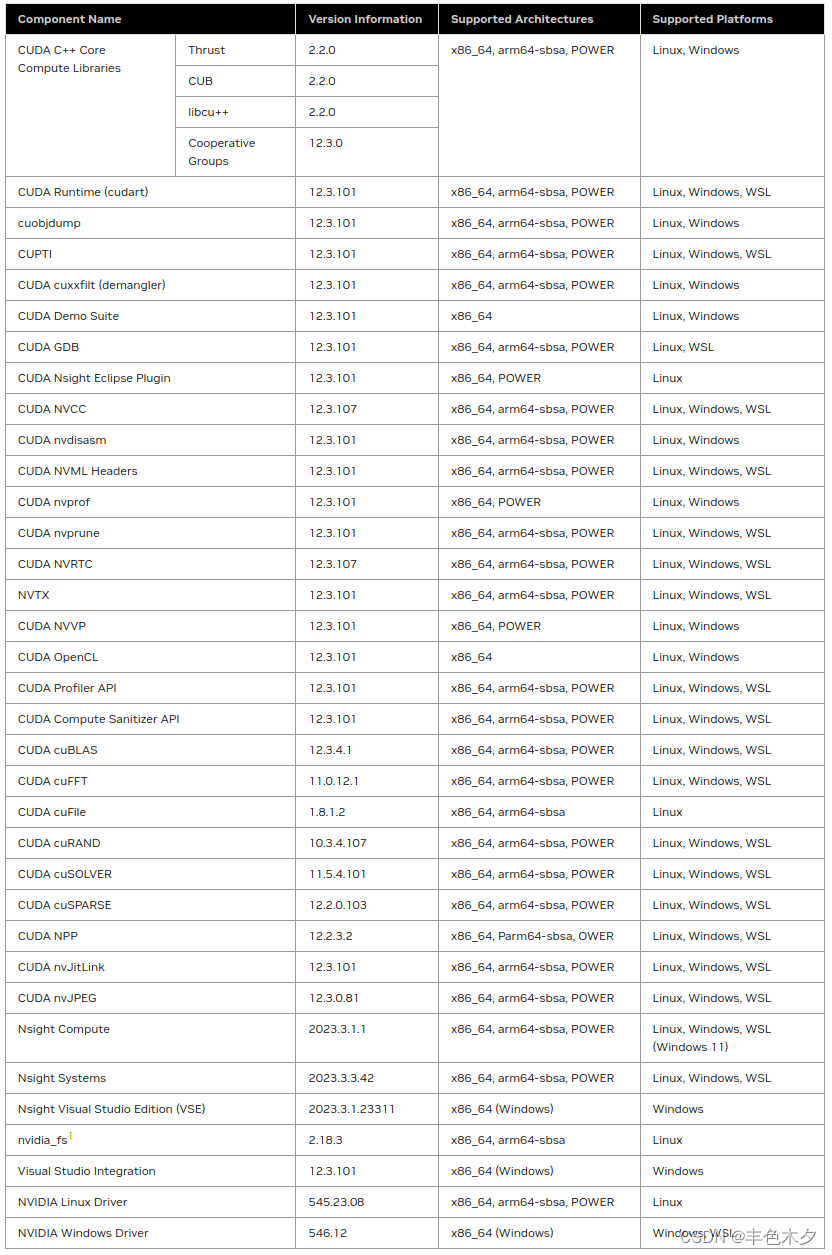
注意,cudaToolkit包中,并没有包含cuDNN
6. NVCC
NVCC其实就是CUDA的编译器,类似于gcc/g++就是c/c++语言的编译器,可以从CUDA Toolkit的/bin目录中获取。由于程序是要经过编译器编程成可执行的二进制文件,而cuda程序有两种代码,一种是运行在cpu上的host代码,另一种是运行在gpu上的device代码,所以nvcc编译器要保证两部分代码能够编译成二进制文件在不同的机器上执行,nvcc涉及到的文件如下表:
| 文件后缀 | 意义 |
|---|---|
| .cu | cuda源文件,包括host和device代码 |
| .cup | 经过预处理的cuda源文件,编译选项–preprocess/-E |
| .c | c源文件 |
| .cc/.cxx/.cpp | c++源文件 |
| .gpu | gpu中间文件,编译选项–gpu |
| .ptx | 类似汇编代码,编译选项–ptx |
| .o/.obj | 目标文件,编译选项–compile/-c |
| .a/.lib | 库文件,编译选项–lib/-lib |
| .res | 资源文件 |
| .so | 共享目标文件,编译选项–shared/-shared |
| .cubin | cuda的二进制文件,编译选项-cubin |
7. nvidia-smi
nvidia-smi全程是NVIDIA System Management Interface ,它是NVIDIA Management Library(NVML)构建的命令行实用工具,旨在帮助管理和监控NVIDIA GPU设备。
nvcc和nvidia-smi显示的CUDA版本不同时,是因为CUDA有两个API:一个是runtime API,另一个是driver API。用于支持driver APIU的必要文件是由GPU driver installer安装的,nvidia-smi就属于这一类;用于支持runtime API的必要文件(如libcudart.so以及nvcc)是由CUDA Toolkit installer安装的,nvcc是与CUDA Toolkit一起安装的CUDA compiler-driver tool,它只知道它自身构建时的CUDA runtime版本。它不知道安装了什么版本的GPU driver,甚至不知道是否安装了GPU driver。
综上,如果driver API和runtime API的CUDA版本不一致可能是因为你使用的是单独的GPU driver installer,而不是CUDA Toolkit installer里的GPU driver installer。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









