






recap
之前,讨论了 theory of generation,也就是如果
Ein
很小的时候,什么时候可以推至
Eout
也很小。
我们的答案是,如果
mH(N)
在某些地方出现了一线曙光,也就是出现了break point,造成了不能shatter,增长速度达不到
2N
的速度的点,那么它的上限是poly多项式,同时如果N也很大的话,可以确定犯错误的上限在一定程度内。
more on growth function
当
N>2,K>3
时,
mH(N)<=NK−1
,上限是一个多项式。

more on VC bound
保证了无论演算法做了任何的选择,都被VC bound所支配,保证挑出来的假设
h
可以使得

VC Definition
the formal name of maximum non-break point
比
dvc
大1的话,就是break point k。
好的
Hset
,一开始是说增长函数有漏出一线曙光,出现break point的点。现在可以说
dvc
有限的假设集就是好的假设集。
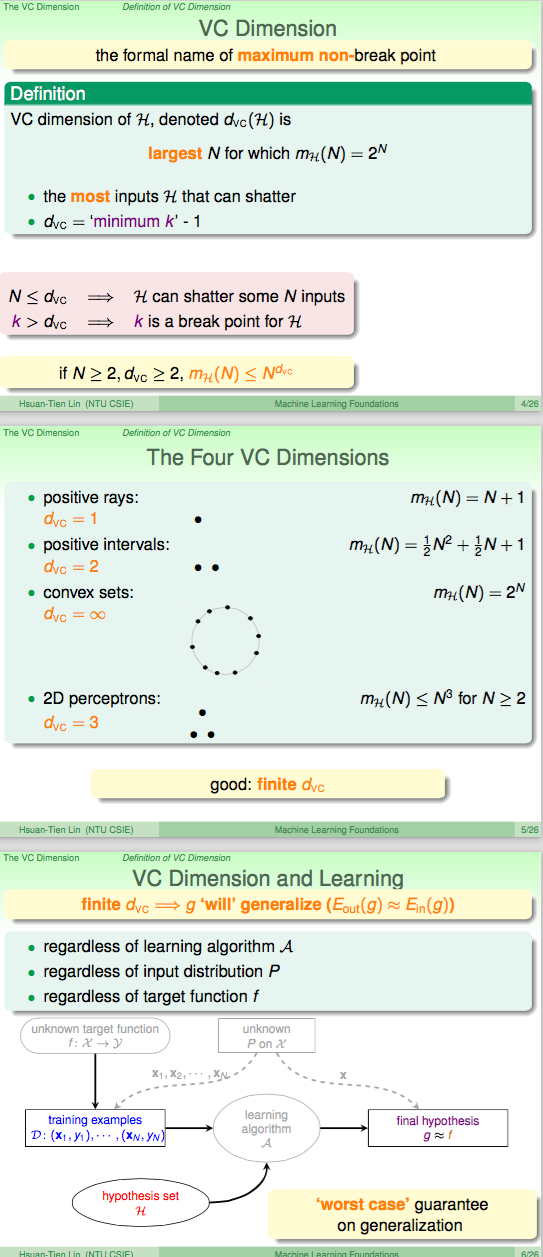
VC of perceptrons
对于特定的N,shatter的话只举一个例子就可以了,不shatter的话必须保证对于N个点的所有可能分布都不能shatter。
Revisited 2d

dvc>=d+1
只需要证明d+1个点的情况下可以shatter。
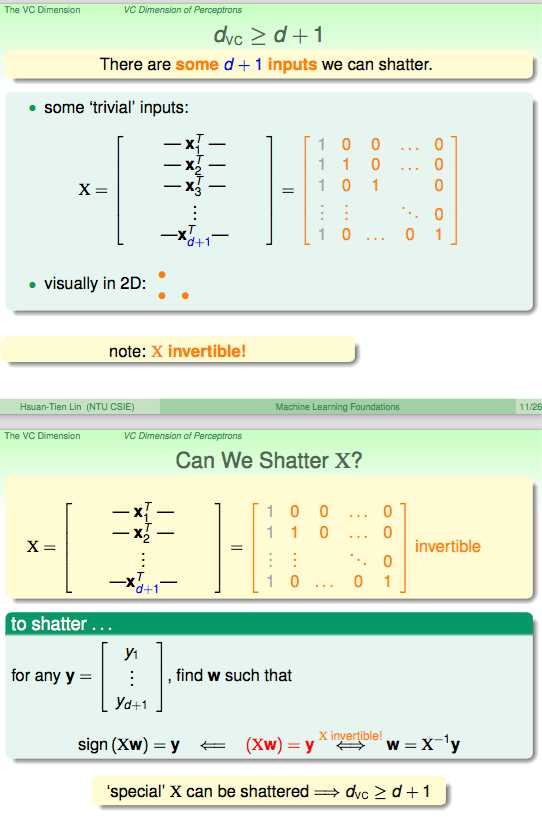
dvc<=d+1
只需证明d+2个点的情况下不可以shatter。
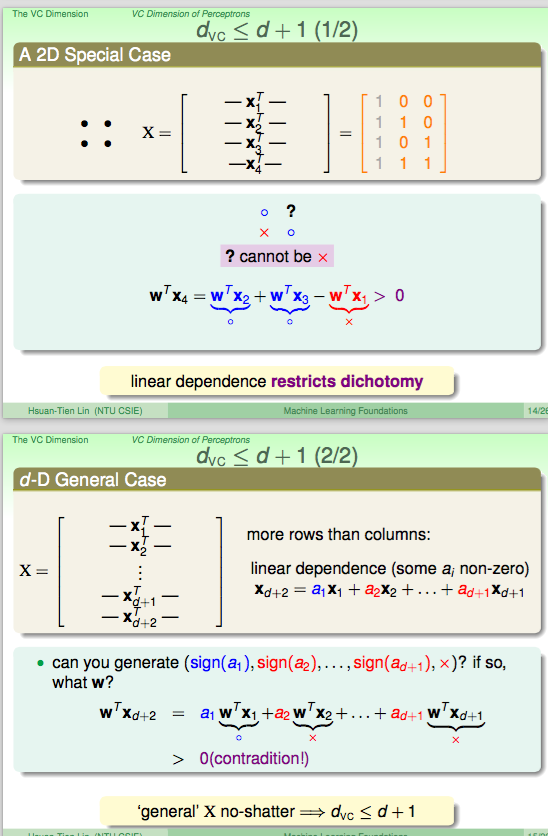
linear dependence restricts dichotomy.
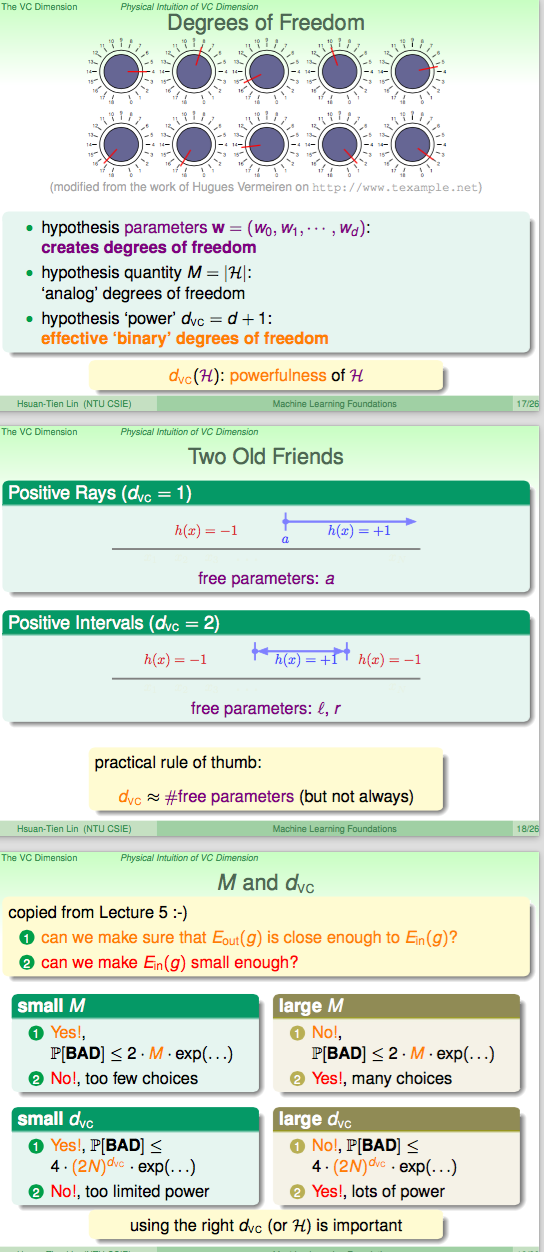
physical intuition of VC
d+1 就是d个perceptron的维度。
w就是degree of fredom
物理意义大致是:假设集,做二元分类的话有多少自由度(effective)。
举例子来说,二维的感知器有三个自由度(w0,w1,w2)。
powerfulness of H,可以产生多少个dichonomy。
有多少可以调的旋钮。代表H的自由度。
interpreting VC
model越强,vc更高,越能够shatter二分类,需要付出的model complety代价很大。
Ein 做好不一定是最好的选择,可能会付出很大的模型复杂度的代价 Ω 。
penalty for model complexity
Eout 和 Ein 的差距和 Ω 有关

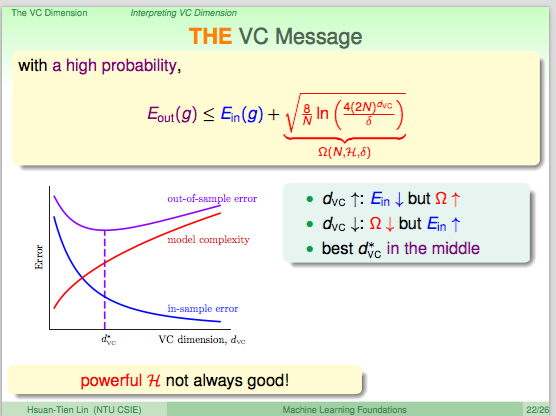
VC message
一般来说,我们考虑 Eout 的容忍上限。
通常,我们希望vc很大,这样的话可以shatter的点很多,假设集的power更强,因此通常可以在
Ein
上取得很好的效果。
但是,当模型的复杂度上升的时候,
Eout
的误差上限变大,也就是无法保证测试集外的结果和训练集有同样的高正确率,这样即使训练集内部正确率再高也无用。
因此,需要选择合适的vc,也就是选择合适的假设集,合适的模型复杂度。
sample complexity
一般来说,我们希望将犯错的的bound限制在一定的范围内,但是误差限度是提前制定的,这时候便需要考虑样本集的数量的。
样本集数量和bound的变化趋势如下图所示,因为这个bound的过程中有很多上限化简,因此理论的和实际的有所差异。

looseness of VC bound
理论和实际的差异如下。
有差异也不一定坏啊,这种差异是建立在模型泛化的基础上,从而可以使VC bound的适用条件变宽。
对于之后学习的模型,甚至可以用vc去比较。

















 517
517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









