







在一个文件中分两行写上:
yaojiale hahaha
yaojiale llllll
这个案列完成对单词的计数,重写map,与reduce方法,完成对mapreduce的理解。
一,在map阶段会将数据拆分成小段,存到一个个map中,如果有key相同的,会形成一个新的map,key还是这个,但是vlaues就是那两个相同的map的一个列表。用户自定义map方法用来完成自己的操作。
在这个案存的map:
1,<”yaojiale”,list
二,Reduce阶段将处理结果汇总。即对相应的map进行处理。
在这里重写的reduce方法取到key也就是单词,一个就取其值,有相同则遍历取值相加。
结果:
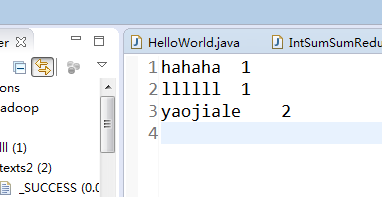
代码:
重写的reduce:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class IntSumSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
System.out.println("reduces的key===="+key);
for (IntWritable val : values) {
sum += val.get();
System.out.println("reudces的val==="+val.toString());
}
result.set(sum);
context.write(key, result);
}
}
重写的map方法:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class TokenizerMapper extends Mapper<Object,Text,Text,IntWritable> {
private final static IntWritable one=new IntWritable(1);//注意这里实列化时要付个1,否则后面的计数会不准确
private Text word=new Text();
public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
System.out.println("key="+key.toString());//添加查看的key值
System.out.println("value="+value.toString());
StringTokenizer itr=new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word, one);
}
}
}
hello类:
import java.io.IOException;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class HelloWorld {
public static void main(String[] args) throws URISyntaxException, IOException, ClassNotFoundException, InterruptedException {
Configuration conf=new Configuration();
Job job=Job.getInstance(conf,"word count");
job.setJarByClass(HelloWorld.class);//设定作业的启动类
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumSumReducer.class);
job.setReducerClass(IntSumSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path("F:\\1\\aa.txt"));
FileOutputFormat.setOutputPath(job,new Path("hdfs://192.168.61.128:9000/texts2/"));
System.out.println(job.waitForCompletion(true)?0:1);
}
}

















 987
987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









