







MapReduce由Map和Reduce两个阶段组成,用户自己编写map()和reduce()两个函数。
举例“hello world”程序:用来统计输入文件中每个单词出现的次数。
Map:
map (String key, String value) :
words = SplitIntTokens(value) ;
for each word w in words :
EmitIntermediate(w, “1”) ;
Reduce:
reduce (String key, Iterator values) :
int result = 0 ;
for each v in values :
result += StringToInt (v) ;
Emit (key, IntToSttring (result)) ;
用户编写的MapReduce程序是对输入文件的处理规则,然后用户会指定程序的输入和输出目录,并提交到hadoop集群中,这是hadoop就会按照MapReduce程序对输入文件进行处理。
作业在hadoop中的执行过程:
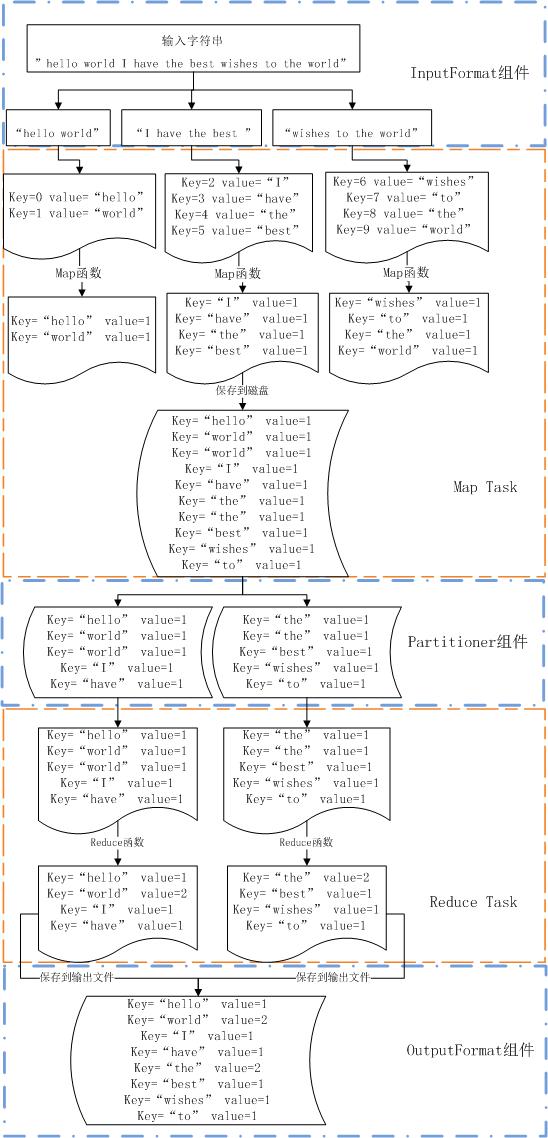
首先由InputFormat组件来对输入文件进行切分,使成为若干个input split,然后将每个split分给一个Map Task来进行处理。Map Task将每个split中的数据解析成map()函数所要求的key/value对,就这里来说每个split的key为字符串偏移量,value为字符串内容,然后对每个key/value对都调用map函数,就这里来说是先将字符串分割成单个的单词,然后对每一个单词都输出一个key/value对,这时key为单词,value为“1”。然后通过partitioner组件将这些中间数据按key进行聚集,并根据Reduce Task的个数来将中间数据分成若干个partition,一般来说同一个key会分到同一个partition中,并将每个partition保存到磁盘上。然后每个Reduce Task读取一个partition,使用基于排序的方法将key相同的数据聚集在一起,再调用reduce函数进行处理,这里输入函数的key是单词,value是单词出现次数列表(例如【1,1,1,1,1】),然后将单词出现次数列表中的每个数目加起来,得到单词总共出现的次数。输出的key为单词,value为单词出现总数。并将结果输出到指定的输出文件中。
遗留问题:
问题1。reduce task和reduce的区别
理解见图
问题2。map task和map的区别
理解见图
问题3。map task、map、reduce、reduce task个数?
问题4。是在partitioner的部分对key进行聚集还是在reduce task的时候才会进行。
Partitioner的作用就是对Mapper产生的中间数据进行分片,以便将同一分片的数据交给同一个Reducer处理。
按照我的猜测,这个过程应该是先由partitioner对所有输出的中间数据按key值进行聚类,然后按照reduce task的数目进行分片,每一片交给一个reduce task来进行处理,然后reduce task会基于排序的方式将key值相同的数据聚集在一起,处理成很多对key/value对的形式,并将每一个key/value对交由一个reduce函数来进行处理。这里key为单词,value为单词出现次数列表。???
衍生问题4.1。partitioner聚类好之后分片的数据应该也是差不多是排序后的数据了,起码上key相同的数据都是放在一起的,那为什么还要进行一次排序呢?
衍生问题4.2。如果在分片是有某个词的出现次数太多,而被分到两个分片中,在reduce一次完成后,是不是要再次进行分片再reduce,怎么知道是不是需要再次进行呢?















 145
145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









