








参考链接:http://pandas.pydata.org/pandas-docs/stable/merging.html
merge
用于通过一个或多个键将两个数据集的行连接起来,类似于 SQL 中的 JOIN。该函数的典型应用场景是,针对同一个主键存在两张包含不同字段的表,现在我们想把他们整合到一张表里。在此典型情况下,结果集的行数并没有增加,列数则为两个元数据的列数和减去连接键的数量。
on=None 用于显示指定列名(键名),如果该列在两个对象上的列名不同,则可以通过 left_on=None, right_on=None 来分别指定。或者想直接使用行索引作为连接键的话,就将 left_index=False, right_index=False 设为 True。
how=’inner’ 参数指的是当左右两个对象中存在不重合的键时,取结果的方式:inner 代表交集;outer 代表并集;left 和 right 分别为取一边。
suffixes=(‘_x’,’_y’) 指的是当左右对象中存在除连接键外的同名列时,结果集中的区分方式,可以各加一个小尾巴。
对于多对多连接,结果采用的是行的笛卡尔积。
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False)默认以重叠的列名作为链接键,默认inner
官方关于how的定义:
how : {‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘inner’
- left: use only keys from left frame (SQL: left outer join)
- right: use only keys from right frame (SQL: right outer join)
- outer: use union of keys from both frames (SQL: full outer join)
- inner: use intersection of keys from both frames (SQL: inner join)
最好是显示的试用on, pd.merge(df1,df2, on=’key’)
pd.merge(df1,df2, left_on=’lkey’, right_on=’rkey’)
对重复列名的处理suffixes, 如
pd.merge(left,right,on=’key1’, suffixes=(‘_left’,’_right’)

df1=DataFrame({'key':['a','b','b'],'data1':range(3)})
df2=DataFrame({'key':['a','b','c'],'data2':range(3)})
pd.merge(df1,df2) 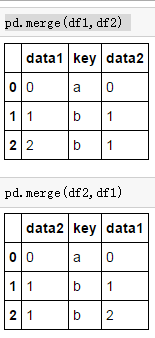

多键连接时将连接键组成列表传入
right=DataFrame({'key1':['foo','foo','bar','bar'],
'key2':['one','one','one','two'],
'lval':[4,5,6,7]})
left=DataFrame({'key1':['foo','foo','bar'],
'key2':['one','two','one'],
'lval':[1,2,3]})
pd.merge(left,right,on=['key1','key2'],how='right')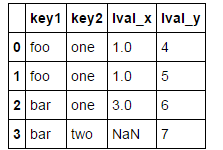
如果两个对象的列名不同,可以分别指定
df3=DataFrame({'key3':['foo','foo','bar','bar'],
'key4':['one','one','one','two'],
'lval':[4,5,6,7]})
pd.merge(left,df3,left_on='key1',right_on='key3',how='right')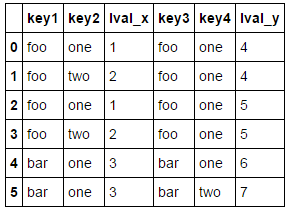
以索引当做连接键,使用参数left_index=true,right_index=True (最好使用join)
join 拼接列,主要用于索引上的合并
join方法提供了一个简便的方法用于将两个DataFrame中的不同的列索引合并成为一个DataFrame。
join方法默认为left。
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])
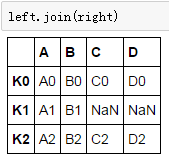
- 默认按索引合并,可以合并相同或相似的索引,不管他们有没有重叠列。
- 可以连接多个DataFrame
- 可以连接除索引外的其他列
- 连接方式用参数how控制
- 通过lsuffix=”, rsuffix=” 区分相同列名的列
同理可以使用merge来实现,要将left_index=True, right_index=True
result = pd.merge(left, right, left_index=True, right_index=True, how='inner')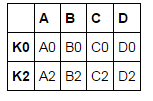
列与index进行合并
left.join(right, on=key_or_keys)
pd.merge(left, right, left_on=key_or_keys, right_index=True,
how='left', sort=False)left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'key': ['K0', 'K1', 'K0', 'K1']}) right = pd.DataFrame({'C': ['C0', 'C1'],
'D': ['D0', 'D1']},
index=['K0', 'K1'])合并
left.join(right, on='key')
pd.merge(left, right, left_on='key', right_index=True,
how='left', sort=False)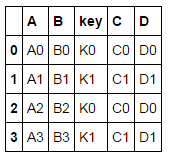
concat 可以沿着一条轴将多个对象堆叠到一起
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)concat方法相当于数据库中的全连接(UNION ALL),可以指定按某个轴进行连接,也可以指定连接的方式join(outer,inner 只有这两种)。与数据库不同的时concat不会去重,要达到去重的效果可以使用drop_duplicates方法
轴向连接 pd.concat() 就是单纯地把两个表拼在一起,这个过程也被称作连接(concatenation)、绑定(binding)或堆叠(stacking)。因此可以想见,这个函数的关键参数应该是 axis,用于指定连接的轴向。
在默认的 axis=0 情况下,pd.concat([obj1,obj2]) 函数的效果与 obj1.append(obj2) 是相同的;
而在 axis=1 的情况下,pd.concat([df1,df2],axis=1) 的效果与 pd.merge(df1,df2,left_index=True,right_index=True,how=’outer’) 是相同的。
可以理解为 concat 函数使用索引作为“连接键”。
举例:
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index=[4, 5, 6, 7])df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index=[8, 9, 10, 11])frames = [df1, df2, df3]
result = pd.concat(frames)
result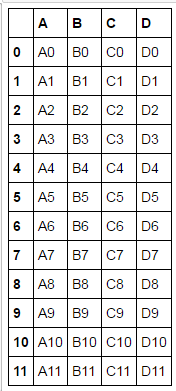
objs 就是需要连接的对象集合,一般是列表或字典;
axis=0 是连接轴向
join=’outer’ 参数作用于当另一条轴的 index 不重叠的时候,只有 ‘inner’ 和 ‘outer’ 可选(顺带展示 ignore_index=True 的用法)
concat 一些特点:
- 作用于Series时,如果在axis=0时,类似union。axis=1 时,组成一个DataFrame,索引是union后的,列是类似join后的结果。
- 通过参数join_axes=[] 指定自定义索引。
- 通过参数keys=[] 创建层次化索引
- 通过参数ignore_index=True 重建索引。
通过keys创建层次化索引
result = pd.concat(frames, keys=['x', 'y', 'z'])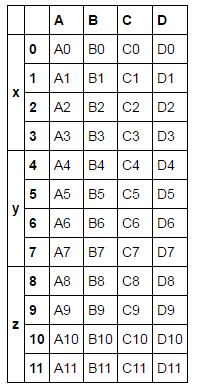
在这种情况下我们可以获得key所对应的内容
result.ix['y']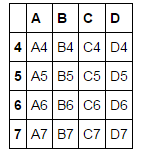
下面来演示axis
pd.concat([df1, df4], axis=1)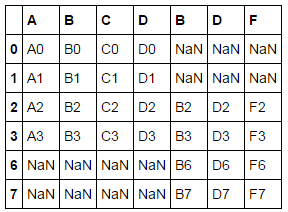
pd.concat([df1, df4], axis=1, join='inner')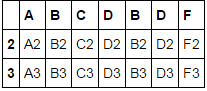
指定自定义索引join_axes
pd.concat([df1, df4], axis=1, join_axes=[df1.index])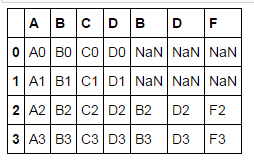
append
df1.append(df4)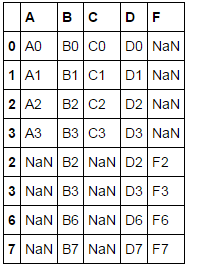
append多个
df1.append([df2, df3])好了,有些累了,具体请参考
http://pandas.pydata.org/pandas-docs/stable/merging.html


















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











