







data=Series(np.random.randn(10),index=[list('aaabbbccdd'),list('1231231223')])
data
a 1 0.198134
2 0.657700
3 -0.984464
b 1 0.105481
2 -1.587769
3 0.329646
c 1 -0.172460
2 -1.234518
d 2 -1.200264
3 -0.239958
dtype: float64
data.index
MultiIndex(levels=[['a', 'b', 'c', 'd'], ['1', '2', '3']],
labels=[[0, 0, 0, 1, 1, 1, 2, 2, 3, 3], [0, 1, 2, 0, 1, 2, 0, 1, 1, 2]])取层次化索引:
data['b':'c']
b 1 0.105481
2 -1.587769
3 0.329646
c 1 -0.172460
2 -1.234518
dtype: float64
data.ix[['b','c']]
b 1 0.105481
2 -1.587769
3 0.329646
c 1 -0.172460
2 -1.234518
dtype: float64取内层索引:
data[:, '2']
a 0.657700
b -1.587769
c -1.234518
d -1.200264
dtype: float64
unstack: 将Series放到DataFrame中
data.unstack()
1 2 3
a 0.198134 0.657700 -0.984464
b 0.105481 -1.587769 0.329646
c -0.172460 -1.234518 NaN
d NaN -1.200264 -0.239958
data.unstack().stack() 进行还原
data.unstack().stack()对于DataFrame,每个轴上都可以有分层索引
frame=DataFrame(np.arange(12).reshape(4,3),
index=[list('aabb'),list('1212')],
columns=[['ohio','ohio','colorado'],['Green','Red','Green']])
frame
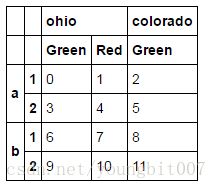
还可以命名:
frame.index.names=['key1','key2']
frame.columns.names=['state','color']
frame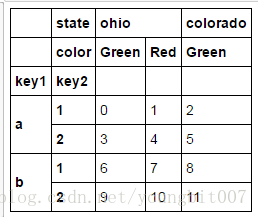
因为有了列索引,所以可以直接取列分组
frame['ohio']根据级别汇总统计
frame.index
MultiIndex(levels=[['a', 'b'], ['1', '2']],
labels=[[0, 0, 1, 1], [0, 1, 0, 1]],
names=['key1', 'key2'])
levels用于在指定在某条轴上进行求和的级别.
frame.sum(level='key2')
frame.sum(level='color',axis=1)
将列转换为行索引
DataFrame的set_index函数会将一个或者多个列转换为行索引,并创建一个新的DataFrame

reset_index的功能跟set_index刚好相反,层次化索引的级别挥别转移到列里面















 301
301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









