







透视表,根据一个或多个键进行聚合,并根据行列上的分组键将数据分配到各个矩形区域中.
import numpy as np
data=pd.DataFrame(np.arange(6).reshape((2,3)),
index=pd.Index(['ohio','color'], name='state'),
columns=pd.Index(['one','two','three'], name='number')
)
data| number | one | two | three |
|---|---|---|---|
| state | |||
| ohio | 0 | 1 | 2 |
| color | 3 | 4 | 5 |
前两个参数分别作用于行和列的索引,最后一个参数用于填充dataframe的数据列的列名
data.pivot('one','two')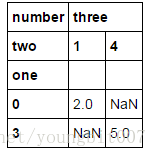
首先,它会设置一个新的索引( set_index() ),然后对索引排序( sort_index() ),最后调用 unstack 。以上的步骤合在一起就是 pivot 。
官方定义:
DataFrame.pivot_table(data, values=None, index=None, columns=None, aggfunc=’mean’, fill_value=None, margins=False, dropna=True, margins_name=’All’)
data: DataFrame对象
values: 显示的列的名字,可以应用aggfunc中的函数
index: 索引
columns: 可选的, 通过额外的方法来分割你所关心的实际值,然而aggfunc被应用到values上, aggfunc默认的是mean
下面来看干货:
打开dat表,分别为users, ratings, movies
import pandas as pd
unames=['user_id','gender','age','occupation','zip']
users=pd.read_table('C:\\Users\\ecaoyng\\Desktop\\work space\\Python\\py_for_analysis\\pydata-book-master\\ch02\\movielens\\users.dat',sep='::',header=None,names=unames)
users.head()合并三个表:
data=pd.merge(pd.merge(ratings, users),movies)
data[:10]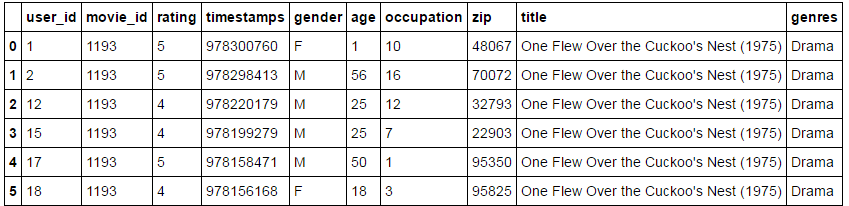
最简单的透视表必须有一个数据帧和一个索引
pd.pivot_table(data, index=['movie_id'])[:10]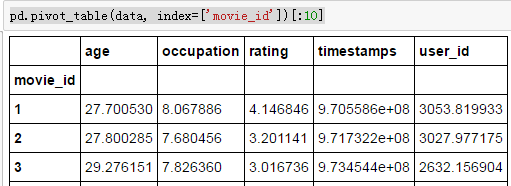
当然也可以建两个index
pd.pivot_table(data, index=['movie_id','occupation'])
pd.pivot_table(data, index=['movie_id','occupation'],values=['rating'])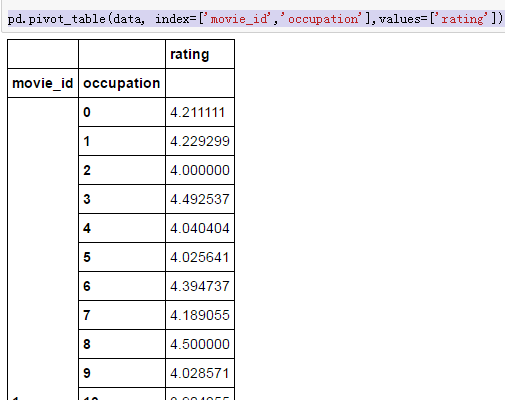
pd.pivot_table(data, index=['movie_id','occupation'],values=['rating'],columns='gender')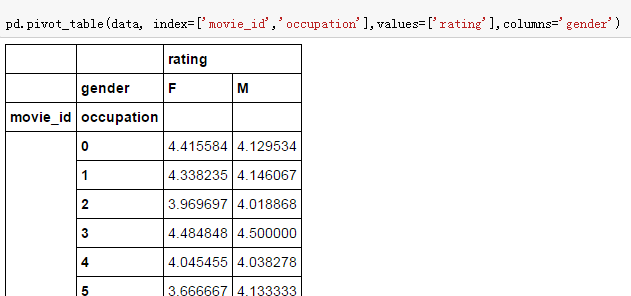
可以看出和value的区别了吗?colume的值作为列名了。
之后我们要drop掉NAN的数据,
mean_ratings=mean_ratings.dropna(axis=0)
mean_ratings其中官方dropna函数为DataFrame.dropna(axis=0, how=’any’, thresh=None, subset=None, inplace=False),其中axis : {0 or ‘index’, 1 or ‘columns’}, or tuple/list thereof
Pass tuple or list to drop on multiple axes,即axis=0表示删除行,axis=1表示删除列。
当然,也可以通过fillna将缺失值填充为所需要的。
之后我打算过滤掉评论不足250条的记录,其中size()得到含有各个电影分组大小的serise对象。
ratings_by_title=data.groupby('title').size()
type(ratings_by_title)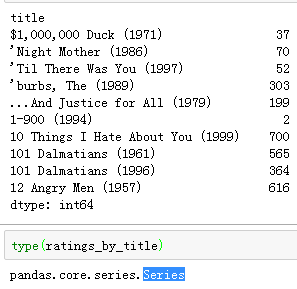
active_titles=ratings_by_title.index[ratings_by_title >= 250]
active_titles得到的active_titles 是索引:

然后可以在mean_ratings中选择我们所需要的行了
mean_ratings.ix[active_titles][:10]之后可以对female的评价执行降序排列
top_female_ratings=mean_ratings.sort_values(by='F',ascending=False)为了观察男女差别最大的电影,可以加一列diff
mean_ratings['diff']=mean_ratings['M']-mean_ratings['F']对diff进行排序
sorted_by_diff=mean_ratings.sort_values(by='diff')
男同志喜爱的电影
sorted_by_diff[::-1][:10][::-1] 表示取反
回到小费数据集
tips=pd.read_csv('C:\\Users\\ecaoyng\\Desktop\\work space\\Python\\py_for_analysis_code\\pydata-book-master\\ch08\\tips.csv')
tips[:5]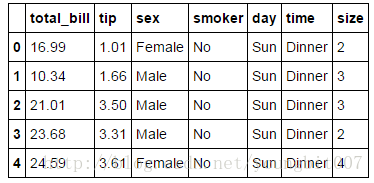
tips.pivot_table(index=['sex','smoker'])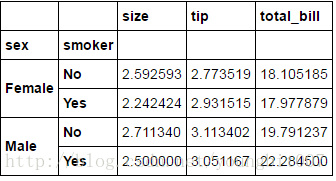
tips['tip_pct']=tips['tip']/tips['total_bill']
tips[:6]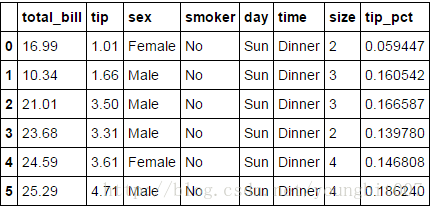
tips.pivot_table(['tip_pct','size'], index=['sex','day'],columns='smoker')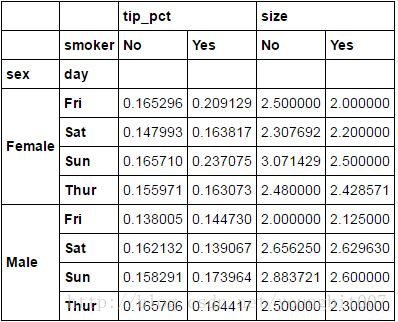
小技巧,先画出正题框架比如 columns 是列索引名, index是行索引名等

tips.pivot_table(['tip_pct','size'], index=['sex','day'],columns='smoker',margins=True)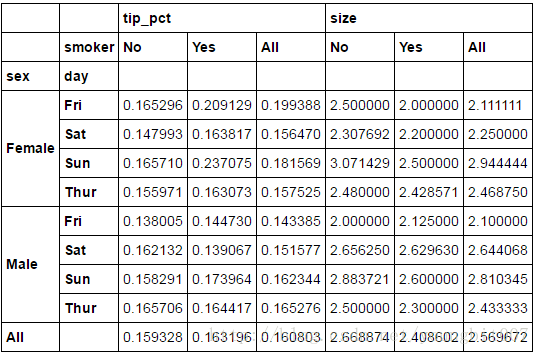
tips.pivot_table(['tip_pct'], index=['sex','smoker'],columns='day',margins=True,aggfunc=len)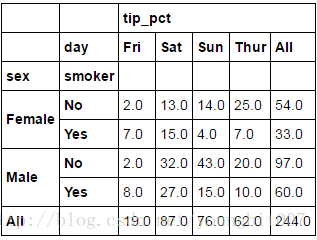















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









