







 本文介绍了SeoulNationalUniversity的Tesseract和GeorgiaInstituteofTechnology的GraphPIM两种针对图计算的内存计算架构。Tesseract通过重新集成逻辑和存储单元,实现87%的能耗节约;GraphPIM则提出将原子操作移至内存端,通过硬件支持和改进的接口设计,实现2.4倍性能提升和37%的能耗节省。
本文介绍了SeoulNationalUniversity的Tesseract和GeorgiaInstituteofTechnology的GraphPIM两种针对图计算的内存计算架构。Tesseract通过重新集成逻辑和存储单元,实现87%的能耗节约;GraphPIM则提出将原子操作移至内存端,通过硬件支持和改进的接口设计,实现2.4倍性能提升和37%的能耗节省。
针对图计算的近数据计算架构的代表性工作有: Seoul National University的 Tesseract和 Georgia Institute of Technology 的 GraphPIM,具体如下。
1 Tesseract
Tesseract是一个针对图计算的可编程的内存计算系统架构,它综合了图计算的特点,重新考虑了逻辑单元和存储单元的集成方式。图21是Tesseract的系统结构,左边是一个图计算在互联的 NDC cube中执行的实例,中间是一个NDC cube内部的连接结构,右边是一个拱内部的逻辑层结构。
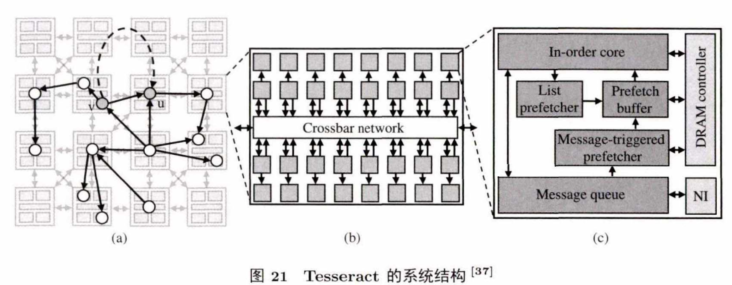
Tesseract逻辑层使用了顺序执行的计算核。Tesseract还使用了可以隐藏远程访问延迟的消息传递机制,以及为图计算定制的预取硬件,和一系列支持这些操作的上层接口。
实验显示,与传统的系统相比,Tesseract能取得87%的能耗节约。
2 GraphPIM
GraphPIMl38l 是一个针对图计算的,基 于 商 用 HMC2.0的近数据计算完整解决方案. GraphPIM主要解决利用近数据计算运行图计算的两大挑战:
(1)应该把图计算应用的哪些部分放到NDC cube中执行;
(2)如何把部分计算放到NDC cu b e 中执行,即如何提供中央处理器和近数据计算处理器的
接口。
GmphPIM发现,在图计算中,原子操作是损害性能的主要原因,因此应该把原子操作放到内
存端,避免不规则的数据访问带来的大通信开销. GraphPIM 使用现有的中央处理器指令,把中央处理器端的原子操作指令映射到近数据处理端,并使用无缓存的配置.在GmphPIM 架构下,上层应用程序员无需额外的工作,现有的指令集结构也不需要改动,就可以在图计算的负载中使用近数据计算。
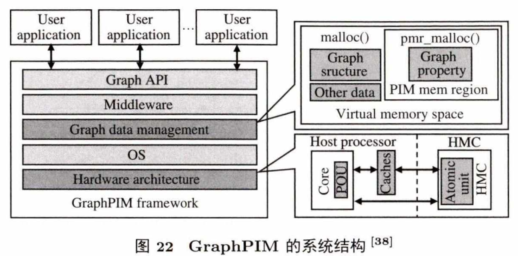
图22 是 GraphPIM 的系统结构, GraphPIM 在图数据管理和硬件支持方面做了改动.在虚拟地址空间中,GraphPIM 使用传统系统的指令绕过缓存来分配图数据;在硬件端,GraphPIM 在中央处理器上加了一个POU (PIM offloading unit) 用来决定哪些操作放到NDC cu b e中执行。此外,GraphPIM充分分析了图计算应用特征,判断出哪些部分放到近数据处理端做会有性能提升。
实验显示,GmphPIM与传统用HMC2.0当做主存的冯.诺依曼系统结构相比,有2.4倍的性能提升和37%的能耗节约。
参考文献
毛海宇,舒继武,李飞,等. 内存计算研究进展. 中国科学:信息科学,2021, 51: 173-206, doi: 10.1360/SSI-2020-0037 M ao H Y, Shu J W , Li F , et al. D evelopm ent of processing-in-m em ory (in C hinese). Sci Sin Inform , 2021, 51: 173-206, doi: 10.1360/SSI-2020-0037




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











