







·
整体架构
本产品是一套自动化对流量渠道进行舆论采集舆论分析和评论生成发布的流程,目前涉及采集的流量渠道主要有小红书及抖音,后续将根据用户需求增加开发其他流量渠道。
- 分批量和实时两条线。
- 批量线:
- 1、负责批量采集包括小红书文案内容、抖音视频内容、小红书及抖音评论内容,
- 2、基于采集到的内容数据,进行舆论分析,包括正负向情感分析、热门观点提取;进而针对热门观点,进行评论内容的生成。
- 实时线:
- 1、负责实时采集包括小红书文案内容、抖音视频内容、小红书及抖音评论内容,
- 2、基于采集到的内容数据,实时进行评论内容的生成和发布。
- 批量线:

批量采集及舆论分析
模块一 批量采集
该模块使用的是开源RPA工具tagUI,自主开发完成针对指定搜索关键词进行小红书文案、抖音视频文案以及相关评论的采集。
执行xhsDACQ.py及dyDACQ.py完成数据采集工作,生成相应的csv结果文件。
小红书内容采集
运行xhsDACQ.py脚本,指定以下入参:
| 入参 | 备注 |
|---|---|
| 搜索关键词 | 以|区分不同的关键词,如智己|LS7 |
| 筛选条件 | 以|区分排序和类型,排序参数可为空即按照默认排序、最新、最热;类型参数为空即默认全部、图文、视频。 |
| 采集内容类型 | 1、note;2、comment;3、note&comment |
| 采集条数上限 | 笔记条数采集上限 |
| 每条笔记采集的评论数 | 当采集内容类型=1时,为空 |
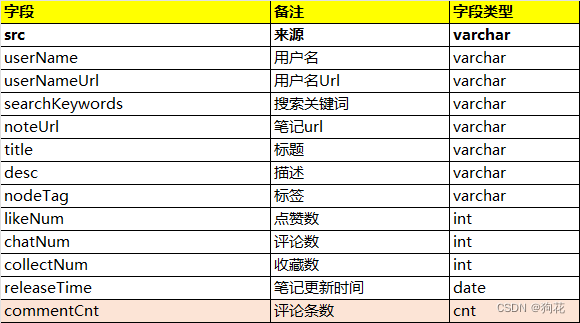
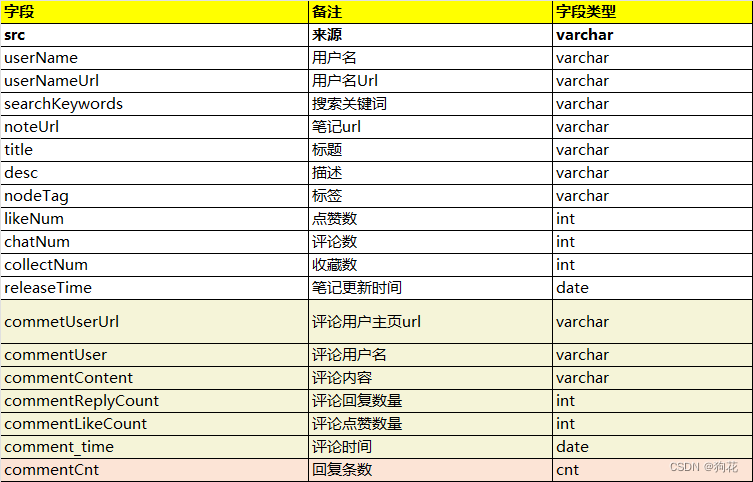
根据用户采集内容类型 ,输出采集的笔记内容和评论内容,具体采集字段如下:
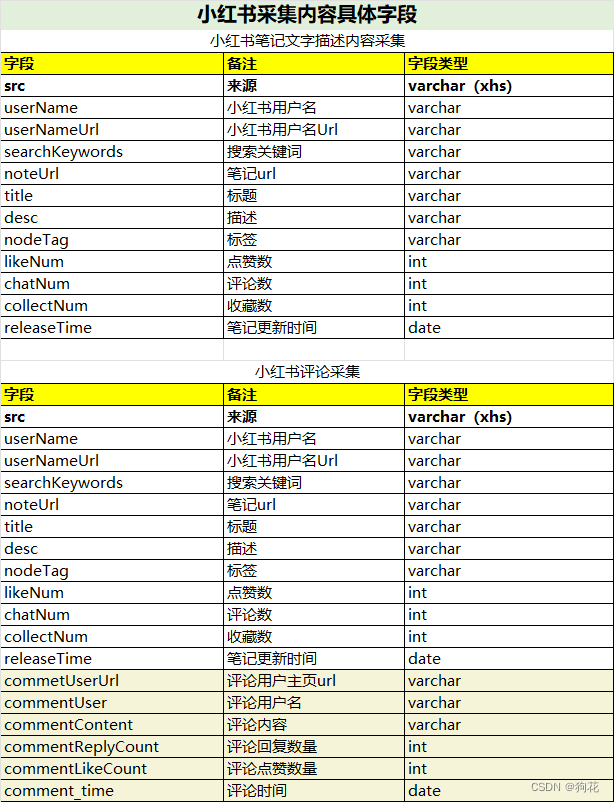
举例1:python xhsDACQ.py 智己|LS7 最新|图文 1 100——> 将获得以“智己 LS7”为关键词搜索的最新图文笔记100篇对应的文字描述内容
举例2:python xhsDACQ.py 智己|LS7 | 3 100 5——> 将获得以“智己 LS7”为关键词搜索的按照默认排序的前100篇笔记对应的文字描述内容及每篇笔记的前5条评论内容。
抖音内容采集
运行dyDACQ.py脚本时,需指定以下入参:
| 入参 | 备注 |
|---|---|
| 搜索关键词 | 以|区分不同的关键词,如智己|LS7 |
| 筛选条件 | 以|区分排序和发布时间,排序参数可为空即按照综合排序、最新、最多点赞;发布时间参数为空即不限、一天内、一周内、半年内。 |
| 采集内容类型 | 1、vedio;2、comment;3、vedio&comment |
| 采集条数上限 | 视频条数采集上限 |
| 每条视频采集的评论数 | 当采集内容类型=1时,为空 |
根据用户采集内容类型 ,输出采集的笔记内容和评论内容,具体采集字段如下:
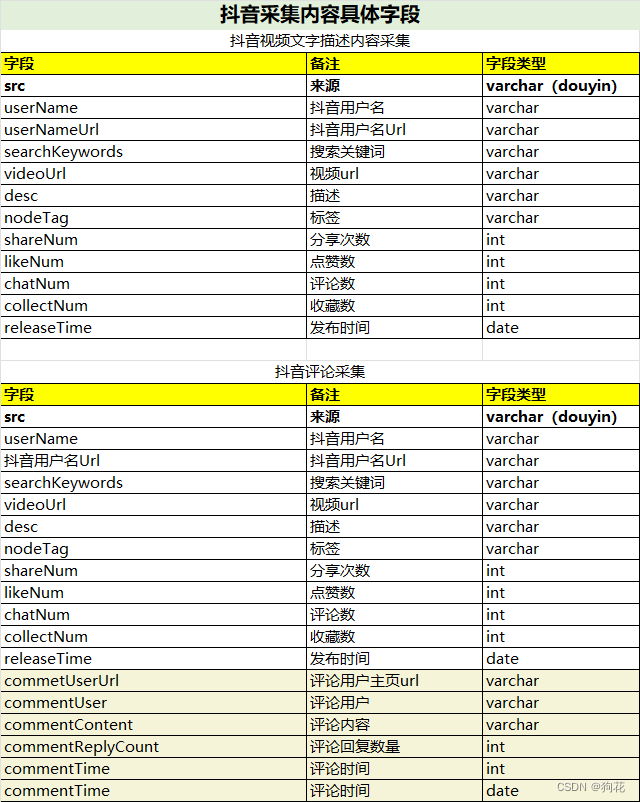
举例1:python dyDACQ.py 智己|LS7 最新|一天内 1 100——> 将获得以“智己 LS7”为关键词搜索一天内最新100篇视频对应的文字描述内容
举例2:python dyDACQ.py 智己|LS7 |半年内 3 100 5——> 将获得以“智己 LS7”为关键词搜索半年内发布的按照默认综合排序的前100篇视频对应的文字描述内容及每篇笔记的前5条评论内容。
模块二 舆论分析
该模块基于模块一采集到的内容数据进行舆论分析,包括正负向情感分析、热门观点提取
执行commentAnalysis脚本完成数据分析工作,会获得comment_analysis_rst.csv
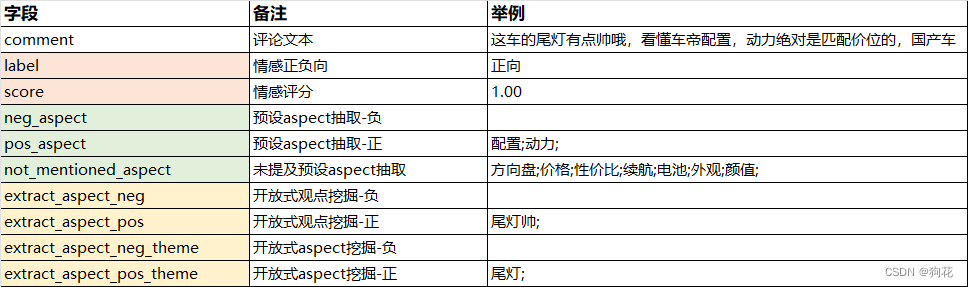
模块三 内容生成
-
评论生成(commentGenerate):该模块基于模块二的舆论分析结果comment_analysis_rst.csv进行评论生成
执行commentGenerate脚本,进行回复内容的生成,会获得comment_generate_rst.csv -
回复生成(replyGenerate):该模块基于模块二的舆论分析结果comment_analysis_rst.csv进行评论生成
执行replyGenerate脚本,进行回复内容的生成,会获得reply_generate_rst.csv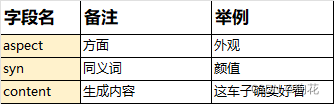
实时采集及内容发布
调用 xhsRealTimeRpaProcess.py,dyRealTimeRpaProcess.py,修改config文件,做相应的设置后,运行程序完成实时采集及内容发布。可在 xhsRealTimeRpaProcess_log.csv, xhsRealTimeRpaProcess_log.csv 中 监控跑批情况
{
"xhs":{
"keywords": "智己|LS7", //搜索关键词
"filter": "最新|全部", //排序方式
"limitnum":"100",//采集条数上限
"process: {
"condition":{ //筛选满足以下条件的笔记进行评论及回复处理,以下各条件是并且关系
"likeNum":5 //点赞数大于等于5
"chatNum":3 //评论回复交互数大于等于3
"collectNum":0 //评论回复交互数大于等于0
},
"commentcnt":1, //对笔记进行评论,条数为1
"commentsource":"comment_generate_rst.csv" //绝对路径
"reply":{ //对评论进行回复处理
"orderid":"[1,2,3]" //前3个评论进行回复,举例[1,3]对第1个和第3个评论进行回复
"contentuinique":"on" //对同一篇笔记下的多条评论进行逐一回复时,内容需要排重,不能满足排重该条评论不予回复;off为不需要排重
"source":"comment_generate_rst.csv" //绝对路径
},
},
"dy":{
"keywords": "智己|LS7", //搜索关键词
"filter": "最新|一周内", //排序方式
"limitnum":"100",//采集条数上限
"process: {
"condition":{ //筛选满足以下条件的视频进行评论及回复处理,以下各条件是并且关系
"likeNum":5 //点赞数大于等于5
"chatNum":3 //评论回复交互数大于等于3
"collectNum":0 //评论回复交互数大于等于0
},
"commentcnt":1, //对视频进行评论,条数为1
"commentsource":"comment_generate_rst.csv" //绝对路径
"reply":{ //对评论进行回复处理
"orderid":"[1,2,3]" //前3个评论进行回复,举例[1,3]对第1个和第3个评论进行回复
"contentuinique":"on" //对同一篇笔记下的多条评论进行逐一回复时,内容需要排重,不能满足排重该条评论不予回复;off为不需要排重
"source":"comment_generate_rst.csv" //绝对路径
},
}
}
模块四 内容发布
- 实时获取评论内容,调用getCommentContent.py
getCommentContent.py:随机发布comment_generate_rst.csv中的一条
xhsCPUB.py 小红书发布评论
dyCPUB.py 抖音发布评论
入参:
出参
| 参数 | 备注 |
|---|---|
| commnetContentGenerated | 生成评论内容 |
- 实时获取回复内容,调用getReplyContent.py
getReplyContent.py:评论内容关键词匹配reply_generate_rst.csv中aspect和syn,击中即随机发布对应的content中的一条。
xhsRPUB.py 小红书发布回复
dyRPUB.py 抖音发布回复
出参
| 参数 | 备注 |
|---|---|
| replyContentGenerated | 生成回复内容 |


















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









