







Google, if you’re reading this, it’s too late.
谷歌,如果你正在读这篇文章,那就太晚了。
Ok. Cracks knuckles. Let’s get right to it. Internal documentation for Google Search’s Content Warehouse API has leaked. Google’s internal microservices appear to mirror what Google Cloud Platform offers and the internal version of documentation for the deprecated Document AI Warehouse was accidentally published publicly to a code repository for the client library. The documentation for this code was also captured by an external automated documentation service.
好的。掰响手指,扭扭头。让我们开始吧。 Google 搜索内容仓库 API 的内部文档已泄露。谷歌的内部微服务似乎反映了谷歌云平台提供的内容,并且已弃用的 Document AI Warehouse 的内部文档版本意外地公开发布到客户端库的代码存储库中。该代码的文档也由外部自动文档服务捕获。
Based on the change history, this code repository mistake was fixed on May 7th, but the automated documentation is still live. In efforts to limit potential liability, I won’t link to it here, but because all the code in that repository was published under the Apache 2.0 license, anyone that came across it was granted a broad set of rights, including the ability to use, modify, and distribute it anyway.
根据更改历史记录,此代码存储库错误已于 5 月 7 日修复,但自动化文档仍然有效。为了限制潜在的责任,我不会在这里链接到它,但因为该存储库中的所有代码都是在 Apache 2.0 许可证下发布的,所以遇到它的任何人都被授予了广泛的权利,包括使用的能力、修改并分发它。
I have reviewed the API reference docs and contextualized them with some other previous Google leaks and the DOJ antitrust testimony. I’m combining that with the extensive patent and whitepaper research done for my upcoming book, The Science of SEO. While there is no detail about Google’s scoring functions in the documentation I’ve reviewed, there is a wealth of information about data stored for content, links, and user interactions. There are also varying degrees of descriptions (ranging from disappointingly sparse to surprisingly revealing) of the features being manipulated and stored.
我已经审阅了 API 参考文档,并将其与之前的其他一些 Google 泄密事件和 DOJ 反垄断证词结合起来。我将其与我即将出版的书《SEO 科学》中所做的广泛专利和白皮书研究结合起来。虽然我查看的文档中没有有关 Google 评分功能的详细信息,但有大量有关为内容、链接和用户交互存储的数据的信息。对被操纵和存储的特征也有不同程度的描述(从令人失望的稀疏到令人惊讶的揭示)。
You’d be tempted to broadly call these “ranking factors,” but that would be imprecise. Many, even most, of them are ranking factors, but many are not. What I’ll do here is contextualize some of the most interesting ranking systems and features (at least, those I was able to find in the first few hours of reviewing this massive leak) based on my extensive research and things that Google has told/lied to us about over the years.
您可能会想将这些广泛地称为“排名因素”,但这并不精确。其中许多,甚至大多数是排名因素,但也有许多不是。我在这里要做的是根据我的广泛研究和谷歌告诉/的事情,将一些最有趣的排名系统和功能(至少是我在审查这个大规模泄漏的最初几个小时内找到的那些)背景化多年来对我们撒谎。
“Lied” is harsh, but it’s the only accurate word to use here. While I don’t necessarily fault Google’s public representatives for protecting their proprietary information, I do take issue with their efforts to actively discredit people in the marketing, tech, and journalism worlds who have presented reproducible discoveries. My advice to future Googlers speaking on these topics: Sometimes it’s better to simply say “we can’t talk about that.” Your credibility matters, and when leaks like this and testimony like the DOJ trial come out, it becomes impossible to trust your future statements.
“谎言”很刺耳,但这是这里使用的唯一准确的词。虽然我不一定责怪谷歌的公众代表保护他们的专有信息,但我确实对他们积极抹黑营销、技术和新闻界那些提出了可复制发现的人的行为表示异议。我对未来谈论这些话题的谷歌人的建议是:有时最好简单地说“我们不能谈论这个”。你的可信度很重要,当像这样的泄密事件和像司法部审判这样的证词出现时,你就不可能相信你未来的陈述。
THE CAVEATS 注意事项
I think we all know people will work to discredit my findings and analysis from this leak. Some will question why it matters and say “but we already knew that.” So, let’s get the caveats out of the way before we get to the good stuff.
我想我们都知道人们会努力抹黑我从这次泄密中得到的发现和分析。有些人会质疑为什么它很重要并说“但我们已经知道了”。所以,在我们开始讨论好东西之前,让我们先把这些注意事项先排除掉。
- Limited Time and Context – With the holiday weekend, I’ve only been able to spend about 12 hours or so in deep concentration on all this. I’m incredibly thankful to some anonymous parties that were super helpful in sharing their insights with me to help me get up to speed quickly. Also, similar to the Yandex leak I covered last year, I do not have a complete picture. Where we had source code to parse through and none of the thinking behind it for Yandex, in this case we have some of the thinking behind thousands of features and modules, but no source code. You’ll have to forgive me for sharing this in a less structured way than I will in a few weeks after I’ve sat with the material longer.
有限的时间和背景——在假期周末,我只能花大约 12 个小时左右的时间来深度专注于这一切。我非常感谢一些匿名人士,他们与我分享他们的见解,帮助我快速上手,非常有帮助。另外,与我去年报道的 Yandex 泄密事件类似,我没有完整的图片。我们有源代码可供解析,但没有任何 Yandex 背后的想法,在这种情况下,我们有数千个功能和模块背后的一些想法,但没有源代码。你必须原谅我以一种不太结构化的方式分享这些内容,而几周后我会更长时间地阅读这些材料。 - No Scoring Functions – We do not know how features are weighted in the various downstream scoring functions. We don’t know if everything available is being used. We do know some features are deprecated. Unless explicitly indicated, we don’t know how things are being used. We don’t know where everything happens in the pipeline. We have a series of named ranking systems that loosely align with how Google has explained them, how SEOs have observed rankings in the wild, and how patent applications and IR literature explains. Ultimately, thanks to this leak, we now have a clearer picture of what is being considered that can inform what we focus on vs. ignore in SEO moving forward.
无评分函数——我们不知道如何在各种下游评分函数中对特征进行加权。我们不知道是否所有可用的东西都被使用了。 我们确实知道某些功能已被弃用。除非明确指出,否则我们不知道东西是如何使用的。我们不知道管道中的所有事情都发生在哪里。我们有一系列命名的排名系统,这些系统与 Google 的解释方式、SEO 如何观察野外排名以及专利申请和 IR 文献的解释方式大致一致。最终,由于这次泄密,我们现在对正在考虑的内容有了更清晰的了解,可以告诉我们在 SEO 中关注和忽略的内容。 - Likely the First of Several Posts – This post will be my initial stab of what I’ve reviewed. I may publish subsequent posts as I continue to dig into the details. I suspect this article will lead to the SEO community racing to parse through these docs and we will, collectively, be discovering and recontextualizing things for months to come.
可能是几篇文章中的第一篇——这篇文章将是我对我所评论内容的初步尝试。随着我继续深入研究细节,我可能会发布后续帖子。我怀疑这篇文章将导致 SEO 社区竞相解析这些文档,我们将在未来几个月共同发现和重新构建事物。 - This Appears to Be Current Information – As best I can tell, this leak represents the current, active architecture of Google Search Content Storage as of March of 2024. (Cue a Google PR person saying I’m wrong. Actually let’s just skip the song and dance, y’all). Based on the commit history, the related code was pushed on on Mar 27, 2024 and not removed until May 7, 2024.
这似乎是最新信息——据我所知,这次泄露代表了截至 2024 年 3 月 Google 搜索内容存储当前活跃的架构。(一位 Google 公关人员说我错了。实际上让我们跳过这首歌还有跳舞,你们大家)。根据提交历史,相关代码于2024年3月27日推送,直到2024年5月7日才被删除。

- Correlation is not causation – Ok, this one doesn’t really apply here, but I just wanted to make sure I covered all the bases.
相关性不是因果关系——好吧,这个问题在这里并不适用,但我只是想确保我涵盖了所有基础。
THERE ARE 14K RANKING FEATURES AND MORE IN THE DOCS
文档中有 14K 排名功能及更多内容
There are 2,596 modules represented in the API documentation with 14,014 attributes (features) that look like this:
API 文档中有 2,596 个模块,具有 14,014 个属性(功能),如下所示:

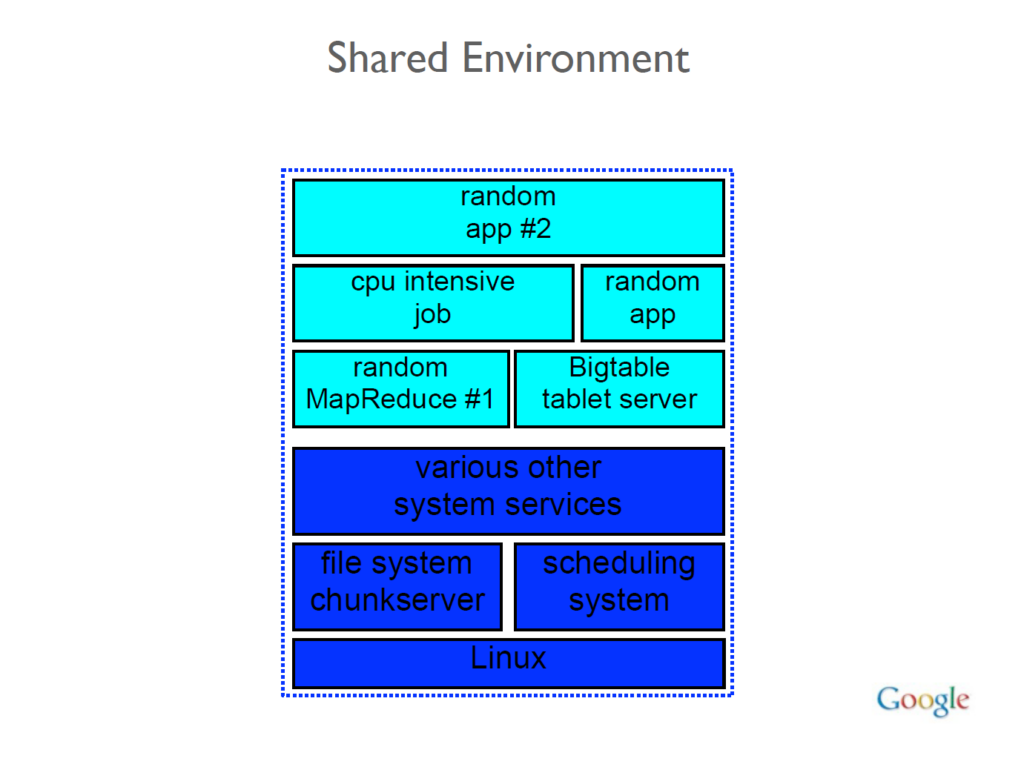
The modules are related to components of YouTube, Assistant, Books, video search, links, web documents, crawl infrastructure, an internal calendar system, and the People API. Just like Yandex, Google’s systems operate on a monolithic repository (or “monorepo”) and the machines operate in a shared environment. This means that all the code is stored in one place and any machine on the network can be a part of any of Google’s systems.
这些模块与 YouTube、助手、书籍、视频搜索、链接、网络文档、爬行基础设施、内部日历系统和 People API 的组件相关。就像 Yandex 一样,Google 的系统在单一存储库(或“monorepo”)上运行,并且机器在共享环境中运行。这意味着所有代码都存储在一个地方,网络上的任何机器都可以成为任何 Google 系统的一部分。
The leaked documentation outlines each module of the API and breaks them down into summaries, types, functions, and attributes. Most of what we’re looking at are the property definitions for various protocol buffers (or protobufs) that get accessed across the ranking systems to generate SERPs (Search Engine Result Pages – what Google shows searchers after they perform a query).
泄露的文档概述了 API 的每个模块,并将它们分解为摘要、类型、函数和属性。我们所关注的大部分内容是各种协议缓冲区(或 protobuf)的属性定义,这些协议缓冲区可跨排名系统访问以生成 SERP(搜索引擎结果页面 - Google 在搜索者执行查询后向其显示的内容)。
Unfortunately, many of the summaries reference Go links, which are URLs on Google’s corporate intranet, that offer additional details for different aspects of the system. Without the right Google credentials to login and view these pages (which would almost certainly require being a current Googler on the Search team), we are left to our own devices to interpret.
不幸的是,许多摘要引用了 Go 链接,这些链接是 Google 公司内部网上的 URL,提供了系统不同方面的更多详细信息。如果没有正确的 Google 凭据来登录和查看这些页面(这几乎肯定需要成为搜索团队中的现任 Google 员工),我们就只能用自己的设备来解释。
THE API DOCS REVEAL SOME NOTABLE GOOGLE LIES
API 文档揭露了一些值得注意的 GOOGLE 谎言
Google spokespeople have gone out their way to misdirect and mislead us on a variety of aspects of how their systems operate in an effort to control how we behave as SEOs. I won’t go as far as calling it “social engineering” because of the loaded history of that term. Let’s instead go with… “gaslighting.” Google’s public statements probably aren’t intentional efforts to lie, but rather to deceive potential spammers (and many legitimate SEOs as well) to throw us off the scent of how to impact search results.
Google 发言人在其系统运作方式的各个方面不遗余力地误导我们,以控制我们作为 SEO 的行为方式。我不会将其称为“社会工程”,因为该术语的历史悠久。让我们来看看……“煤气灯操纵”。谷歌的公开声明可能并不是故意撒谎,而是为了欺骗潜在的垃圾邮件发送者(以及许多合法的搜索引擎优化),让我们不知道如何影响搜索结果。
Below, I present assertions from Google employees alongside facts from the documentation with limited commentary so you can judge for yourself.
下面,我将介绍 Google 员工的断言以及文档中的事实和有限的评论,以便您可以自行判断。
“We Don’t Have Anything Like Domain Authority”
“我们没有域名权限之类的东西”
Google spokespeople have said numerous times that they don’t use “domain authority.” I’ve always assumed that this was a lie by omission and obfuscation.
谷歌发言人多次表示,他们不使用“域权限”。我一直认为这是遗漏和混淆的谎言。
By saying they don’t use domain authority, they could be saying they specifically don’t use Moz’s metric called “Domain Authority” (obviously ). They could also be saying they don’t measure the authority or importance for a specific subject matter (or domain) as it relates to a website. This confusion-by-way-of-semantics allows them to never directly answer the question as to whether they calculate or use sitewide authority metrics.
通过说他们不使用域权限,他们可能是说他们特别不使用 Moz 称为“域权限”的指标(显然是 )。他们也可能会说,他们不会衡量与网站相关的特定主题(或领域)的权威或重要性。这种语义上的混淆使他们永远无法直接回答有关是否计算或使用站点范围权威指标的问题。
Gary Ilyes, an analyst on the Google Search Team who focuses on publishing information to help website creators, has repeated this assertion numerous times.
加里·伊利斯 (Gary Ilyes) 是 Google 搜索团队的分析师,专注于发布信息以帮助网站创建者,他多次重复了这一说法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 575
575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











