









Spark广播变量之大表left join小表时如何进行优化以及小表的正确位置放置,带着这个目标我们一探究竟。
项目场景:
最近工作中遇到一个场景:
有一个超大表3.5T和一个小表963K
需要做关联查询,使用到广播变量,广播小表数据,left join后接小表。
领提出优化,说小表在左left join可以执行效率,我提出了反对意见,为了验证领导所说的对与错,专门进行了测试
问题描述:
首先使用一个300M的表和10k的表进行测试, left join 将小表在右进行广播
sparkSQL-执行计划如下:
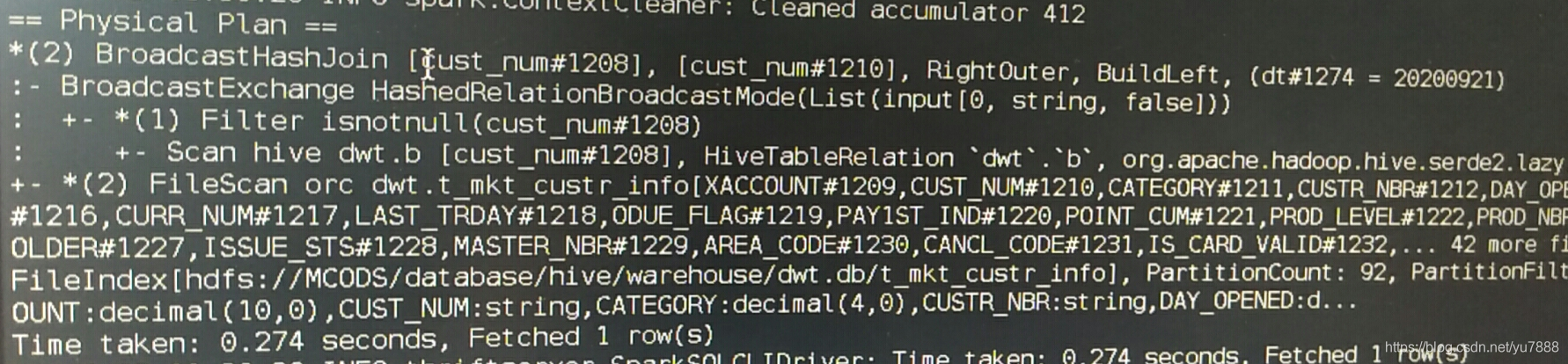
可以看出是BroadcastHashJoin,
使用这个 Join 策略必须满足以下条件:
•小表的数据必须很小,可以通过 spark.sql.autoBroadcastJoinThreshold 参数来配置,默认是 10MB,如果你的内存比较大,可以将这个阈值适当加大;如果将 spark.sql.autoBroadcastJoinThreshold 参数设置为 -1,可以关闭 BHJ;
•只能用于等值 Join,不要求参与 Join 的 keys 可排序;
•除了 full outer joins ,支持所有的 Join 类型。
物理计划如下:

下面进行 left join,把小表放在左侧进行广播测试

执行计划是没有广播数据,而是进行了SortMergeJoin,也是对两张表参与 Join 的 Keys 使用相同的分区算法和分区数进行分区,目的就是保证相同的 Keys 都落到相同的分区里面,分区完之后再对每个分区按照参与 Join 的 Keys 进行排序,最后 Reduce 端获取两张表相同分区的数据进行 Merge Join
里面使用了 SortMergeJoin,物理计划如下

原因分析:
Broadcast Hash Join 的实现是将小表的数据广播(broadcast)到 Spark 所有的 Executor 端,这个广播过程和我们自己去广播数据没什么区别,先利用 collect 算子将小表的数据从 Executor 端拉到 Driver 端,然后在 Driver 端调用 sparkContext.broadcast 广播到所有 Executor 端;然后在 Executor 端这个广播出去的小表数据会和大表进行 Join 操作,这种 Join 策略避免了 Shuffle 操作。一般而言,使用left join时会将广播后的表放在右侧
















 684
684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











