







文章目录
( 自己的理解,如有理解有误的地方请谅解!!!)
我们常常会有一个疑惑,**人工智能(AI)、机器学习(ML)、深度学习(DL)、计算机视觉(CV)、自然语言(NLP)**之间到底是什么关系?
下面的图可以就是它们之间的一个关系:机器学习是实现人工智能的一种方法;深度学习是实现机器学习的一种方法;计算机视觉和自然语言处理是应用,人工智能、机器学习、深度学习都可以用来做计算机视觉和自然语言处理。
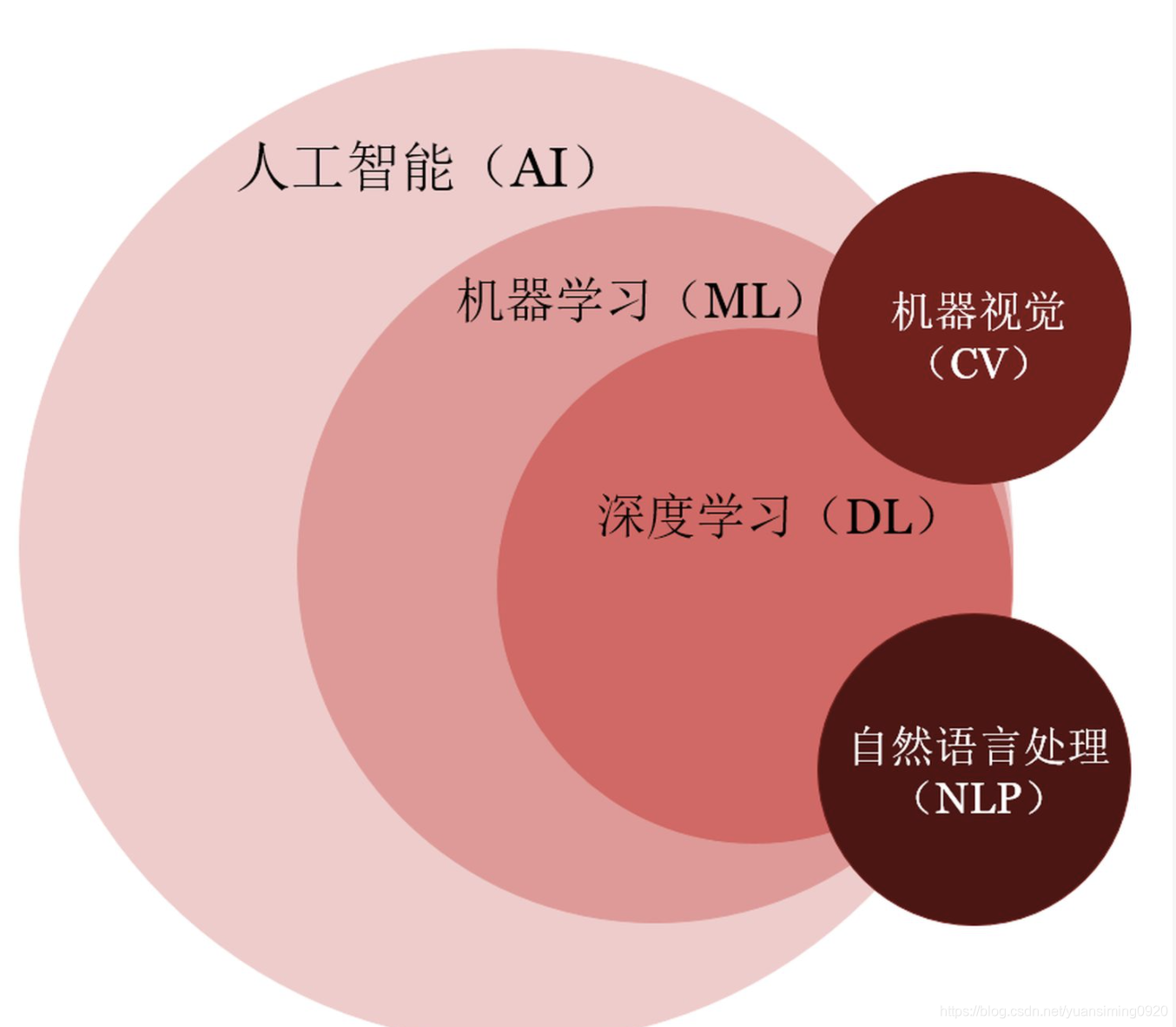
具体的关系如下:
1 Artificial Intelligence (AI,人工智能)

-
人工智能研究的一个主要目标是使机器能够胜任一些通常需要人类智能才能完成的复杂工作
-
研究范畴:自然语言处理,知识表现,智能搜索,推理,规划,机器学习,知识获取,组合调度问题,感知问题,模式识别,逻辑程序设计软计算,不精确和不确定的管理,人工生命,神经网络,复杂系统,遗传算法
-
实际应用:机器视觉,指纹识别,人脸识别,视网膜识别,虹膜识别,掌纹识别,专家系统,自动规划,智能搜索,定理证明,博弈,自动程序设计,智能控制,机器人学,语言和图像理解,遗传编程等
2 Machine Learning(ML,机器学习)
- 机器学习:是实现人工智能的一种方法

我们可以看到机器学习其实就是实现人工智能的一种方法,除了机器学习还有很多种方法都可以用来实现人工智能。
2.1 监督学习和无监督学习
- 基于学习方式的分类:监督学习、无监督学习、半监督学习、强化学习(增强学习)、集成学习和深度学习
下面来理解一下什么是监督学习和无监督学习:
- 有监督学习:
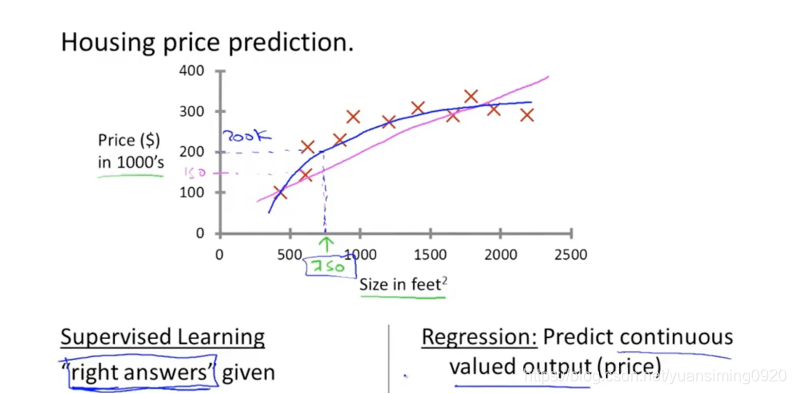
比如上图中的房价预测问题,横坐标表示房子的面积,纵坐标表示房价,红色的叉叉表示真实的房价(横坐标对应的真实房价)。我们在知道这些真实的房价的情况下,可以通过这些真实的数据来拟合出一个函数(可能是粉色的直线,也可能是蓝色的曲线)。根据这个函数,我们每次输如一个房屋面积(x),都可预测出一个对应的房价(y)。这种在已经给了正确的结果的情况下来进行学习的过程叫做监督学习。房屋预测问题也叫回归问题(预测出连续的值)。
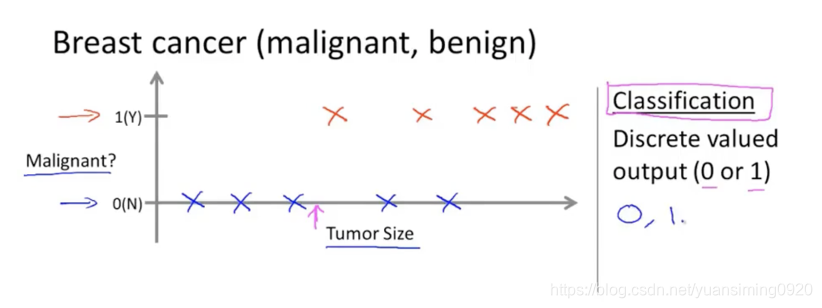
上边是乳腺癌预测,给了一部分知道结果的数据集(蓝色表示良性,红色表示恶性肿瘤)。通过对这些数据的学习,下次再输入一个肿瘤大小的时候,算法就可以正确预测出这个肿瘤术语良性还是恶性(0或者1),这种问题也叫做分类问题。下面的也叫分类问题。
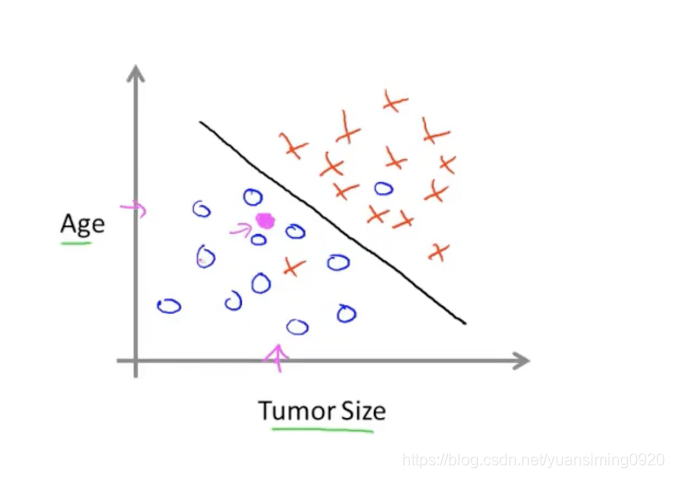
总结:监督学习就是在给了正确结果下来让算法进行学习的过程,最后根据学习的结果可以实现未知问题的预测。监督学习包括回归问题和分类问题。
- 无监督学习:

无监督学习:给了一堆数据,没有具体告诉这一堆数据的正确结果,让算法自己学习把这些数据分成一簇一簇的。又叫聚类问题。
2.2 监督学习的线性回归学习算法
下面用一个简单的线性回归学习算法例子,来理解机器学习的学习过程,并理解监督学习过程。其他的机器学习算法过程都类似于这个例子的过程,都是通过优化预测和真实的差(代价函数)来优化算法,大部分优化的过程都是使用的梯度下降(如果自己有别的优化方法也可以使用别的)。
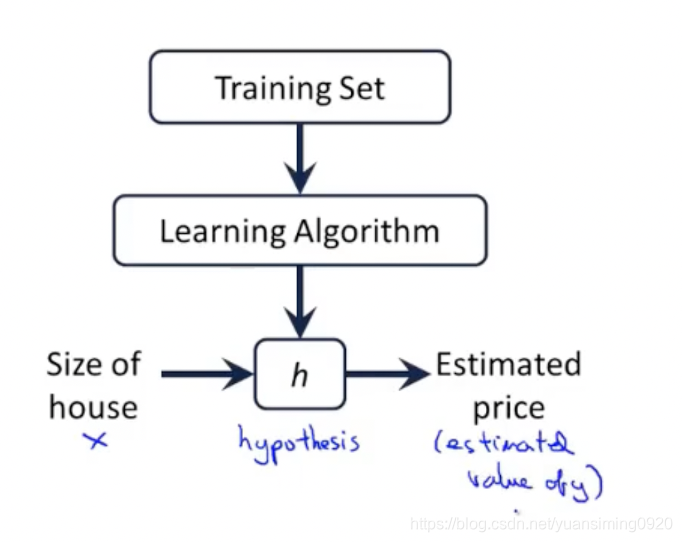
大致过程如上,训练集就是给的那些正确结果的数据,这些数据输入到学习算法中,学习算法的任务是要输出一个函数h(假设函数),当给这个函数输入房子的时候,它能输出房子要卖的价格。接下来就要考虑要选择什么函数来作为我们的假设函数h(这就是传统机器学习的魅力所在,要考经验来假设出相应的模型)。
房屋预测例子:
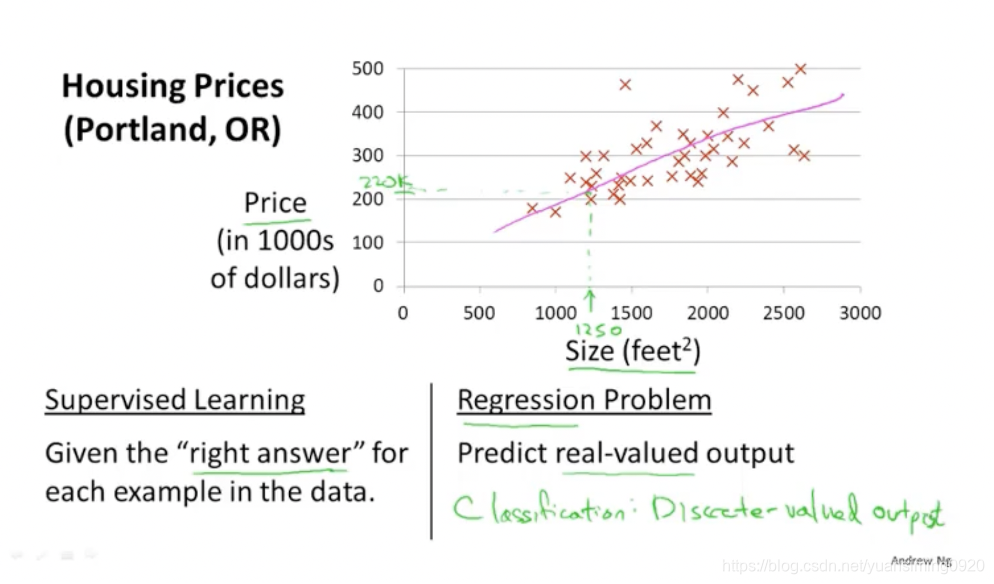

训练集:红色叉叉(正确结果的数据集)
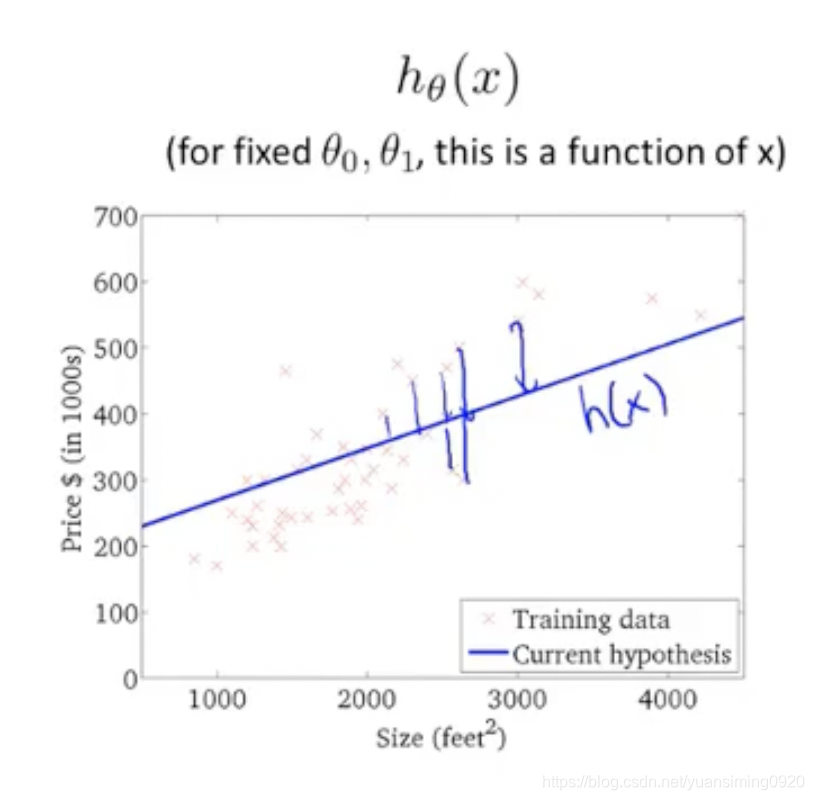
假设函数h(选择模型的过程):根据经验设假设h为一次函数
接下来的任务就是要选择h函数的两个参数,怎么选择最优的参数,这里就提到了代价函数(cost function),代价函数也就是预测和真实值之间差值平方的和,就是下图中蓝色线。因此问题就变成了找能使代价函数值最小的两个参数,即优化代价函数问题。

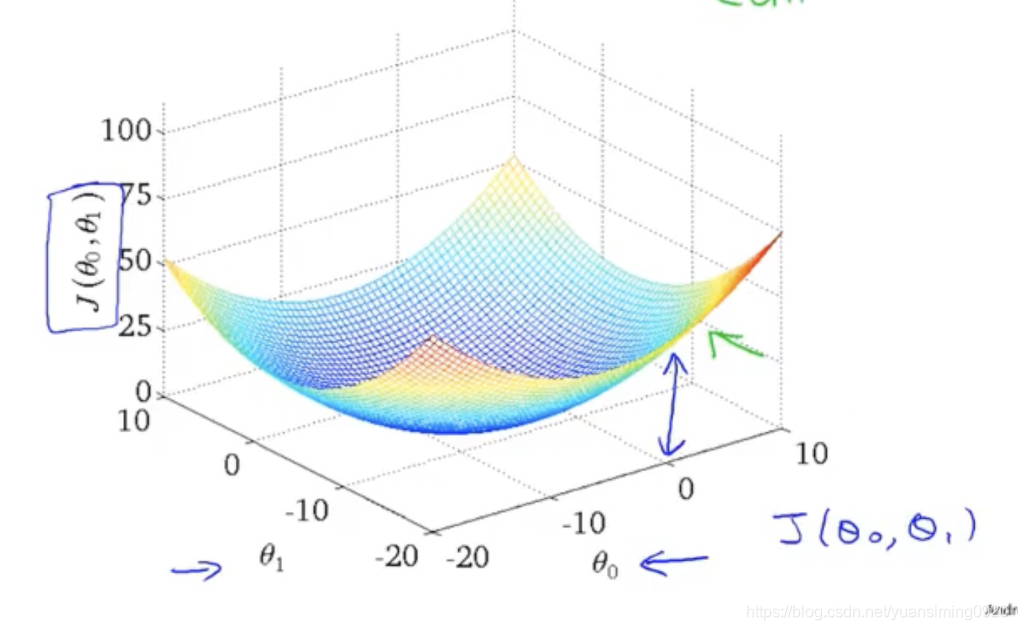
代价函数是通过梯度下降来进行优化的,梯度下降的优化如下(一般参数我们会随机初始化,在初始化的基础上更新参数):


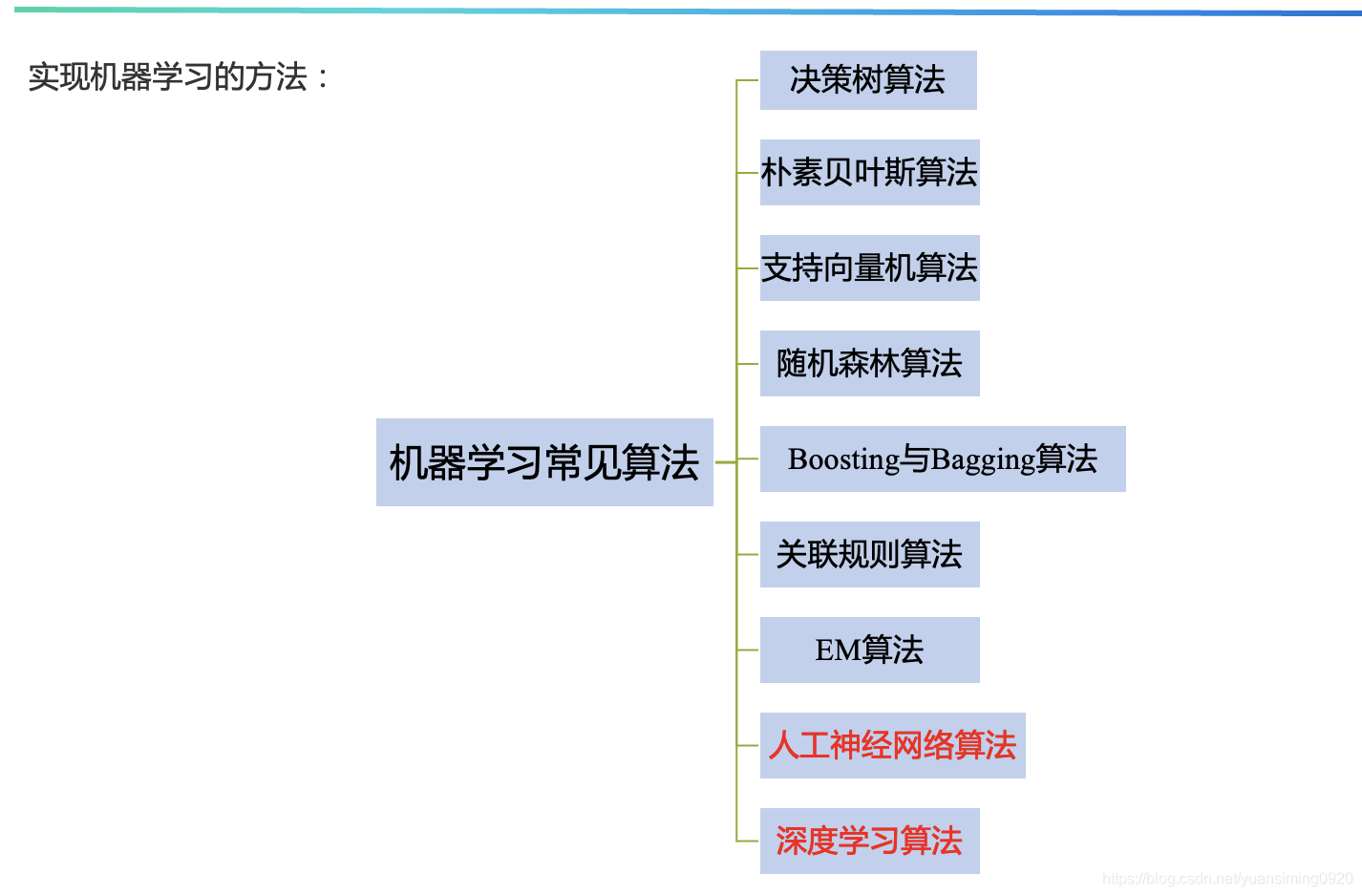
2.3 机器学习的常见算法
这些算法的学习(训练)过程都和2.2的学习过程类似。除了深度学习,其他的都称为传统机器学习。
2.4 人工神经网络
人工神经网络是机器学习中提的比较多的词,那下面就来了解一下什么是人工神经网络。
**人工神经网络:**对人脑神经元网络进行抽象获得的简单模型,是实现机器学习任务的一种方法。
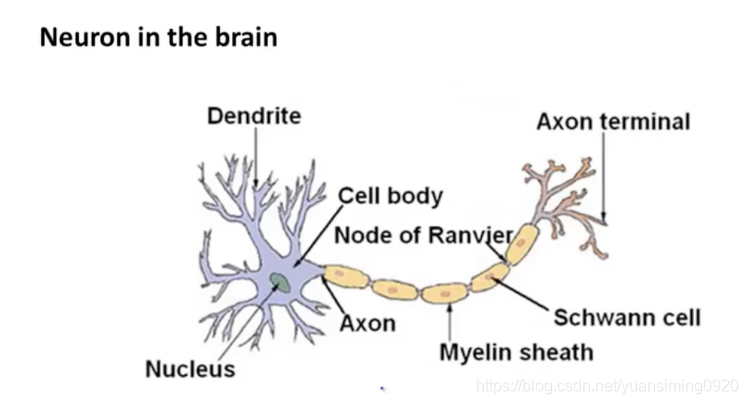
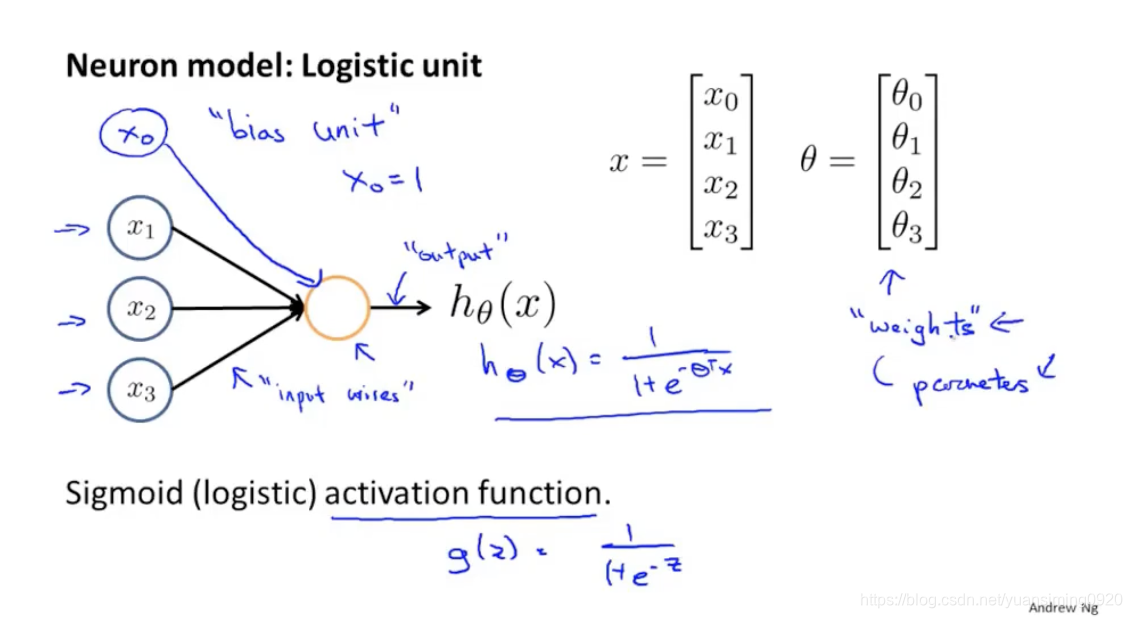
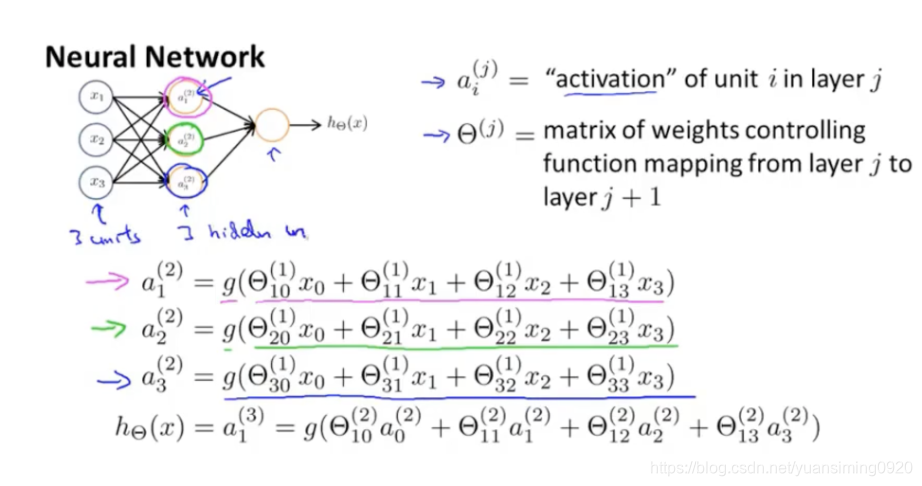
上图就是大脑的神经元(或者说神经网络)和最简单的人工神经网络的对比。人工神经网络的中的输入、黄圆圈、输出分别类似于大脑的神经元中的树突、细胞体和轴突。
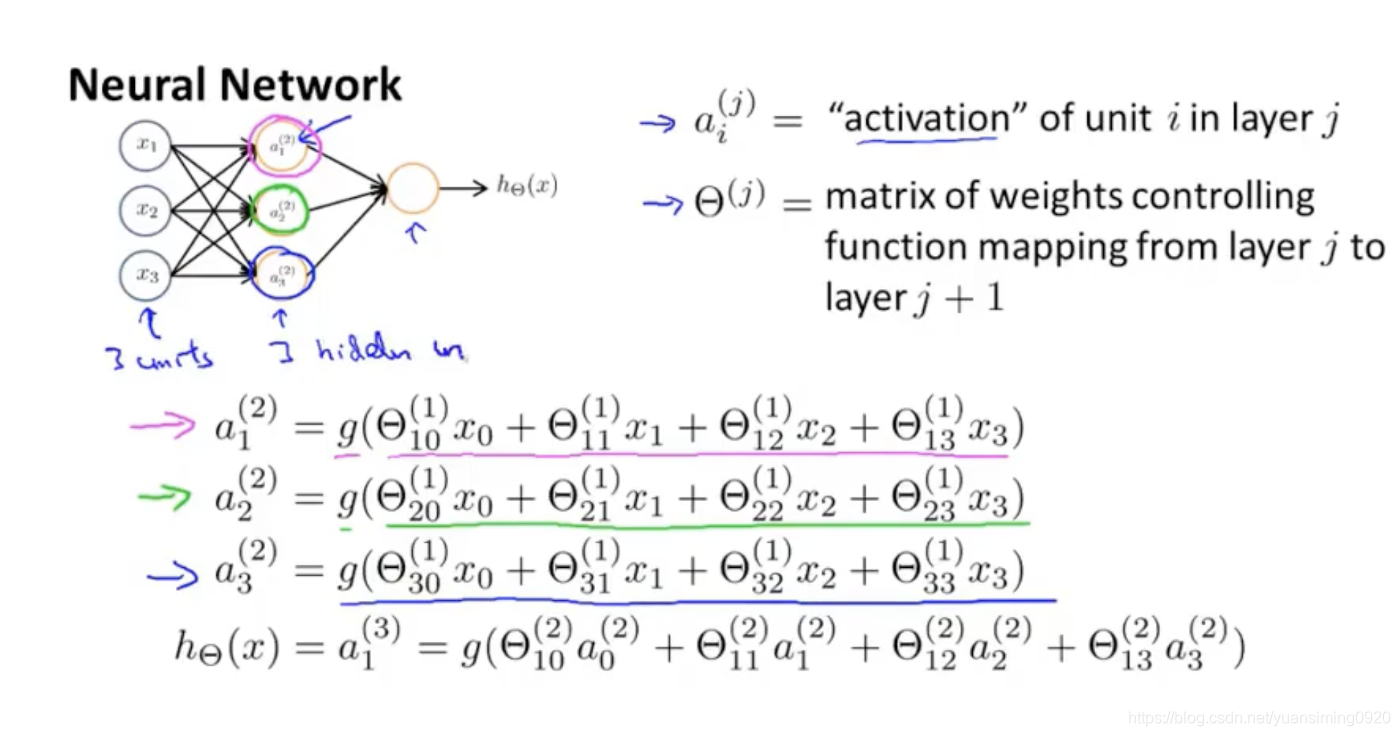

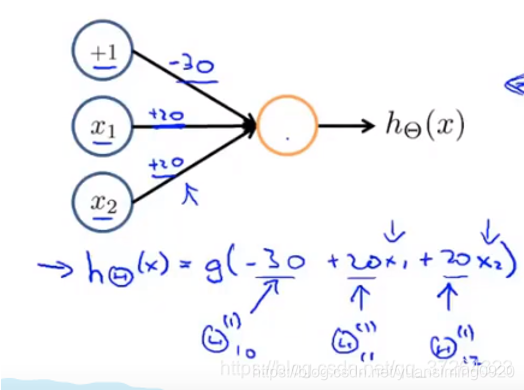
人工神经网络具体工作如上,g表示的是激活函数,为了实现非线性。每个黄圈圈的计算过程都是:每个输入乘以相应的权重参数(类似于线性回归中的两个参数,会自己初始化)的和,然后再通过激活函数得到激活值。
总结:神经网络的学习过程和线性回归算法过程类似,也会通过反向传播来更新参数
3 Deep Learning(DL,深度学习)
- 深度学习:实现机器学习的一种方法,本质上是深层的人工神经网络(机器学习中的人工神经网络层数都比较浅)
针对不同的学习任务,有不同的神经网络模型

4 Convolutional Neural Networks(CNN,卷积神经网络)
CNN:深度学习中极具代表性的结构之一,实现深度学习的方法之一。
下面使用边缘检测来理解卷积的过程:
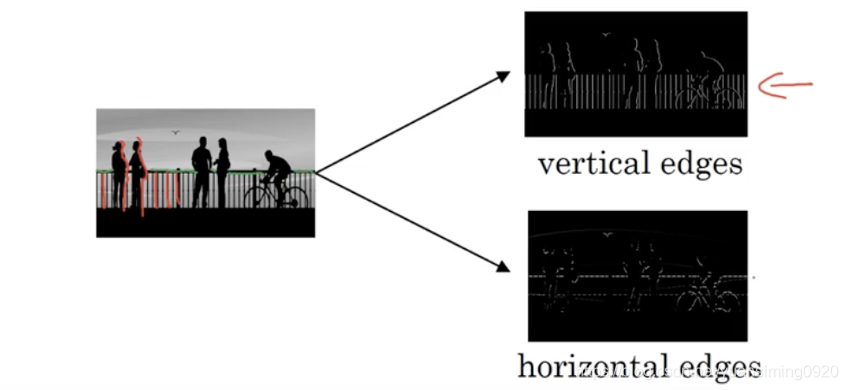
比入有一张图片,我们想要找到图片中的垂直边缘(红色的线)或者水平边缘(绿色的线),那么应该怎么做呢?这就可以使用卷积来做。以一张比较简单的图片为例:
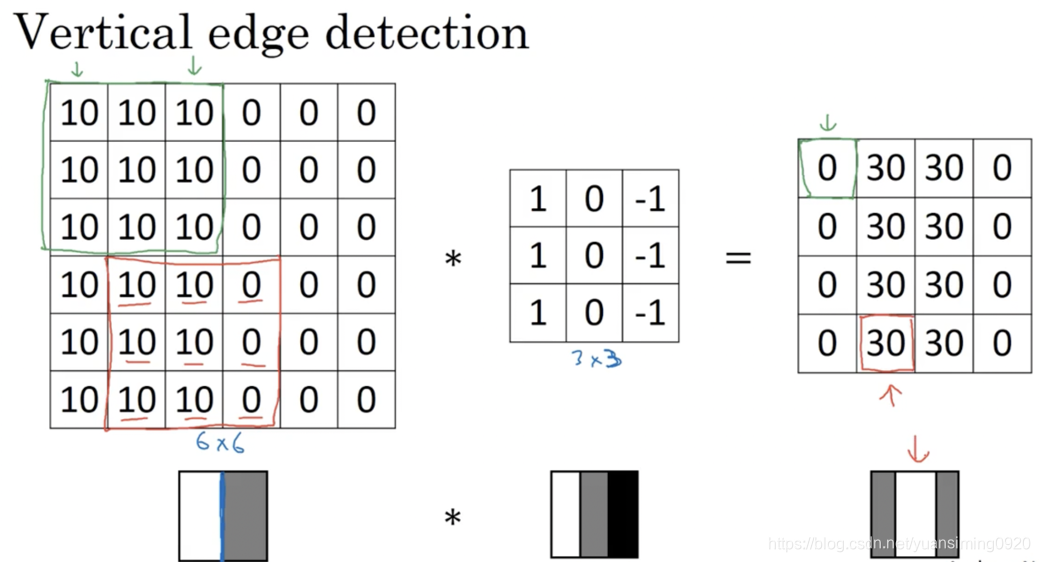
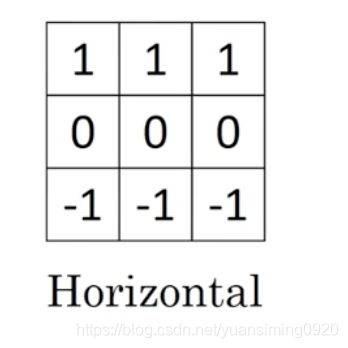
这张图片是一个66的灰度图像,且左边是亮的右边是比较暗的,此时可以使用一个33的卷集核(过滤器)来对图片进行卷积,最后得到一个4*4的中间亮两边暗的图,也就实现了垂直边缘检测。水平的卷积核参数如下:
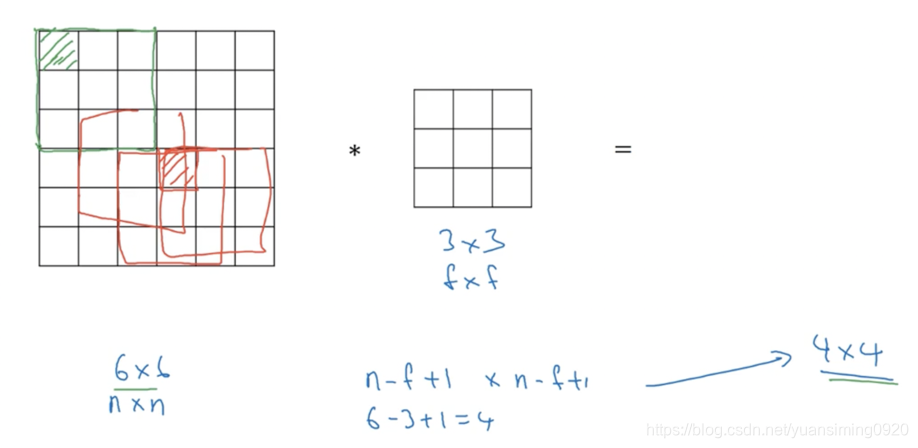
padding:进行padding的原因(1)卷积之后图像会变得越来越小(2)图像的边缘信息会丢失

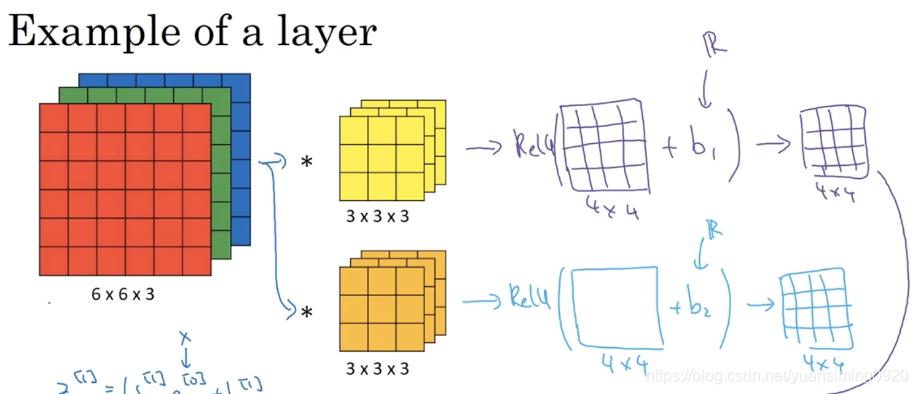
三维卷积:
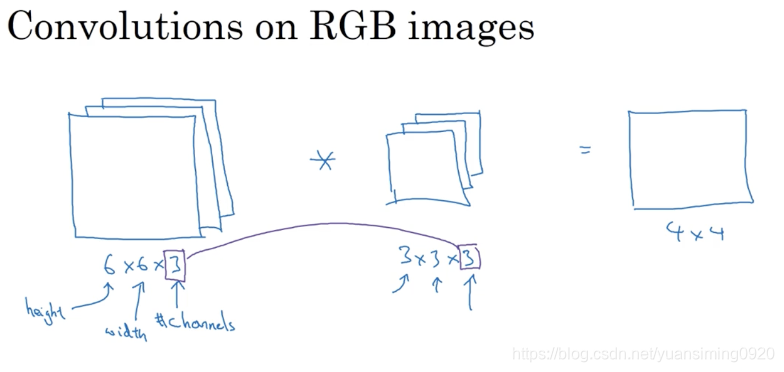
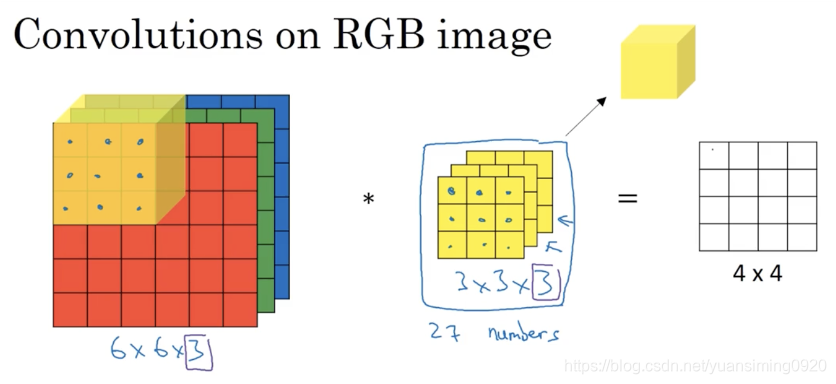
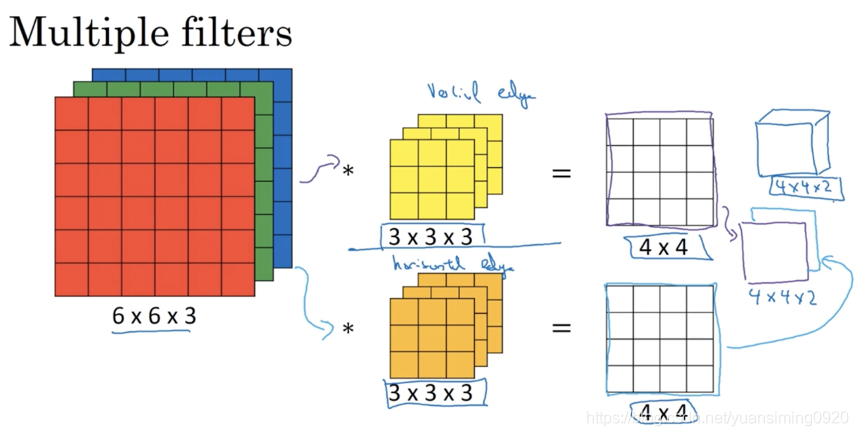
一个简单的卷积神经网络模型:
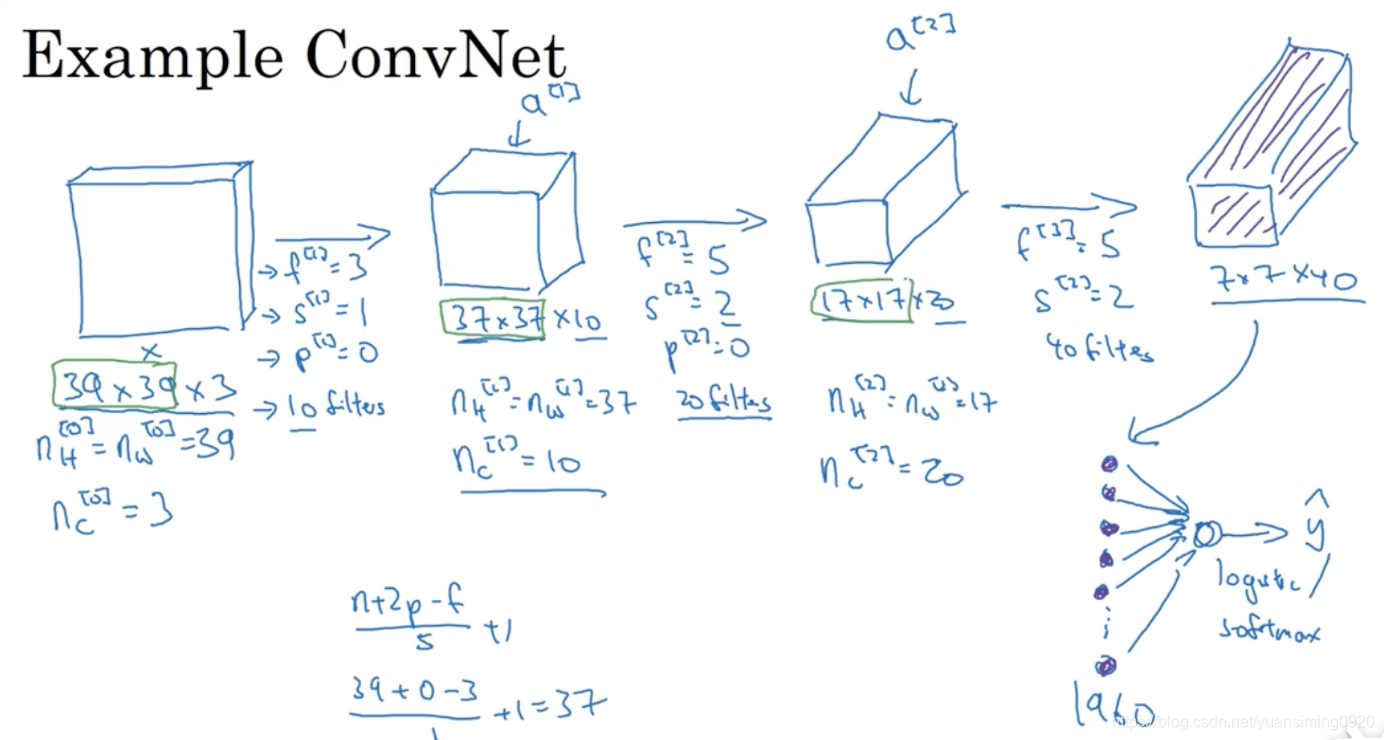
卷积神经网络与人工神经网络的对比:
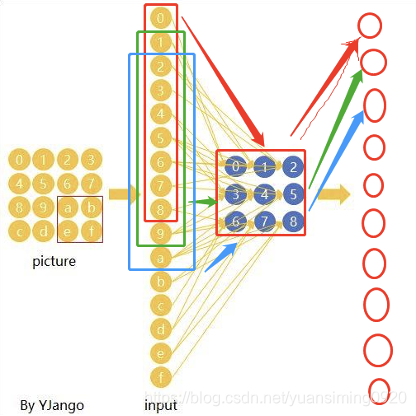
图片可以拉成一个列向量,这样红框、绿框、蓝框可以理解下边神经网络的x1、x2和x3…,后边的蓝色矩形区域表示一个卷积核,卷积核+激活函数就可以理解为是黄色圈圈部分,如下图,每个卷积核+relu层就类似黄色圈圈部分。卷积核就可以让每个参数和权值相乘并求和,然后再通过激活函数激活。
5 CNN在CV(计算机视觉)上的应用
图像分类、目标检测、图像分割(语义分割、实例分割):

- 图像分类:判别图中物体是什么,比如是猫还是狗;
- 语义分割:对图像进行像素级分类,预测每个像素属于的类别,不区分个体;
- 目标检测:寻找图像中的物体并进行定位;
- 实例分割:定位图中每个物体,并进行像素级标注,区分不同个体;
- 图像识别:(1)1:1识别,比如人脸验证,坐火车时确认你本人就是身份证上的人 (这是张三吗?)(2)1:n识别,比如人脸识别,进小区的门禁,是你的脸在小区人脸底库(这是谁?)
5.1 图像分类
图像分类具体的过程:最后变成7740的特征图后,我们把它拉成一个1960的列向量,接下来通过全连接层来进行分类

层越深,特征图越好,比如:
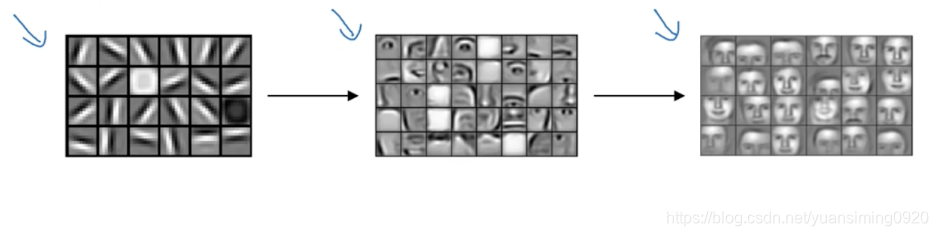
全连接层的操作如下,比如我要分k个类,1096就会变成k个z(要分几个类,k就为几),比如要分猪,狗,猫三类,那么k为3,假如Z从上向下分别表示猪,狗,猫,那么训练的时候,对于Z1,就让属于猪的特征的权重W大一些(z的值与所有的x有关,x就表示不同的特征,让属于猪的特征(x)的权重W高一些就好),这样当输入的图片是猪的时候,最后得到的Z1值就比较大,那么通过softmax算出的概率也比较大,那么这个东西就是猪:
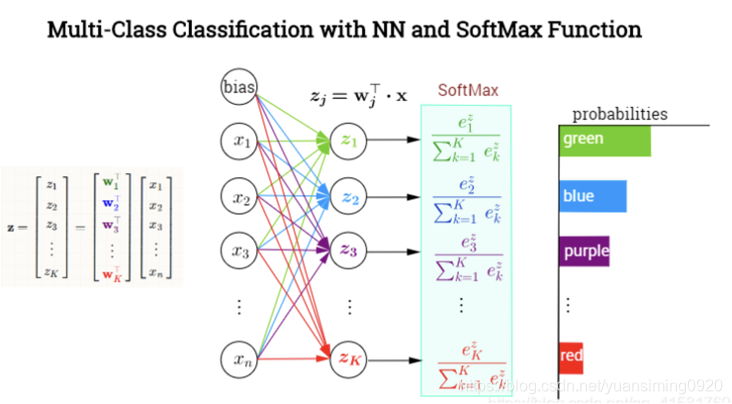
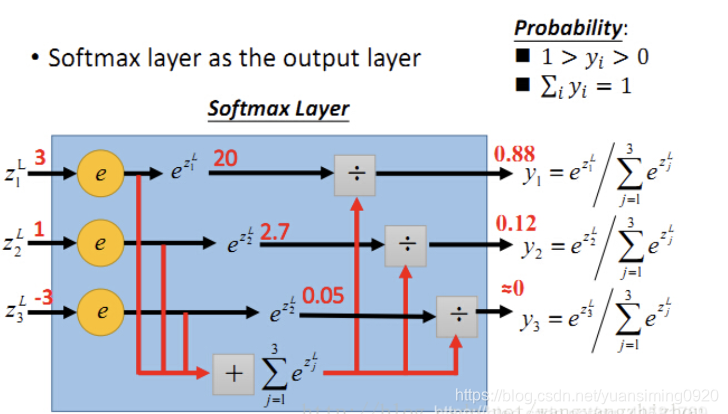
softmax的原理如下:
最后的分类,可以接一个softmax来进行多分类,也可以每个位置(比如三个位置都接)接一个二分类器,只用来表示是或不是即可。
5.2 图像分割
-
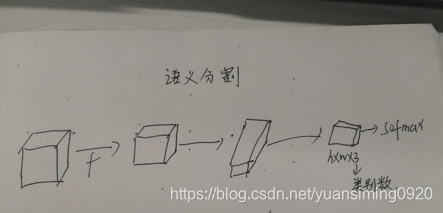
语义分割:像素级分类。要分几类最后特征图的通道数就变成几,比如3,每个通道数可以用来表示类别。然后在这个特征图的每个空间位置接sfotmax分类器,以此来进行像素级的分类,通道数就是类别数。
-
实例分割:要区别个体,一般是先检测,再分割。一个框代表一个实例。(持续更新中)
5.2 目标检测
过程比较麻烦
每个像素都有几个anchor,然后对anchor区域接分类器和回归器,分别来进行分类和定位**(持续更新中)**
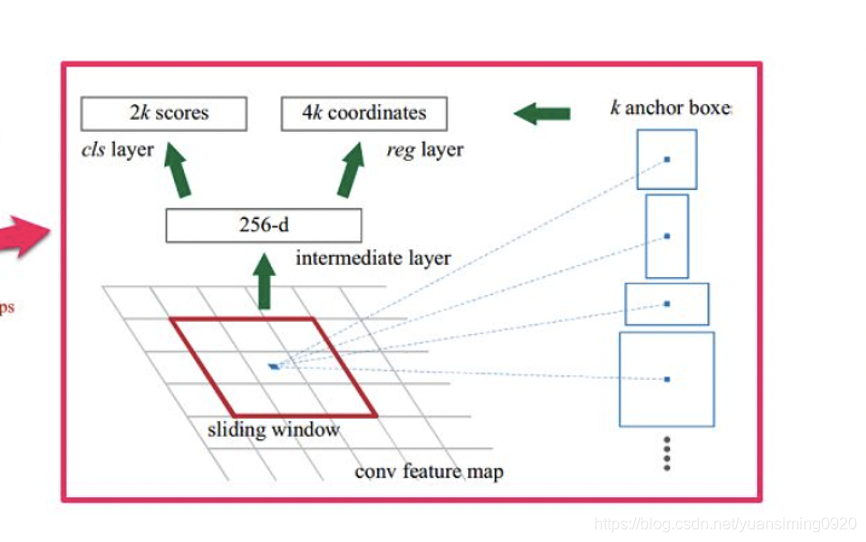
6 Conclusion
- 机器学习是实现人工智能的一种方法;深度学习是实现机器学习的一种方法;CNN是实现实现深度学习的一种方法;CV和NLP是应用;
- 图像识别并不等于图像分类或者目标检测
- 打败世界第一围棋的alphaGo使用的是深度强化学习
- 自动驾驶是一个复杂的系统,有很多传感器雷达,计算机视觉也发挥了一定的作用,因为分析汽车的路况,必须要汽车看的见
- 计算机视觉方面的图像识别,有可能和其它领域交叉,比如看图说话,看图写作文,这就是和自然语言处理方向结合了。如果再涉及到语音方面,比如说给一张图,机器能搞出来一篇作文出来并解读给我们听,就和语音领域进行了交叉。
- 计算机视觉的应用,比如图像分类,检测,分割,关键点检测,行人重识别,目标跟踪,3D重建,超分辨率,图像的去雾、去噪,图像拼接,图像质量评估、图像检索等等。
- 工业缺陷检测是当前深度学习落地的热门项目: 参考链接.
- 目前在阿里比较火的应用:兴趣推荐、以图搜索、用户画像、短视频方向的:视频分类(打标签)、行为(动作)识别,拍一张图跳转到对应的淘宝店
- 机器学习一般可以分为:分类/回归/聚类/推荐/决策树/支持向量机/关联规则/降维/集成学习等等等等
- 所有的机器学习算法都有代价函数(不管有监督还是无监督),梯度下降不一定,因为梯度下降只是优化代价函数的一种方法,而且往往是局部最优解,梯度是机遇代价函数的一阶偏导迭代的,还可以接助二阶偏导,比如牛顿法,或者很多其他的方法,我们接触比较多的是梯度下降法(大部分算法都是用的梯度下降)
- 深度学习和传统机器学习都可以做分类,要选哪个?要看应用场景,数据不多,任务简单,用传统机器学习就可以;大数据,场景复杂,用深度学习;如果做图像,直接用深度学习。
- 机器学习中的BN层,即batch normalization,一般是加到卷积后,激活前,知识点是属于mini batch梯度下降法,类似于下山,一张图更新一次的话,就相当于看一眼走一步,一批图更新一次梯度的话,就是看一圈,综合起来再走一步,山底代表代价函数最小(损失最小)。机器学习中存在一个training data 和 testing data 分布不一致的问题,叫做 Covariate Shift,这个问题就比较严重,比如你猫狗分类器,训练集全部是猫,测试集全部是狗,你训练出来的模型效果肯定不好。BN 论文中,作者提出,深度神经网络中,不同层之间也存在 Covariate Shift,作者叫这个现象为 Internal Covariate Shift,为了让网络前向传播的时候,分布尽量相同,每层都加 BN,让分布尽可能一致,BN 能使得训练更稳定,网络能用更大的 learning rate(会快许多),不那么 care 网络初始化的质量,当然作者巧妙的设计了BN,让 BN 有两个学习的参数,可以让网络选择是否要让每层的分布一致,比较灵活。你可以简单的理解为,让网络内部稳定些,分布不会随着层数的累计东一榔头,西一棒子。这样不利于优化。把人的每个器官比作神经网络的一层,你可以理解为把人的每个器官比作神经网络的一层,你可以理解为躺着刷抖音,身体很累,脑袋很清新是不利于睡觉的,让身体和脑袋的节奏一致,更有益于快速睡觉
- 传统方法做分类,难点不是分类器,而是要手动提取特征上,然后基于此特征来分类,这是传统方法最致命的地方。其实传统方法和深度方法分类器都比较简单。区别在特征提取这一块。传统方法手动设计特征,有限-片面-鲁棒性弱-可解释性强,深度学习方法通过主干网络提取特征,可解释性不太强,但是就是猛,深度学习方法的分类器也非常简单,一般也就 softmax 多分类或者 sigmoid 二分类。
- 传统机器学习算法,会根据经验来假设模型(假设函数h),然后优化假设函数的参数。如果有两个算法都可以解决一个问题,那两个都可以用,你可以自己选择哪一个。

















 1089
1089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









