






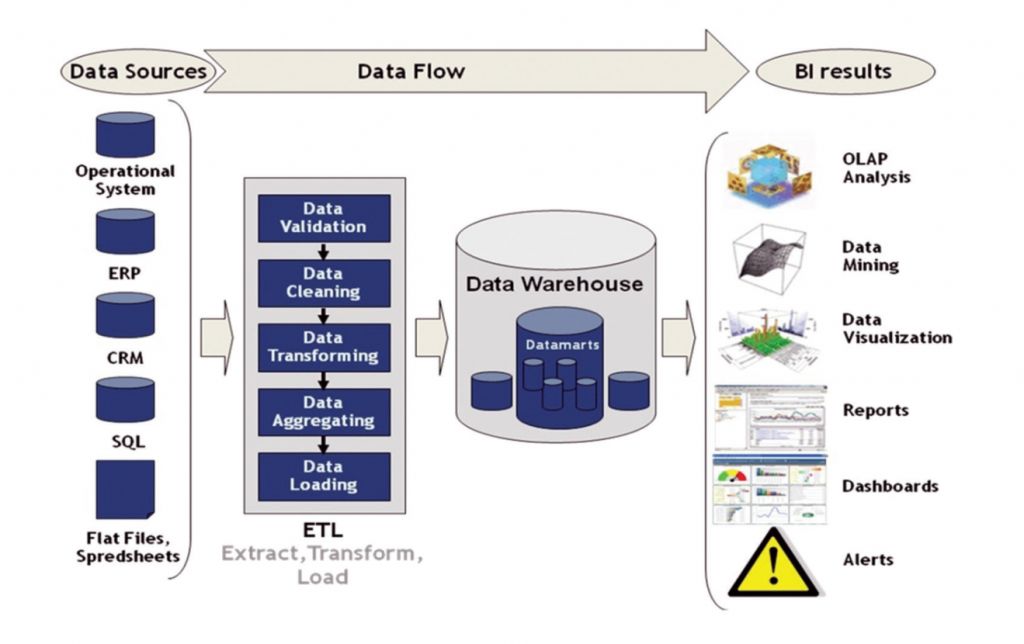
在商业智能(BI)项目中,ETL(Extract, Transform, Load)开发起着至关重要的作用,被视为项目中不可或缺的关键环节。ETL的主要任务是从各个不同的数据源中提取数据,经过转换处理,然后加载到目标数据库或数据仓库中。这一过程将那些分散、零散、标准不统一的数据整合成一致、结构清晰的数据集,为企业的决策制定和业务分析提供坚实的基础。
一个高效、稳定的ETL系统能够大大提高数据的质量和可用性,有助于企业快速、准确地进行数据分析和报告生成。相反,如果ETL设计不当或执行不佳,可能会导致数据质量下降,进而影响到整个BI项目的准确性和有效性。据统计,ETL开发通常会占据BI项目总体时间的三分之一,可见其在项目中的重要地位和影响力。
在接下来的文章中,我们将深入探讨ETL与BI之间的密切关系,以及如何优化ETL开发,以实现BI项目的最佳效果。
示例中提到的数据集成工具分享给大家——
https://s.fanruan.com/8j9is
零基础快速上手,还能根据需求进行个性化修改哦
一、相关名词简介
1. 数据仓库
英文全称为Data Warehouse,简称为DW。
数据仓库之父比尔·恩门(Bill Inmon)在1991年出版的《Building the Data Warehouse》(《建立数据仓库》)一书中提出了关于数据仓库的定义——数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
换句话说,数据仓库是一个以实现特定分析决策为目的,能够随时间的变化,稳定地、持续地为这个需求提供所需要的数据的集合。
业务库与数据仓库的不同:
- 业务库通常是面向事务来设计的,而数据仓库则是面向主题来设计的。
- 业务库尽量避免冗余,而数据仓库则会有意引入冗余,以便于快速分析。
- 业务库为捕获数据而设计,数据仓库是为分析数据而设计。
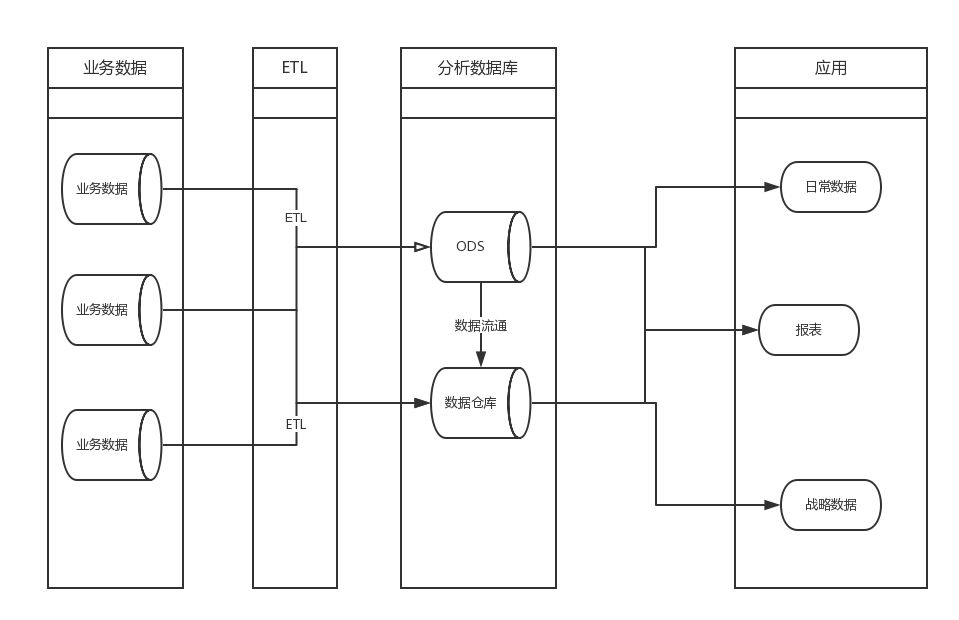
2. 操作型数据存储
英文全称为Operational Data Store,简称ODS,是数据仓库体系结构中的一个可选部分,也被称为贴源层。
ODS具备数据仓库的部分特征和OLTP系统的部分特征。( On-Line Transaction Processing 联机事务处理过程,前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果。) 它是“面向主题的、集成的、当前或接近当前的、不断变化的”数据。
3. ETL
数据抽取(Extract)
这一部分需要在调研阶段做大量的工作,首先要搞清楚数据是从几个业务系统中来,各个业务系统的数据库服务器运行什么DBMS,是否存在手工数据,手工数据量有多大,是否存在非结构化的数据等等,当收集完这些信息之后才可以进行数据抽取的设计。
- 对于与存放DW的数据库系统相同的数据源处理方法
这一类数据源在设计上比较容易。一般情况下,DBMS(SQLServer、Oracle)都会提供数据库链接功能,在DW数据库服务器和原业务系统之间建立直接的链接关系就可以写Select 语句直接访问。
- 对于与DW数据库系统不同的数据源的处理方法
对于这一类数据源,一般情况下也可以通过ODBC的方式建立数据库链接——如SQL Server和Oracle之间。如果不能建立数据库链接,可以有两种方式完成,一种是通过工具将源数据导出成.txt或者是.xls文件,然后再将这些源系统文件导入到ODS中。另外一种方法是通过程序接口来完成。
- 对于文件类型数据源(.txt,.xls)
可以培训业务人员利用数据库工具将这些数据导入到指定的数据库,然后从指定的数据库中抽取。或者还可以借助工具实现。
- 增量更新的问题
对于数据量大的系统,必须考虑增量抽取。一般情况下,业务系统会记录业务发生的时间,我们可以用来做增量的标志,每次抽取之前首先判断ODS中记录最大的时间,然后根据这个时间去业务系统取大于这个时间所有的记录。利用业务系统的时间戳,一般情况下,业务系统没有或者部分有时间戳。
数据清洗转换(Cleaning、Transform)
一般情况下,数据仓库分为ODS、DW两部分。通常的做法是从业务系统到ODS做清洗,将脏数据和不完整数据过滤掉,在从ODS到DW的过程中转换,进行一些业务规则的计算和聚合。
- 数据清洗
数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。
不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。
(1)不完整的数据:这一类数据主要是一些应该有的信息缺失,如供应商的名称、分公司的名称、客户的区域信息缺失、业务系统中主表与明细表不能匹配等。对于这一类数据过滤出来,按缺失的内容分别写入不同Excel文件向客户提交,要求在规定的时间内补全。补全后才写入数据仓库。
(2)错误的数据:这一类错误产生的原因是业务系统不够健全,在接收输入后没有进行判断直接写入后台数据库造成的,比如数值数据输成全角数字字符、字符串数据后面有一个回车操作、日期格式不正确、日期越界等。这一类数据也要分类,对于类似于全角字符、数据前后有不可见字符的问题,只能通过写SQL语句的方式找出来,然后要求客户在业务系统修正之后抽取。日期格式不正确的或者是日期越界的这一类错误会导致ETL运行失败,这一类错误需要去业务系统数据库用SQL的方式挑出来,交给业务主管部门要求限期修正,修正之后再抽取。
(3)重复的数据:对于这一类数据——特别是维表中会出现这种情况——将重复数据记录的所有字段导出来,让客户确认并整理。
数据清洗是一个反复的过程,不可能在几天内完成,只有不断的发现问题,解决问题。对于是否过滤,是否修正一般要求客户确认,对于过滤掉的数据,写入Excel文件或者将过滤数据写入数据表,在ETL开发的初期可以每天向业务单位发送过滤数据的邮件,促使他们尽快地修正错误,同时也可以做为将来验证数据的依据。数据清洗需要注意的是不要将有用的数据过滤掉,对于每个过滤规则认真进行验证,并要用户确认。
- 数据转换
数据转换的任务主要进行不一致的数据转换、数据粒度的转换,以及一些商务规则的计算。
(1)不一致数据转换:这个过程是一个整合的过程,将不同业务系统的相同类型的数据统一,比如同一个供应商在结算系统的编码是XX0001,而在CRM中编码是YY0001,这样在抽取过来之后统一转换成一个编码。
(2)数据粒度的转换:业务系统一般存储非常明细的数据,而数据仓库中数据是用来分析的,不需要非常明细的数据。一般情况下,会将业务系统数据按照数据仓库粒度进行聚合。
(3)商务规则的计算:不同的企业有不同的业务规则、不同的数据指标,这些指标有的时候不是简单的加加减减就能完成,这个时候需要在ETL中将这些数据指标计算好了之后存储在数据仓库中,以供分析使用。
数据的加载(Load)
在数据加载中,提取、转换、加载(ETL)工具会将转换后的数据从暂存区移动到目标数据仓库。对于大多数使用 ETL 的组织来说,该过程是自动化的、定义明确的、连续的和批处理驱动的。下面是两种加载数据的方法。
- 完全加载
在完全加载时,来自源的全部数据被转换并移动到数据仓库。完全加载通常发生在您第一次将数据从源系统加载到数据仓库中时。
- 增量加载
在增量加载中,ETL 工具会定期加载目标系统和源系统之间的增量(或差异)。它会存储最后提取日期,以便仅加载在此日期之后添加的记录。有两种方法可以实现增量加载:
1)流式增量加载
如果您的数据量较小,您可以通过数据管道将持续更改流式传输到目标数据仓库。当数据速度增加到每秒数百万个事件时,您可以使用事件流处理来监控和处理数据流,从而更及时地做出决策。
2)批量增量加载
如果您的数据量很大,您可以定期分批收集将负载数据更改。在此设定的时间段内,由于数据同步,源系统或目标系统都不会发生任何操作。
二、如何优化ETL开发?
ETL是BI项目的关键部分,也是一个长期的过程,只有不断的发现问题并解决问题,才能使ETL运行效率更高,为BI项目后期开发提供准确与高效的数据。
要优化ETL(提取、转换、加载)的开发,可以采取以下一些措施:
1. 需求分析和设计阶段的充分准备
在项目开始阶段,与业务部门充分沟通,了解数据需求和业务规则。清晰定义数据源和目标系统的结构、字段映射、数据转换规则等,可以避免后续开发过程中的重大变更和调整,提高开发效率。
2. 选择合适的ETL工具
根据项目的需求和复杂性,选择适合的ETL工具。市面上有许多商业和开源的ETL工具,开源的ETL工具包括Apache NiFi、Talend Open Studio、Pentaho Data Integration(Kettle)、Apache Kafka、Apache Airflow和StreamSets等。
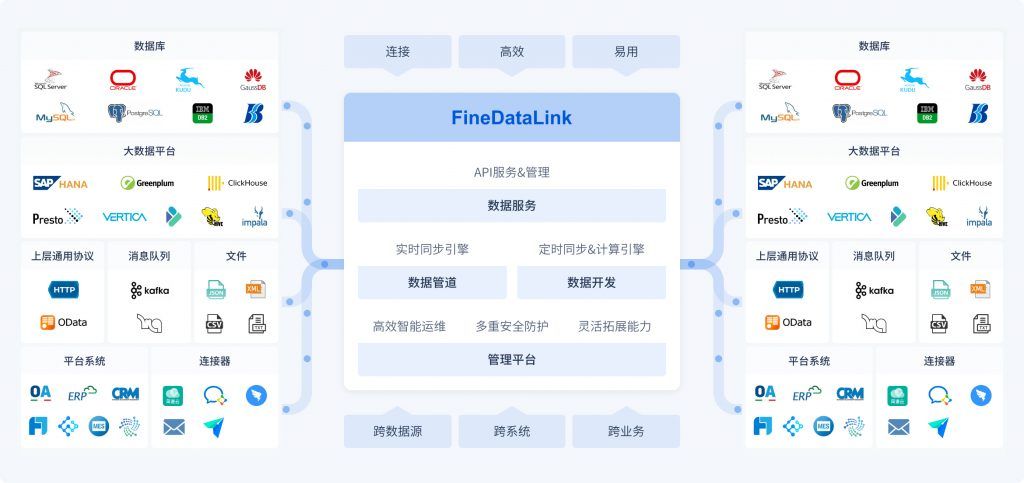
企业级的ETL工具推荐FineDataLink!FineDataLink是帆软旗下低代码/高时效的一站式数据集成平台,主要面向企业IT人员(信息部门/ITBP)人群,帮助他们解决各类不同数据源的数据对接和处理问题(数据库、接口API、业务系统等),赋予用户仅通过单一平台,实现实时数据传输、数据调度、数据治理等各类复杂组合场景的能力,为企业业务的数字化转型提供支持。
对比其他数据集成工具,FineDataLink有以下优势:
- 画布式开发,数据梳理,过程所见即所得:传统ETL工具上手复杂,而FDL采用图形化界面,智能化的异构数据类型匹配,通过简单的拖拉拽实现数据加工计算。从任务管理页面到每一个ETL任务的节点,都致力于做到简单易懂、直接上手可用,降低开发难度和时间成本。
- 双核引擎、提升数据处理效率:FineDataLink提供ELT、ETL双核引擎,针对不同业务场景提供定制化解决方案,提高数据处理效率和准确性。比如较大数据量的同步(单表数据超过1kw行)可以采用ELT(数据同步)原表原样的从数据源端同步至目标库中,当数据需要经过复杂处理时可以通过ETL(数据转换)实现。
3. 模块化设计和重用
将ETL任务划分为小模块,每个模块专注于特定的功能或任务。利用模块化设计,可以提高代码的可维护性和复用性,降低开发和维护成本。同时,建立ETL任务库或模板,可以重复使用已经开发和测试过的代码片段,减少重复劳动和错误。
4. 优化数据处理流程
在数据提取、转换和加载过程中,尽量减少不必要的数据移动和转换操作。优化SQL查询、使用索引、合并和拆分步骤,可以提高数据处理的效率和性能。此外,考虑使用增量加载、并行处理和分布式计算等技术,进一步提高ETL任务的执行速度和扩展性。
5. 自动化测试和监控
建立完善的测试和监控机制,确保ETL任务的稳定性和可靠性。使用自动化测试工具对ETL流程进行全面的单元测试、集成测试和系统测试,及时发现和修复问题。同时,建立监控系统,实时跟踪ETL任务的执行情况和性能指标,及时发现并处理异常和性能瓶颈。
6. 持续优化和改进
ETL开发是一个持续优化和改进的过程。定期审查和分析ETL任务的执行情况和性能数据,找出潜在的瓶颈和问题,并采取相应的优化措施。同时,与业务部门和其他团队保持密切沟通,及时了解业务需求的变化和反馈,调整和优化ETL任务以适应新的需求和挑战。
三、结语
总结来说,ETL在BI项目中扮演着不可或缺的角色,它是将企业分散、零散、标准不统一的数据整合成有价值、有意义的信息的关键步骤。一个高效、稳定的ETL系统能够为企业提供准确、一致、及时的数据支持,从而支持企业的决策制定和业务分析。
然而,要确保ETL过程的顺利进行和数据质量的高标准,需要多方面的考虑和精心的规划。ETL的设计、开发和实施都需要高度专业的技能和经验,以应对各种复杂的数据源和业务需求。
帆软数仓搭建解决方案>>>
https://s.fanruan.com/5iyug
















 715
715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











