







摘要
Deformable Convnets自从被提出以后就受到了广泛的关注,文章将网络应用于目标检测取得里很好的成果,那本人好奇的是如果将这个网络的思想应用在目标分类任务中会取得怎样的结果呢?
这个坑占了有段时间了,现在才来填,略感抱歉。
本文所有源码可以从本人的github个人主页上获取到。
Deformable convolution的概念
2D的卷积包括两个步骤:1)用一个规则的网格 在输入特征图上进行采样;2)对于采样的值用w进行加权再求和。网格 定义了感受野大小和扩张量。比如
={(−1,−1),(−1,0),…,(0,1),(1,1)}
定义了一个
3×3
的核并且扩张量(空洞)为1。
对于在输出特征图 y 上的每一个位置
y(p0)=∑pn∈?(?n)·?(?0+?n), (1)
其中
pn
会穷举在
中的位置。
在可变形卷积中,用偏移 {Δpn|n=1,…,N} 对规则的网格 进行扩充,其中 N=||. 公式(1)就变成
y(p0)=∑pn∈?(?n)·?(?0+?n+Δ?n). (2)
现在,采样就在不规则有偏移的位置 ?n+Δ?n 上进行。因为这个偏移 Δ? 通常是小数,等式(2)要按以下进行双线性插值
?(?)=∑?G(?,?)·?(?), (3)
其中
?
表示一个任意的(小数)位置(对于等式(2)
?=?0+?n+Δ?n
),
?
穷举在特征图
?
上的所有整数空间位置,并且
G(·,·)
是双线性插值的核。注意
G
是二维的。它被分成两个一维的核的计算会很快因为 G(?,?) 只在几个 ? 上是非零的。
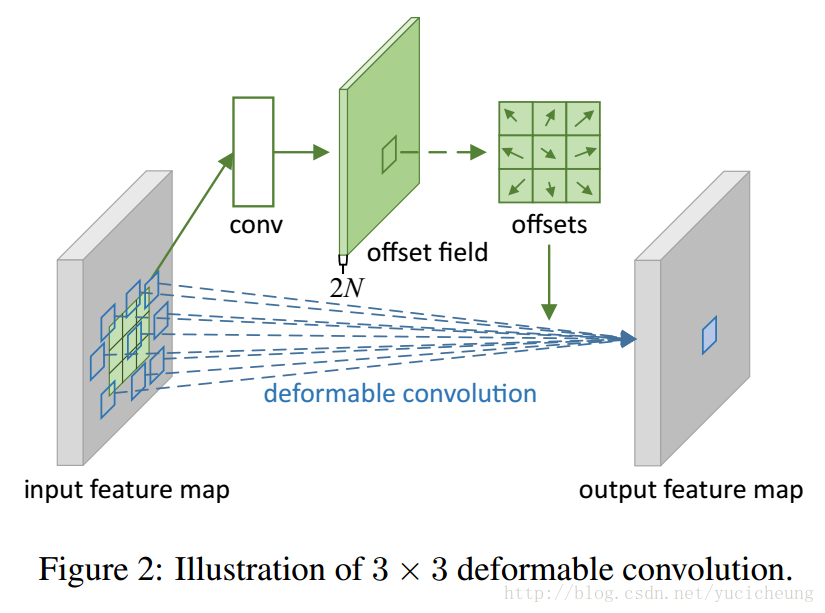
正如在图2中描述的一样,偏移是通过在同一个输入特征图上再应用一个卷积层来获得的。卷积核的空间分辨率和扩张量和目前的卷积层一样(比如,在图2中也是 3×3 扩张量为1)。输出的偏移的域的和输入的特征图有相同的空间分辨率。通道维度 2N 对应着 N 个2D的偏移。在训练中,用于产生输出特征和偏移的卷积核同时在进行学习。要学习到偏移量,梯度通过等式(3)和(4)中的双线性操作进行反向传播。详情参见附录A.
2.3 Deformable ConvNets
deformable convolution和RoI pooling模块与它们的平凡版本有相同的输入和输出,因此,就能方便地替换现有CNN中对应的普通模块。在实际训练中,这些添加的用于学习偏移的conv和fc层都以零权重初始化。学习率设为现有层的学习率的
要把deformable ConvNets和目前为止最好的CNN架构结合起来,我们注意到这些架构都是由两个阶段组成:第一,一个深度的全卷积网络在整张输入图上产生特征图;第二,一个范围窄的针对特定任务的网络由特征图来生成结果。我们在以下内容中对这两点进行详细说明。
Deformable Convolution for Feature Extraction














 2712
2712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









