







前言
注意:本篇并非创建图床的问题
本人使用的图床是阿里云的
最近将本地的markdown文档上传到CSDN,所有的图片都会提示:源站可能有防盗链机制,建议将图片保存下来直接上传
但是直接把图片链接粘贴到浏览器是可以查看的
解决方法
看了其他博主的解决方法:可以使用HTML格式显示图图片
markdown格式:
HTML格式
<img src="https://massachusetts-pubic.oss-cn-guangzhou.aliyuncs.com/%E5%9B%BE%E5%BA%8A/202209241308148.png"/>
对单个文档批量化替换
但是一篇博客可能上百张图片,一个一个链接的改,还不如将图片保存下来直接上传,于是乎我找到了另一篇博客,博主写了一段python脚本,可以批量化处理一篇博文的所有图片,将格式换位HTML
链接:
CSDN 转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传_会下雪的晴天的博客-CSDN博客
# -*- coding: utf-8 -*-
# @Author: yq1ng
# @Date: 2021-05-20 17:22:08
# @Last Modified by: yq1ng
# @Last Modified time: 2021-05-20 18:19:47
import re
old_path = "d:/code/python/md/old_file.md"
new_path = "d:/code/python/md/new_file.md"
old_file = open(old_path, 'r', encoding='utf-8')
new_file = open(new_path, 'w', encoding='utf-8')
old_line = old_file.readline()
count = 0
while old_line:
if "![" in old_line:
url = re.findall('https://.*png|https://.*jpeg|https://.*jpg', old_line)
img = '<img src="' + url[0] + '"/>'
new_line = re.sub('!\[.*\)', img, old_line)
new_file.write(new_line)
print(old_line + ' ===> ' + new_line)
count += 1
else:
new_file.write(old_line)
old_line = old_file.readline()
old_file.close()
new_file.close()
print('\n已成功替换' + str(count) + '处外链问题')
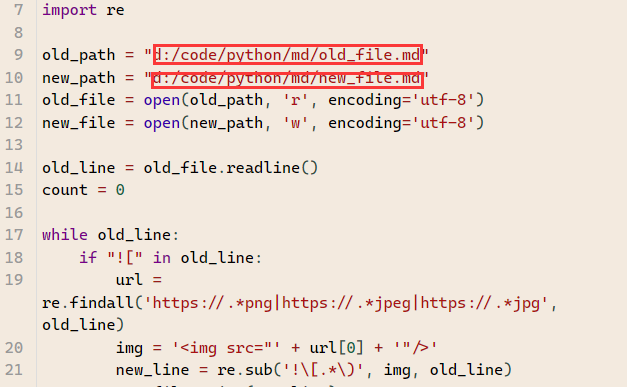
只需把红框里的路径分别改为
- 要被批量化图片链接处理的文档路径,
- 处理后的文件名和路径
如果就在当前目录,可以用下面这样的相对路径
old_path = “./old_file.md”
new_path = “./new_file.md”
把脚本存到一个.py的文件中
通过python3解析器运行这个文件即可完成转化(如果没有,可以配置一下)
封装
使用
鉴于大家可能对python并不熟悉,我把python脚本的书写和运行封装成了一个可执行程序。
软件安装:
wget https://massachusetts-pubic.oss-cn-guangzhou.aliyuncs.com/%E5%8F%AF%E6%89%A7%E8%A1%8C%E7%A8%8B%E5%BA%8F/trs
chmod 775 trs
只需执行
./trs [文档名]
即可生成一个new_file文件夹,其中存储着转换后的文档


源代码
#include<iostream>
#include<stdio.h>
#include<string>
#include<unistd.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<sys/stat.h>
using namespace std;
int main(int argc, char* argv[])
{
//transplink test.md test_new.md
FILE* py = fopen("transplink.py","w");
//1.组合一个python文本
string shInPy = "import re\n\n";
shInPy+="old_path = \"";
shInPy+=argv[1];
shInPy+="\"\nnew_path = \"./new_file/";
if(argv[2])
{
shInPy+=argv[2];
shInPy+="\"\n";
}
else
{
shInPy+="new_./";
shInPy+=argv[1];
shInPy+="\"\n";
}
shInPy+="old_file = open(old_path, 'r', encoding='utf-8')\n\
new_file = open(new_path, 'w', encoding='utf-8')\n\n\
old_line = old_file.readline()\n\
count = 0\n\n\
while old_line:\n\
if \"![\" in old_line:\n\
url = re.findall('https://.*png|https://.*jpeg|https://.*jpg', old_line)\n\
img = '<img src=\"' + url[0] + '\"/>'\n\
new_line = re.sub('!\\[.*\\)', img, old_line)\n\
new_file.write(new_line)\n\
count += 1\n\
else:\n\
new_file.write(old_line)\n\
old_line = old_file.readline()\n\n\
old_file.close()\n\
new_file.close()\n\n\
print('已成功替换' + str(count) + '处外链问题')";
fputs(shInPy.c_str(),py);
fclose(py);
//2.检查是否有old_file文件,并创建
if(access("new_file",0)==-1)
{
mkdir("new_file",0775);
}
//3.程序替换,用python3运行脚本
execlp("python3","python3","transplink.py",NULL);
return 0;
}
处理多个文件
既然已经可以完成单文档的批量处理了,必须得实现一下多文档的处理
软件安装:
wget https://massachusetts-pubic.oss-cn-guangzhou.aliyuncs.com/%E5%8F%AF%E6%89%A7%E8%A1%8C%E7%A8%8B%E5%BA%8F/trsall
chmod 775 trsall
只需要执行
./trsall
即可完成当前文档下的所有的.md文件的转换
(注意:必须同时下载trs程序)

new_file中存的就是转换后的文件ge

源代码
这部分程序的源代码不小心被我误删掉了😭
可以分享一下实现的思路,和一些代码碎片
-
将当前路径下的所有文件名都读进来
FILE* fp = NULL; char buff[128] = { 0 }; fp = popen("ls", "r");//将命令ps 通过管道读到fp fread(buff, 1, 127, fp);如上,通过
popen函数调用ls程序获得的字符流就是当前路径下的所有文件名,测试得出,文件之间是用\n换行符隔开的 -
把所有的.md后缀文件抽取出来,同时判断是否存在trs文件
bool exit_trs = false; vector<string> files; char* file = strtok(buff, "\n"); while (1) { if (strstr(file, ".md")) { files.push_back(file); } if (strcmp(file, "trs") == 0) { exit_trs = true; } if ((file = strtok(NULL, "\n")) == NULL) { break; } } -
遍历所有文件,
for (auto e : files) { } -
创建子进程,对子进程进行程序替换,替换为
trs程序;让子进程完成单个文档的批量替换处理int trs_count = 0;//记录成功替换的个数 for (auto e : files) { pid_t id = fork();//创建子进程 if(id==0) { //子进程 cout<<e<<"----转换中----"; execl("./trs","trs",e,NULL); exit(1);//替换失败 } int status = 0; waitpid(id,&status,0);//阻塞等待子进程结束 if((status<<8)&0xff==1) { cout<<"子进程替换失败"<<endl; } else { cout<<e<<"-----转换完成\n"<<endl; trs_count++; } } -
打印替换信息
cout<<"共"<<files.size()<<"个markdown文件,已成功转换"<<trs_counter<<"个"<<endl;














 430
430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









