







在信息爆炸的时代,文本数据呈现出指数级增长。如何高效地从海量文本中提取有价值的信息,成为了数据科学领域的重要课题。本文将使用Python实现一个功能完备的文本分析工具,从基础的词频统计到高级的关键词提取,帮助读者全面掌握文本分析的核心技术。
一、文本分析基础与词频统计
文本分析的第一步通常是进行词频统计,即统计文本中每个词语出现的频率。这有助于我们了解文本的基本内容和特征。
下面是一个简单的词频统计实现:
import re
from collections import Counter
def preprocess_text(text):
"""预处理文本:转换为小写并移除标点符号"""
# 转换为小写
text = text.lower()
# 移除标点符号
text = re.sub(r'[^\w\s]', '', text)
return text
def tokenize_text(text):
"""将文本分词"""
# 使用空格分割文本
tokens = text.split()
return tokens
def count_word_frequencies(tokens):
"""统计词频"""
# 使用Counter类统计词频
word_counts = Counter(tokens)
return word_counts
def analyze_text(text):
"""分析文本并返回词频统计结果"""
# 预处理文本
processed_text = preprocess_text(text)
# 分词
tokens = tokenize_text(processed_text)
# 统计词频
word_counts = count_word_frequencies(tokens)
return word_counts
# 示例文本
sample_text = """
Python是一种高级编程语言,由Guido van Rossum于1989年圣诞节期间创建。
Python以其简洁的语法和易读性而闻名,广泛应用于数据科学、机器学习、Web开发等领域。
Python的设计哲学强调代码的可读性和简洁性,使得它成为初学者和专业开发者的理想选择。
"""
# 分析文本
word_counts = analyze_text(sample_text)
# 输出前10个最常见的词
print("最常见的10个词:")
for word, count in word_counts.most_common(10):
print(f"{
word}: {
count}")

知识点解析:
- 文本预处理:将文本转换为小写并移除标点符号,减少词汇的多样性
- 分词:将文本分割成单个词语(tokens)
- 词频统计:使用
collections.Counter类高效统计词频 - 正则表达式:使用
re模块处理文本中的标点符号
二、停用词处理与改进的词频统计
在实际应用中,像"的"、“是”、"在"等高频词汇通常对文本的核心内容贡献不大,这些词被称为停用词(Stop Words)。移除停用词可以提高文本分析的准确性。
下面是改进后的词频统计实现:
import re
from collections import Counter
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import jieba # 中文分词库
# 下载停用词数据(如果需要)
nltk.download('stopwords')
nltk.download('punkt')
def preprocess_text(text, language='english'):
"""预处理文本:转换为小写、移除标点符号、移除停用词"""
# 转换为小写
text = text.lower()
# 移除标点符号
text = re.sub(r'[^\w\s]', '', text)
# 分词
if language == 'chinese':
# 中文分词
tokens = jieba.cut(text)
else:
# 英文分词
tokens = word_tokenize(text)
# 获取停用词列表
if language == 'chinese':
# 使用自定义中文停用词列表
stop_words = set(['的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '上', '也', '很', '到', '说', '要', '去', '你', '会', '着', '没有', '看', '好', '自己', '这'])
else:
# 使用NLTK英文停用词列表
stop_words = set(stopwords.words('english'))
# 移除停用词
tokens = [token for token in tokens if token not in stop_words]
return tokens
def count_word_frequencies(tokens):
"""统计词频"""
word_counts = Counter(tokens)
return word_counts
def analyze_text(text, language='english'):
"""分析文本并返回词频统计结果"""
# 预处理文本
tokens = preprocess_text(text, language)
# 统计词频
word_counts = count_word_frequencies(tokens)
return word_counts
# 示例文本 - 英文
english_text = """
Python is a high-level programming language created by Guido van Rossum in 1989.
It is known for its simplicity and readability, and is widely used in data science,
machine learning, web development, and other fields.
The design philosophy of Python emphasizes code readability, making it an ideal choice
for both beginners and professional developers.
"""
# 示例文本 - 中文
chinese_text = """
Python是一种高级编程语言,由Guido van Rossum于1989年圣诞节期间创建。
Python以其简洁的语法和易读性而闻名,广泛应用于数据科学、机器学习、Web开发等领域。
Python的设计哲学强调代码的可读性和简洁性,使得它成为初学者和专业开发者的理想选择。
"""
# 分析英文文本
english_word_counts = analyze_text(english_text, language='english')
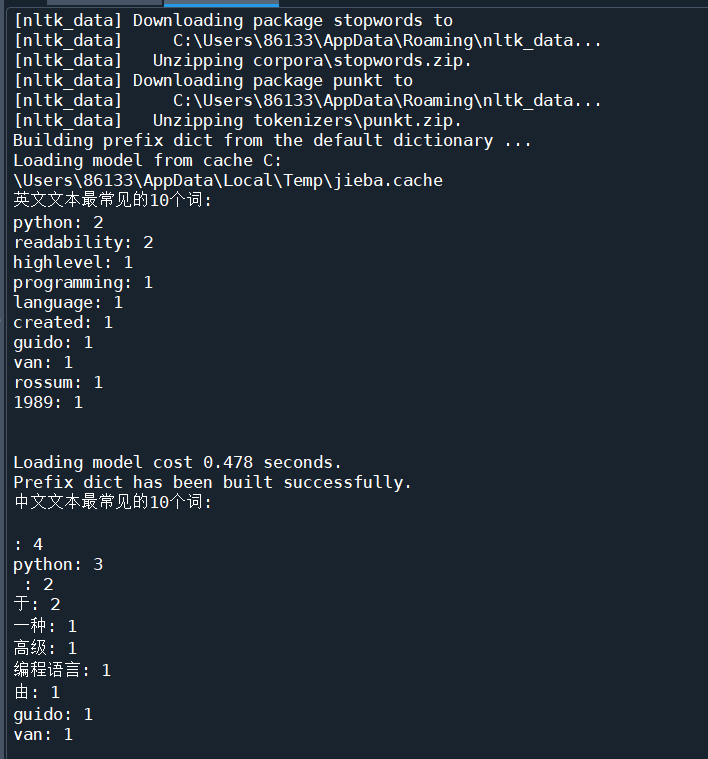
print("英文文本最常见的10个词:")
for word, count in english_word_counts.most_common(10):
print(f"{
word}: {
count}")
print("\n")
# 分析中文文本
chinese_word_counts = analyze_text(chinese_text, language='chinese')
print("中文文本最常见的10个词:")
for word, count in chinese_word_counts.most_common(10):
print(f"{
word}: {
count}")
知识点解析:
- 停用词处理:移除对文本分析无意义的高频词汇
- 多语言支持:分别处理英文和中文文本
- 中文分词:使用
jieba库进行中文文本分词 - NLTK库:自然语言处理工具包,提供停用词列表和分词功能
三、关键词提取算法
关键词提取是文本分析的核心任务之一,它能够自动识别文本中最能代表其主题的词语或短语。下面介绍几种常用的关键词提取方法:
1. TF-IDF算法
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的关键词提取算法,它综合考虑了词语在文本中的出现频率和在整个语料库中的稀有性。
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
def extract_keywords_tfidf(texts, top_n=10):
"""使用TF-IDF算法提取关键词"""
# 初始化TF-IDF向量器
vectorizer = TfidfVectorizer(stop_words='english')
# 计算TF-IDF矩阵
tfidf_matrix = vectorizer.fit_transform(texts)
# 获取所有词语
feature_names = vectorizer.get_feature_names_out()
# 获取每个文本的关键词
keywords_list = []
for doc_index in range(tfidf_matrix.shape[0]):
# 获取当前文本的TF-IDF向量
feature_index = tfidf_matrix[doc_index, :].nonzero()[1]
tfidf_scores = zip(feature_index, [tfidf_matrix[doc_index, x] for x in feature_index])
# 按TF-IDF值排序
sorted_tfidf_scores = sorted(tfidf_scores, key=lambda x: x[1], reverse=True)
# 获取前top_n个关键词
top_keywords = [(feature_names[i], score) for (i, score) in sorted_tfidf_scores[:top_n]]
keywords_list.append(top_keywords)
return keywords_list
# 示例文本集合
documents = [
"Python is a programming language widely used in data science and machine learning.",
"Machine learning uses various algorithms to make predictions based on data.",
"Data science combines statistics, programming, and domain knowledge to extract insights from data.",
"Natural la 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









