






1.Scrapy爬取北京公交车信息beijing.8684.cn/(大数据采集与预处理)
首先声明:爬取的数据只是在pycharm命令行中显示,并没有放到数据库里。
1.1首先在pycharm中安装好Scrapy:
在命令行终端输入以下命令:
A:\python\Test>pip install scrapy
#确保pip正常,或者pip的版本不同
1.2在pycharm中的命令行界面建立项目包:
在命令行终端输入以下命令:
A:\python\Test>scrapy startproject beijingbus
#这里的A:\python\Test>自己可以设置自己想要将项目保存的路径,包括文件名可以自拟
1.3命令行终端切换到beijingbus目录,创建spider:
在命令行终端输入以下命令:
A:\python\Test>cd beijngbus
A:\python\Test\beijingbus>scrapy genspider bei_bus beijing.8684.cn
1.4pycharm到创建好的目录下开始编写代码
1.4.1创建好的目录如下图:
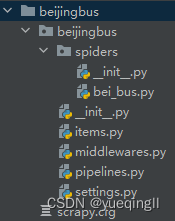
1.4.2编写settings.py
将ROBOTSTXT_OBEY的参数改为False,使爬虫不遵循Robots协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
将DEFAULT_REQUEST_HEADERS方法注释给去掉,并加上User-Agent属性(操作如下图)
DEFAULT_REQUEST_HEADERS = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"
}
User-Agent属性获取方法:
到官网北京公交车beijing.8684.cn/,按F12检查导航,点击网络,获取相应User-Agent属性
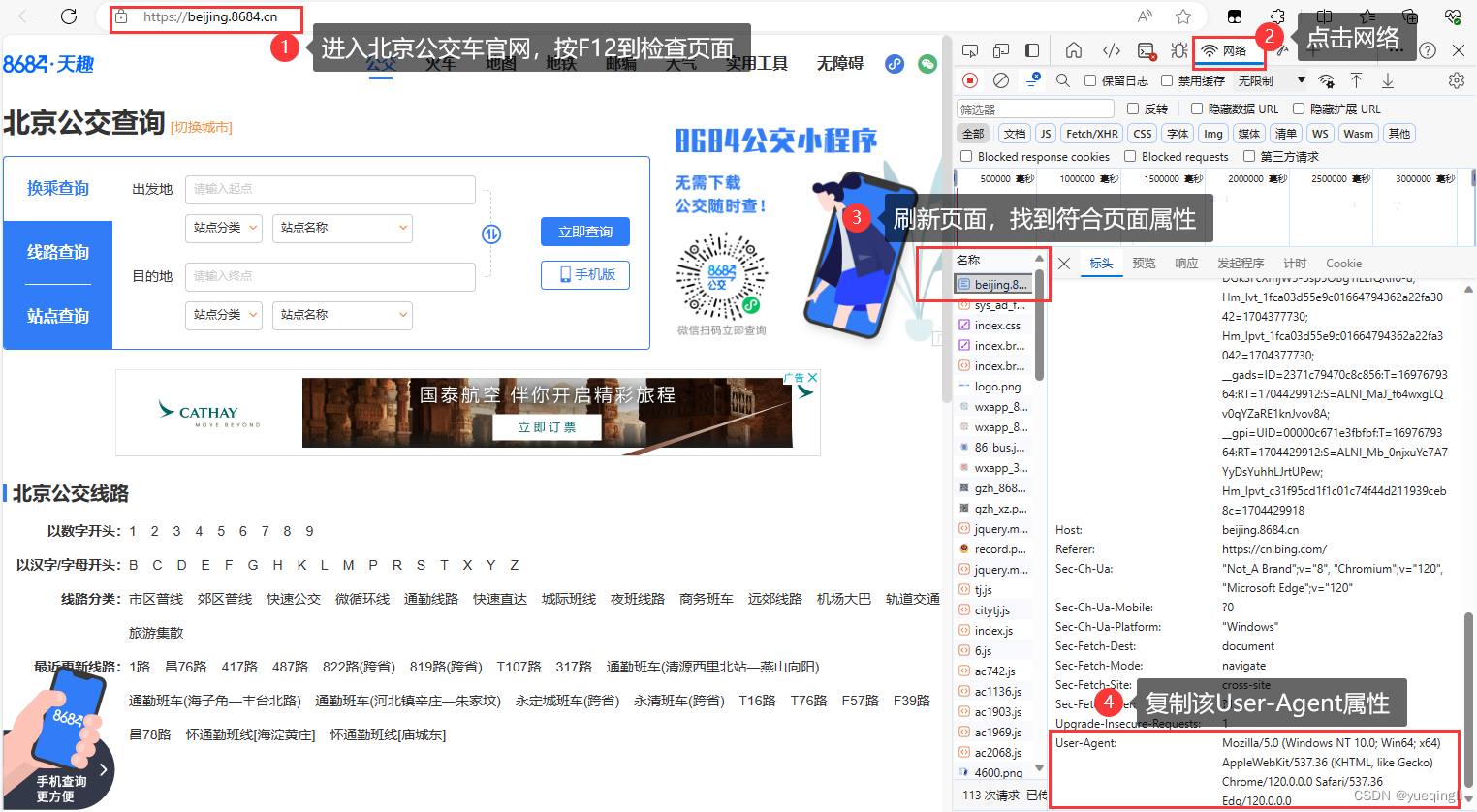
1.4.3编写bei_bus.py文件:
具体操作就是各个级别的页面相应爬取并构建网页的网址
避免乱码的话,通常我喜欢在整个代码前加上以下命令:
# -*- coding: utf-8 -*-
完整bei_bus.py代码如下(爬取了三级网页)
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Spider, FormRequest, Request
from urllib.parse import urljoin
from ..items import BeijingbusItem
class BeiBusSpider(scrapy.Spider):
name = 'bei_bus'
allowed_domains = ['beijing.8684.cn']
start_urls = ['http://beijing.8684.cn/']
# 一级网页
def start_requests(self):
# 遍历页码,构造一级网页的URL
for page in range(1):
url = '{url}/list{page}'.format(url=self.start_urls[0], page=(page+1))
# 发送POST请求,获取一级网页的响应,并指定回调函数为parse_index
yield FormRequest(url, callback=self.parse_index)
# 二级网页
def parse_index(self, response):
# 提取公交车列表页中每个公交车的链接
beijingbus = response.xpath('//div[@class="list clearfix"]/a//@href').extract()
for href in beijingbus:
# 构造二级网页的URL
url2 = urljoin(self.start_urls[0], href)
# 发送GET请求,获取二级网页的响应,并指定回调函数为parse_detail
yield Request(url2, callback=self.parse_detail)
# 解析详细页
def parse_detail(self, response):
# 提取公交车的名称、运行时间和类型
bus_name = response.xpath('//div[@class="info"]/h1//text()').extract_first()
bus_time = response.xpath('//div[@class="info"]/ul/li[1]//text()').extract_first()
bus_type = response.xpath('//div[@class="info"]/ul/li[2]//text()').extract_first()
# 创建BeijingbusItem对象并填充数据
bus_item = BeijingbusItem()
# 将提取的数据填充到BeijingbusItem对象的相应字段中
bus_item['bus_name'] = bus_name
bus_item['bus_time'] = bus_time
bus_item['bus_type'] = bus_type
# 返回提取的公交车数据项
yield bus_item
def parse(self, response):
pass
1.4.4编写items.py文件:
Scrapy的Item类定义,用于定义爬虫要提取的数据字段。
import scrapy
class BeijingBusItem(scrapy.Item):
# 定义您的项目字段,例如:
# name = scrapy.Field()
bus_name = scrapy.Field() # 公交车名称
bus_type = scrapy.Field() # 公交车类型
bus_time = scrapy.Field() # 公交车时间
# pass
1.5在pycharm中的命令行界面输出详细信息
命令行如下
A:\python\Test\beijingbus>scrapy crawl bei_bus
#实现三级网页的爬取
实现效果部分截图如下:
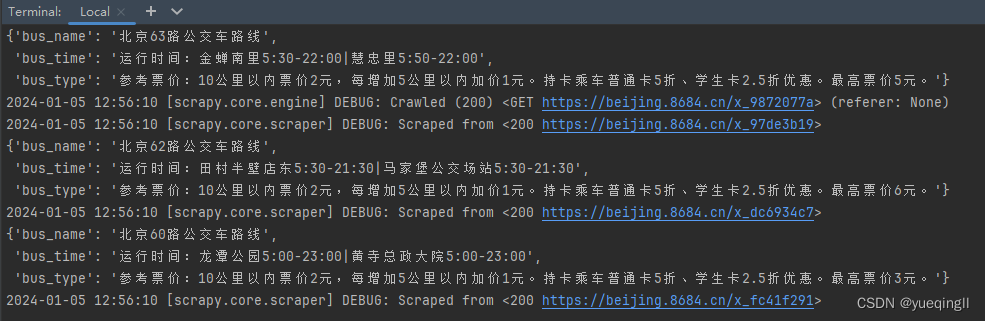
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











