









前言
随着生成式人工智能(AIGC)技术的兴起,技术构建者们又一次冲入了一个满是挑战和机遇的浪潮。Amazon Bedrock 提供了构建生成式人工智能应用程序所需的一切,它是专门为创新者量身打造的平台。通过 Amazon Bedrock 强大的资源和工具,你可以迅速体验最新生成式人工智能技术,无论你的经验如何。无论你是AI初学者还是希望提升技能的专家,Amazon Bedrock 都能助你一臂之力。
本教程的内容包括:
- 快速登录 Amazon Bedrock && 环境准备
- 应用一:在 Amazon Bedrock 上掌握 Stable Diffusion AI SDXL 1.0:创造独特艺术风格的图像应用
- 应用二:在 Amazon Bedrock 上掌握 Meta Llama 3:快速轻松地构建基于生成式人工智能的应用
Amazon Bedrock 的优势
Amazon Bedrock 是一项完全托管的服务,通过单个 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon Titan 等领先人工智能公司的高性能基础模型(FM),以及通过安全性、隐私性和负责任的 AI 构建生成式人工智能应用程序所需的一系列广泛功能。
点击 “开始实验” 按钮,即可扫码进入实验环境。测试账号有效期仅为一天,过期后系统将自动回收清理,请不要上传您的重要数据。
同时,点击 “注册海外账号” 按钮即可免费注册属于你的亚马逊云科技海外区账号,开启个性化的系统构建之旅,进一步探索更广泛、更深入的云服务领域并保留实验中构建的系统应用,尽情享受云上构建的无限可能!
快速登录Amazon Bedrock
1. 进入登录页面
点击 “开始实验” 按钮,即可扫码进入实验环境。测试账号有效期仅为一天,过期后系统将自动回收清理,请不要上传您的重要数据。
同时,点击 “注册海外账号” 按钮即可免费注册属于你的亚马逊云科技海外区账号,开启个性化的系统构建之旅,进一步探索更广泛、更深入的云服务领域并保留实验中构建的系统应用,尽情享受云上构建的无限可能!

扫码登陆:

填写邮箱:
如果您之前没有填写过邮箱,则需要填写一下邮箱,并勾选隐私协议,点击前往实验,及可进入实验室
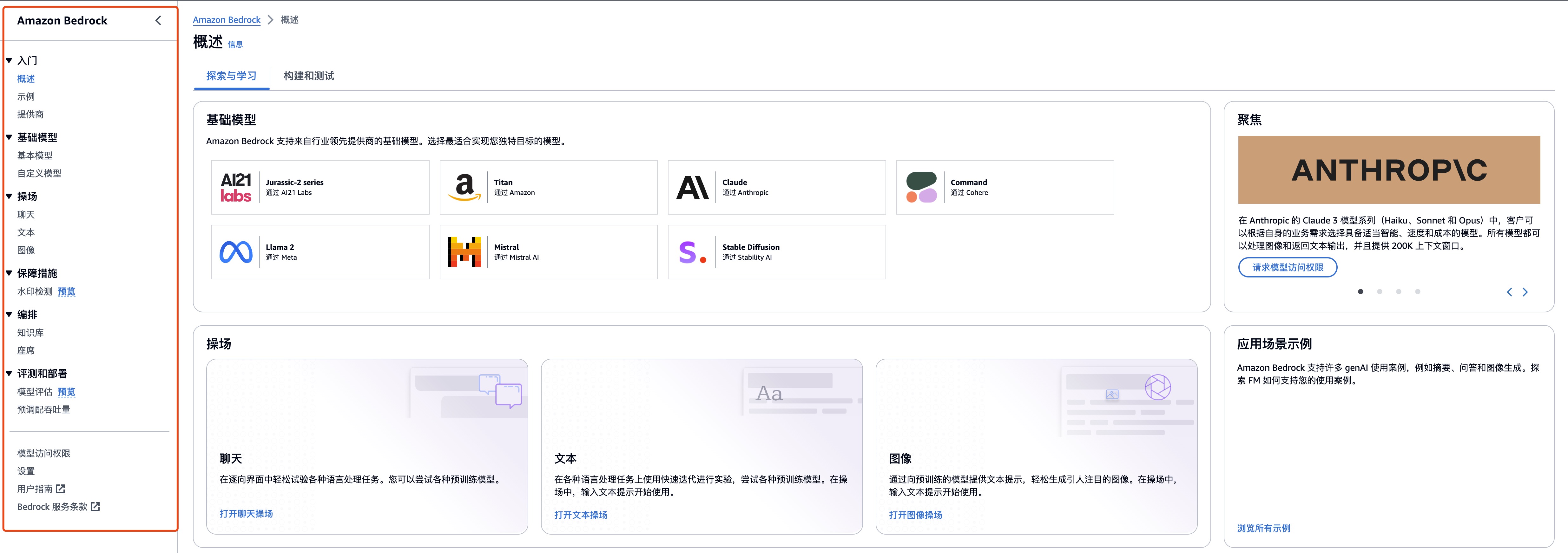
2. 进入操作界面
进入操作界面
应用一:创造独特艺术风格的图像应用
1、快速体验Stability AI SDXL1.0 模型
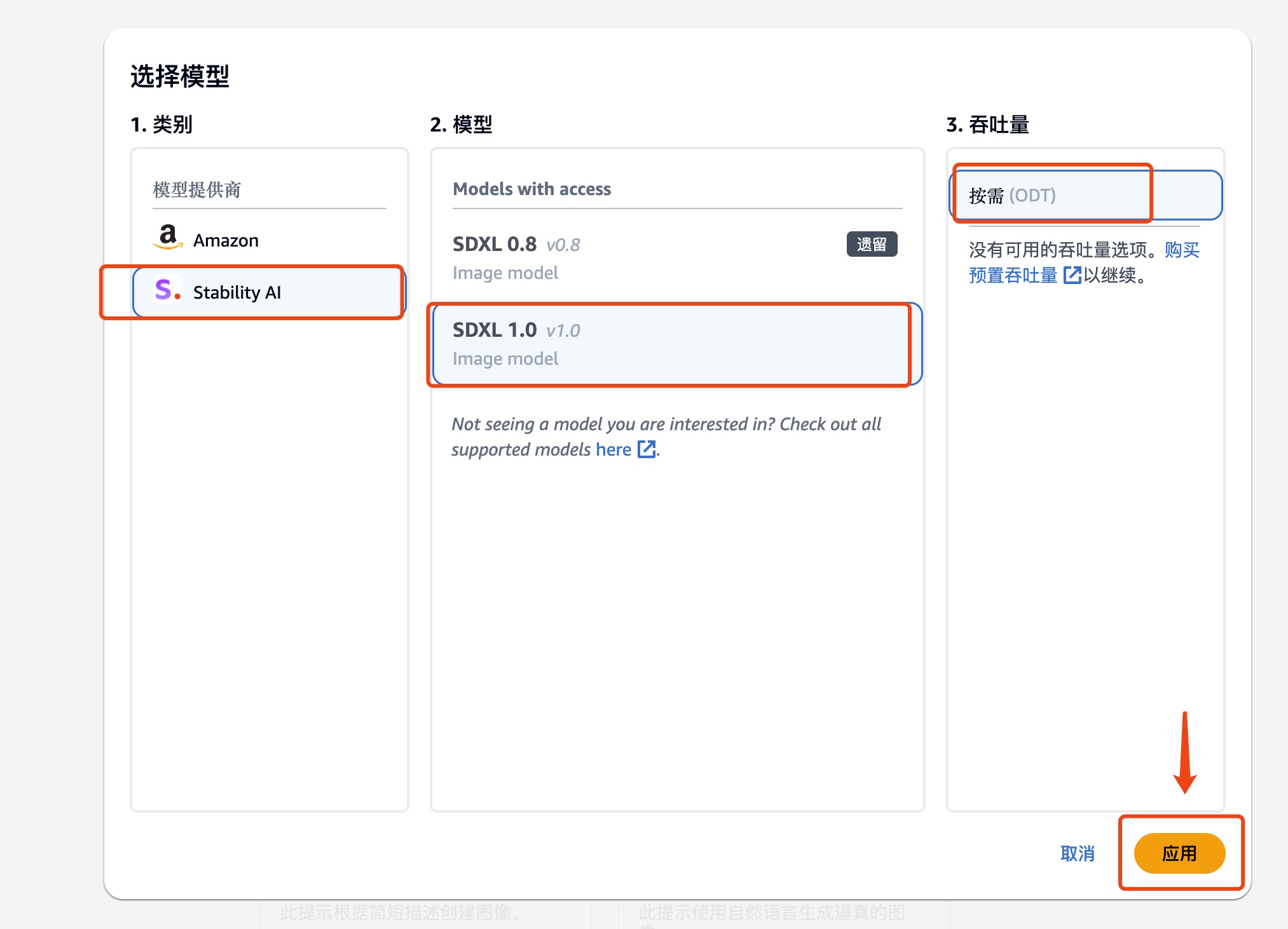
1.1 选择 Amazon Bedrock 中 Stability AI SDXL 1.0 模型
选择左侧菜单栏中,选择操场中的图像功能,
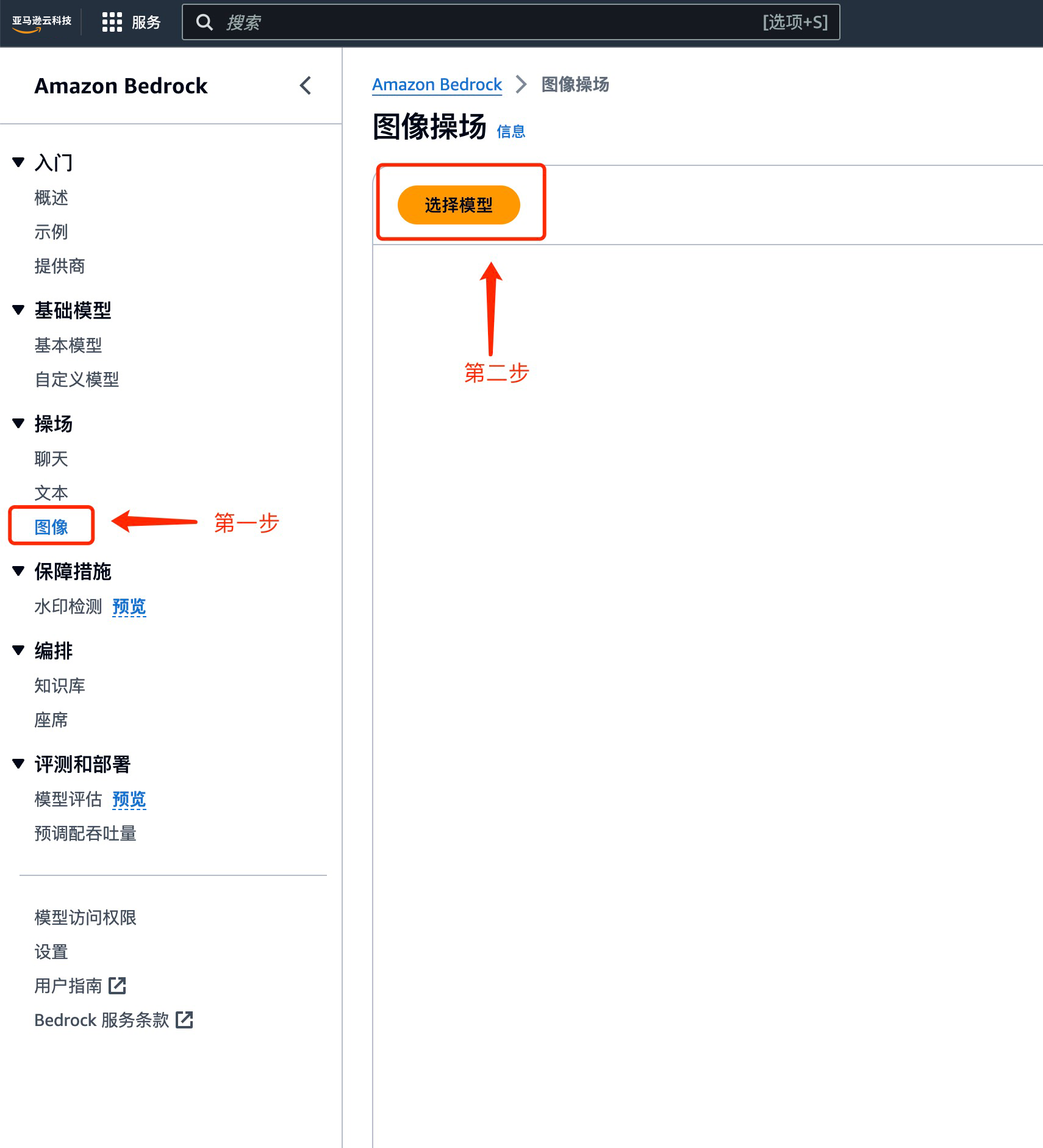
勾选所需要的模型
1.2 马上体验 Amazon Bedrock 中 Stability AI SDXL 1.0 模型
操作解释
| 操作 | 内容 |
|---|---|
| 模式 | 模型生成新图像(生成)或编辑(编辑)在参考图像中提供的图像 |
| 否定提示 | 不希望模型生成的项目或概念,例如卡通或暴力 |
| 推理图像 | 上传图像作为图像生成或编辑的参考 |
| 响应图像 | 生成图像的输出设置,例如质量、方向、大小和要生成的图像数量 |
| 高级配置 | 要传递给模型的推理参数 |
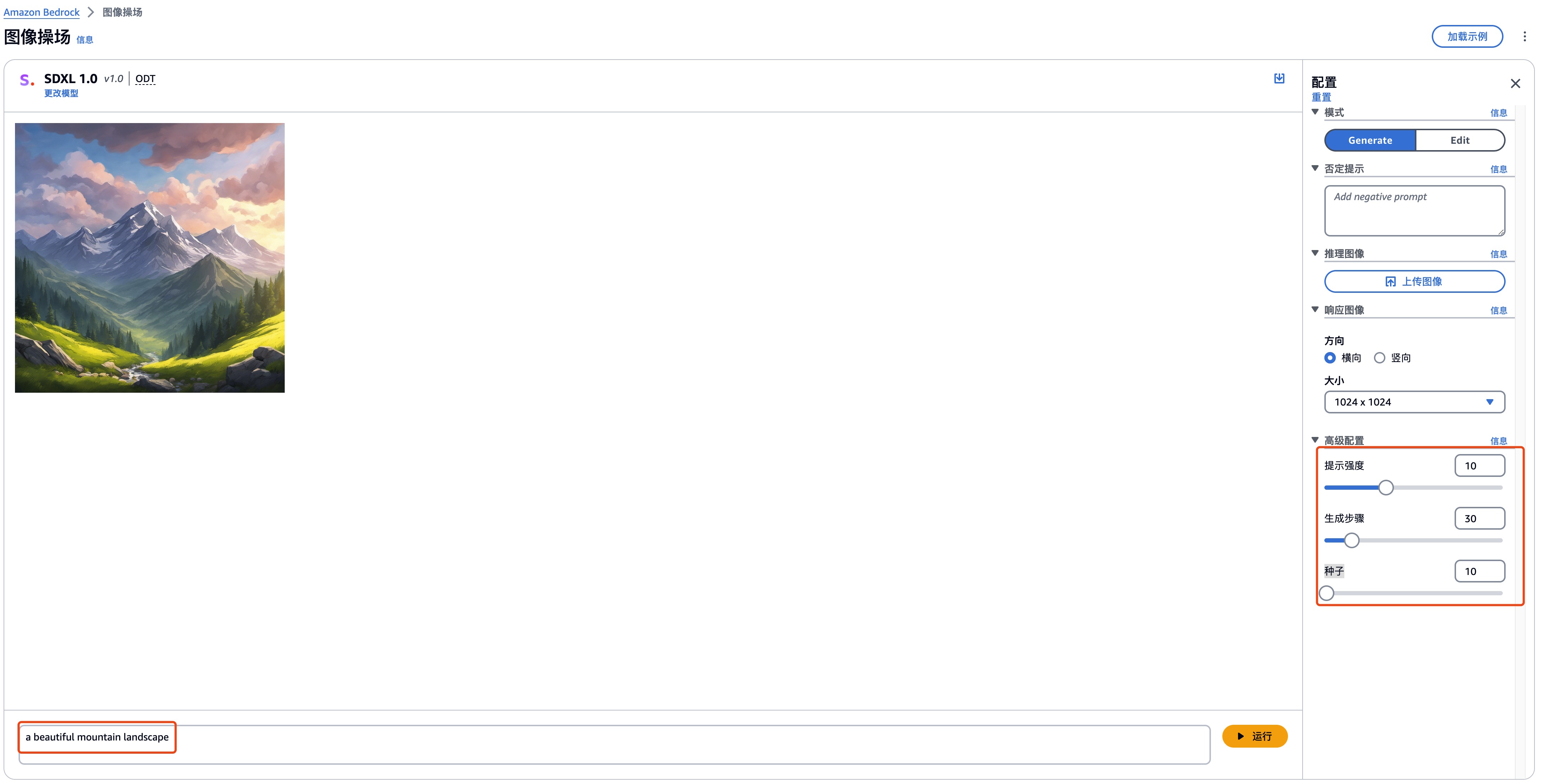
- 文生图
| 操作 | 内容 |
|---|---|
| 提示词 | a beautiful mountain landscape |
| 提示强度 | 10 |
| 生成步骤 | 30 |
| 种子 | 10 |
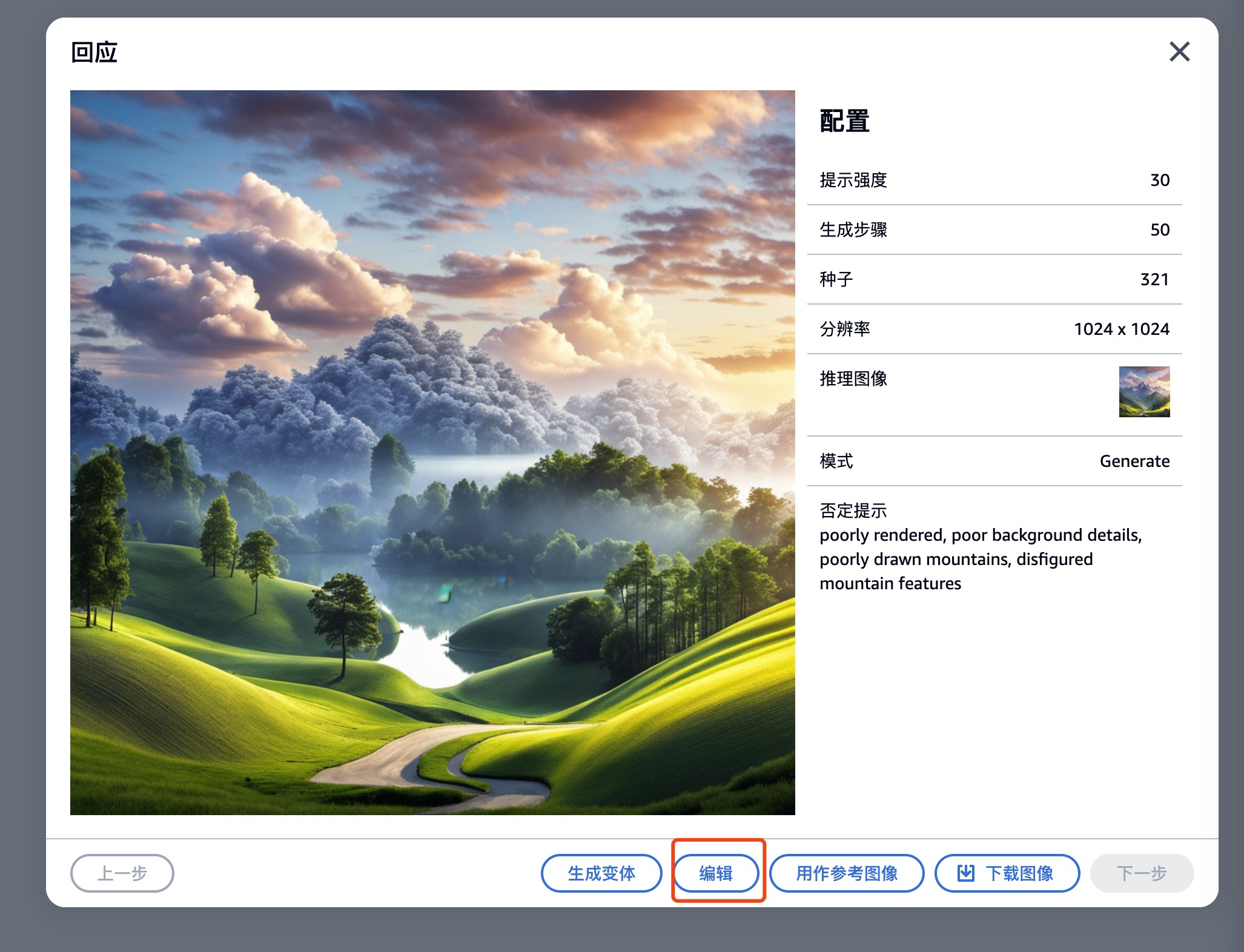
- 图生图
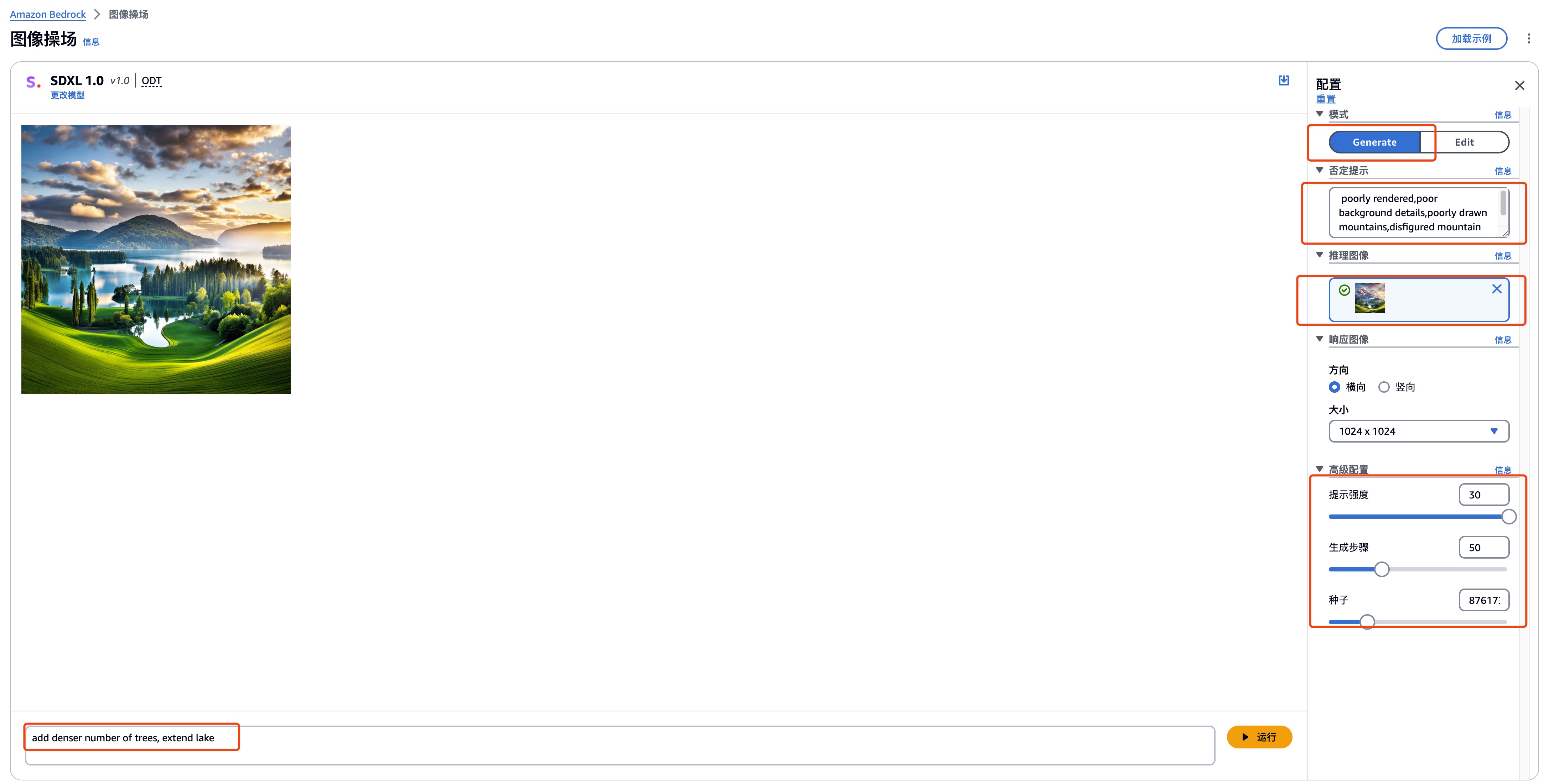
点击图片,选择编辑功能,
从 Edit 模式切换至 Generate 模式
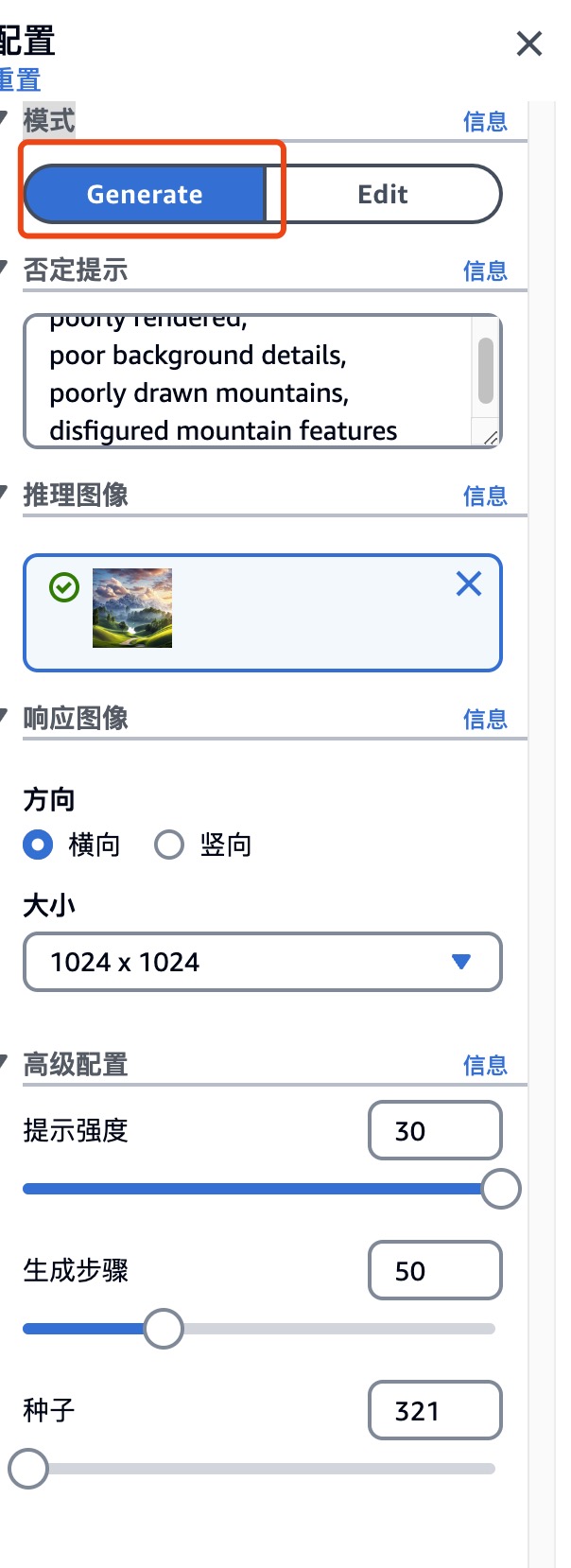
输入提示词、高级配置等
| 操作 | 内容 |
|---|---|
| 提示词 | add denser number of trees, extend lake |
| 负面提示词 | poorly rendered,poor background details,poorly drawn mountains,disfigured mountain features |
| 提示强度 | 30 |
| 生成步骤 | 50 |
| 种子 | 321 |
图生图 运行效果
- 图像编辑
将模式切换至 Edit 模式 并选择需要替换的区域
输入提示词、选择提示强度,生成图片
| 操作 | 内容 |
|---|---|
| 提示词 | add a bird |
| 提示强度 | 10 |
以下为生成的效果图:

通过快速体验 Amazon Bedrock Stability AI SDXL 1.0 文生图、图生图、图像编辑功能,开启简洁高效的视觉创作之旅,让创意变得触手可及。
2、快速体验调用Stability AI API
2.1 使用 Amazon Cloud9 快速体验 Amazon Bedrock 中 Stability AI SDXL 1.0 API 的调用
2.1.1 打开 Amazon Cloud9 实验环境
打开控制台,搜索 Cloud9
选择创建环境
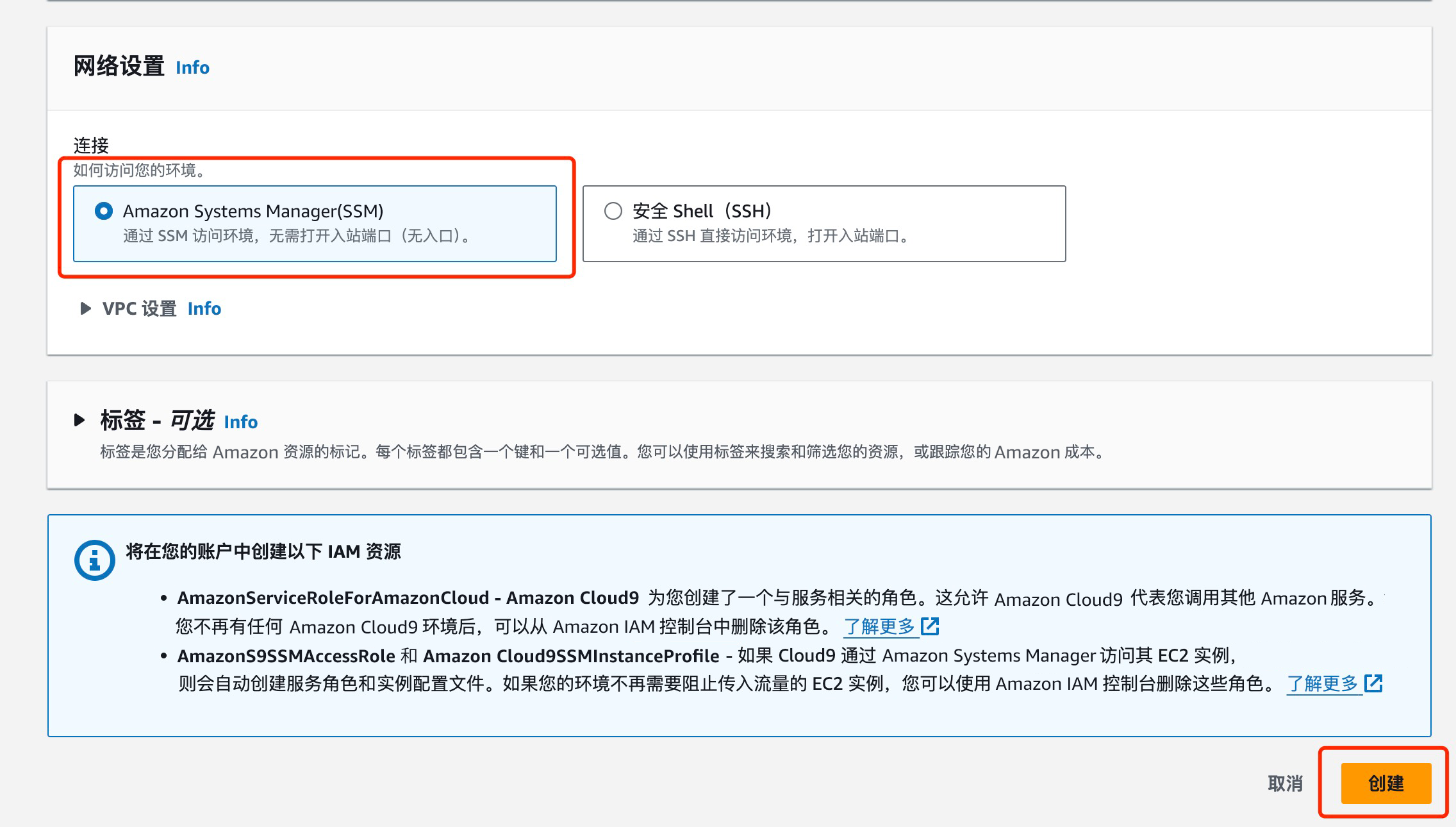
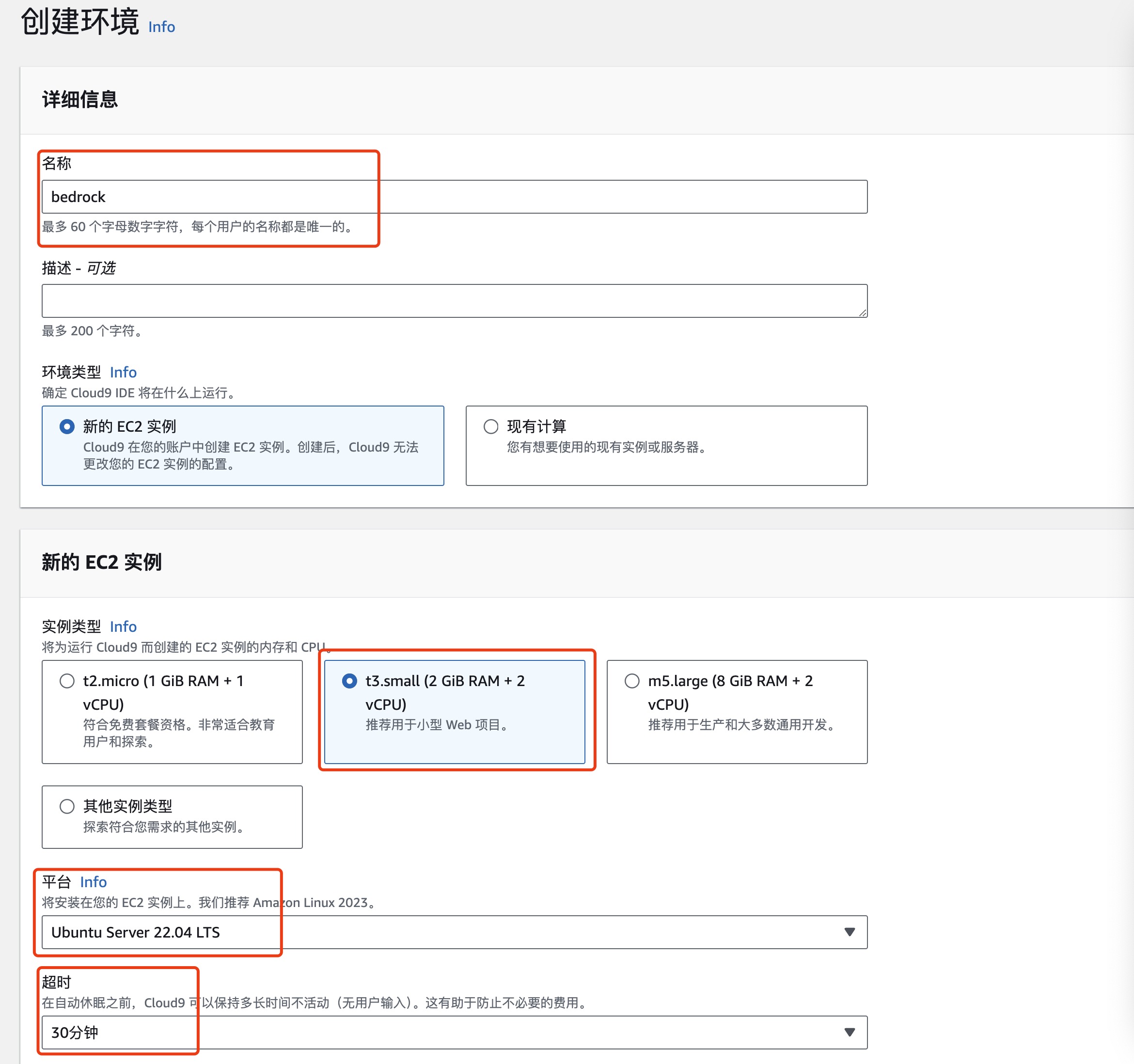
设置环境详细信息
- 设置名称为 bedrock
- 设置实例类型 t3.small
- 平台 Ubuntu Server 22.04 LTS
- 超时 30 分钟
温馨提示:
- 实验环境中仅限选择 Cloud9 EC2 实例为 t3.small (2 GiB RAM + 2 vCPU)
- 基于不浪费的原则,创建 Cloud9 的时候,超时时间只能选择默认的 30 分钟的选项,且 Cloud9 实例数量也将自动审核,如果发现异常会关闭 Cloud9 实例,甚至封禁账号,务必注意文明实验!

2.1.2 熟悉 Amazon Cloud9 实验环境
以下为 Amazon Cloud9 首次打开的界面:
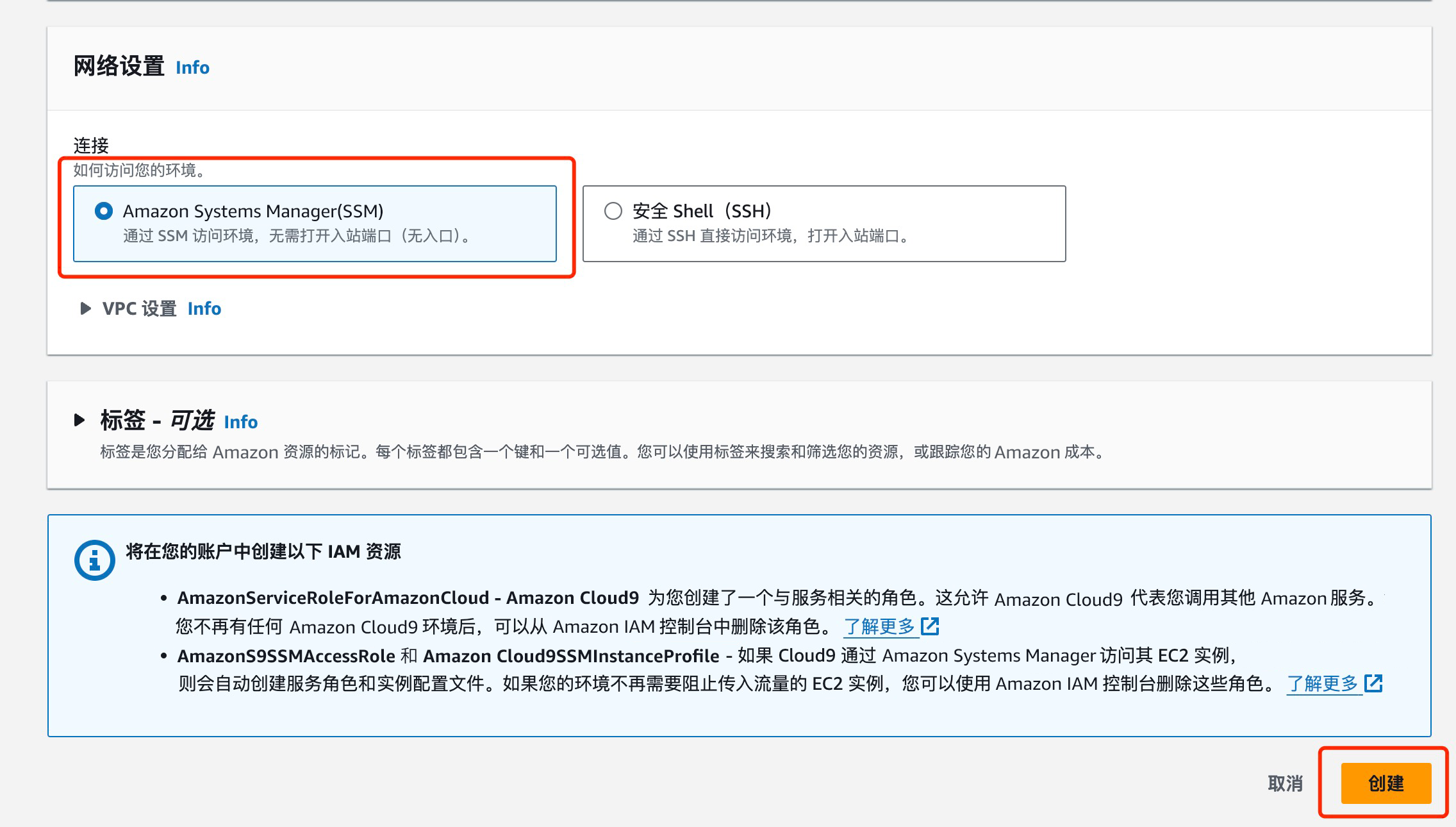
在 Amazon Cloud9 IDE 中,选择 终端

复制以下内容到终端,执行命令,以下载和解压缩代码
cd ~/environment/
curl 'https://dev-media.amazoncloud.cn/doc/workshop.zip' --output workshop.zip
unzip workshop.zip
复制解压完成:
可查看对应的文件目录:
继续使用 终端,安装实验所需的环境依赖项
pip3 install -r ~/environment/workshop/setup/requirements.txt -U
复制
2.1.3 开始编写 Amazon Bedrock 中 Stability AI SDXL 1.0 API
打开 Amazon Bedrock 示例,输入关键字 sdxl,选择 SDXL 1.0,查看 API 请求代码
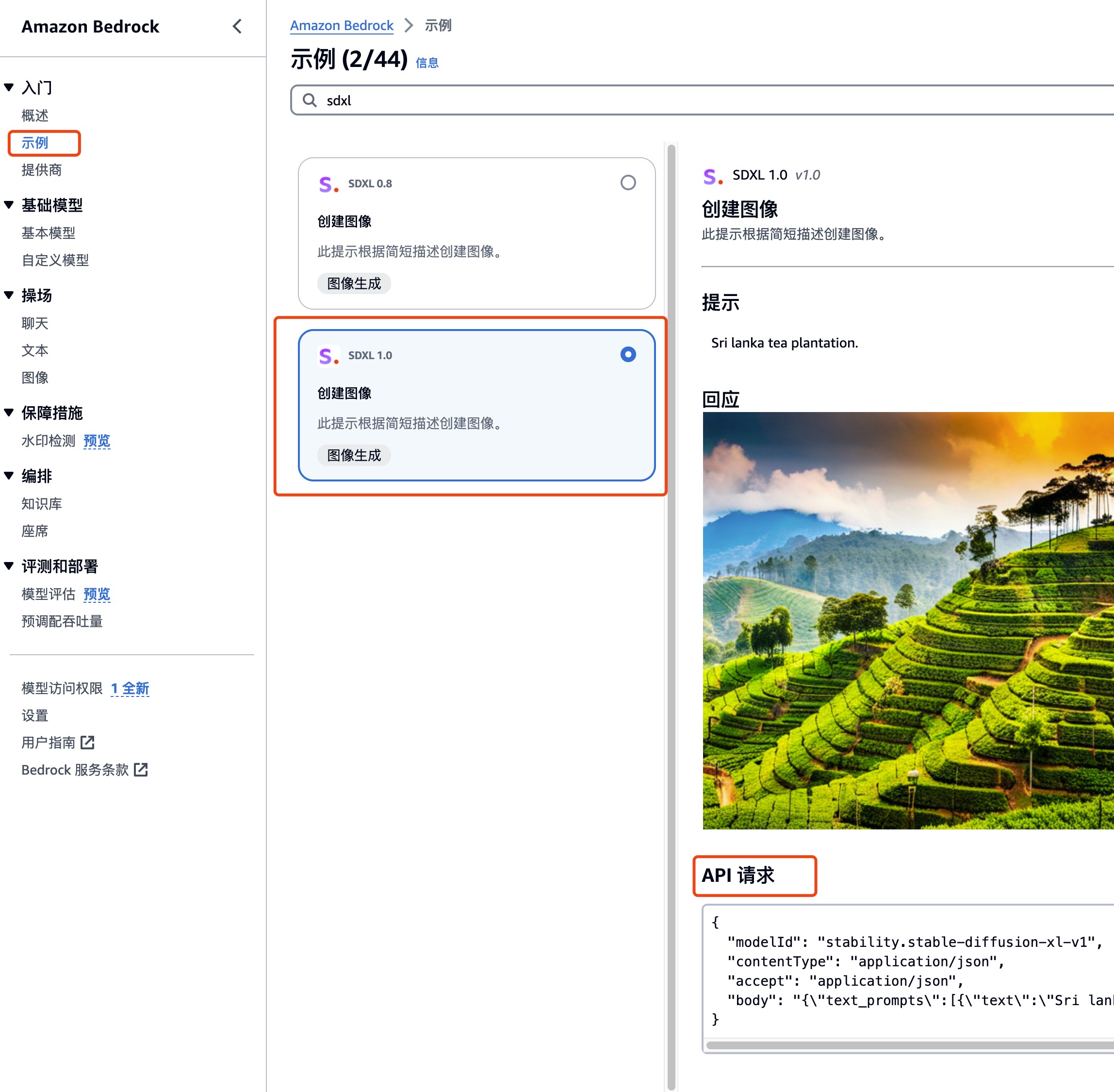
以下为 API 请求代码:
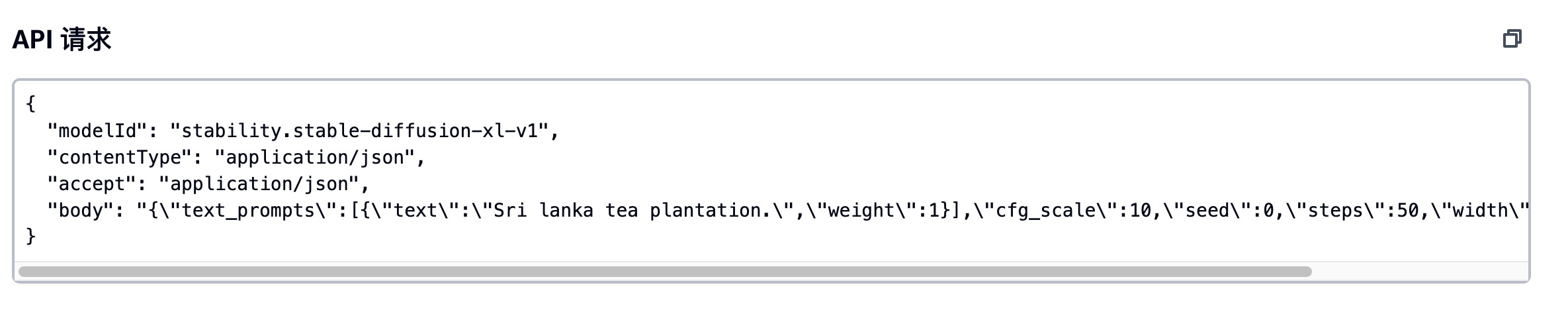
{
"modelId": "stability.stable-diffusion-xl-v0",
"contentType": "application/json",
"accept": "application/json",
"body": "{\"text_prompts\":[{\"text\":\"Sri lanka tea plantation.\",\"weight\":1}],\"cfg_scale\":10,\"seed\":0,\"steps\":50,\"width\":512,\"height\":512}"
}
复制使用 Amazon Cloud9 IDE,选择 workshop/labs/api/bedrock_api.py 编写代码
添加 import 语句,这些语句允许我们使用 Amazon Web Services boto3 库来调用 Amazon Bedrock,使用 base64 进行编码和解码操作,使用 Image 模块处理图像,以及使用 io、os 模块进行文件输入/输出
import json
import boto3
import base64
import os
from PIL import Image
import io
复制初始化 Amazon Bedrock 客户端库
session = boto3.Session()
bedrock = session.client(service_name='bedrock-runtime') #creates a Bedrock client
复制在这里,我们将确定要使用的模型、提示和指定模型的推理参数。
bedrock_model_id = "stability.stable-diffusion-xl-v1" # set the foundation model
prompt = "a beautiful mountain landscape" # the prompt to send to the model
seed = 10
body = json.dumps({
"text_prompts": [{"text": prompt}],
"seed": seed,
"cfg_scale": 10,
"steps": 30,
}) # build the request payload
复制调用 Bedrock API,我们使用 Bedrock 的 invoke_model 函数进行调用。
# send the payload to Bedrock
response = bedrock.invoke_model(
body=body, modelId=bedrock_model_id, accept='application/json', contentType='application/json')
复制从响应中获取图像数据,并将其保存为文件
# read the response
response_body = json.loads(response.get('body').read())
base64_image_data = response_body.get("artifacts")[0]["base64"]
print(f"{base64_image_data[0:80]}...")
# Convert base64 image data to an image and save it to a file
image_data = base64.b64decode(base64_image_data)
os.makedirs("data", exist_ok=True)
image = Image.open(io.BytesIO(image_data))
image.save('data/sd_generated_image.jpg')
复制保存文件,并在命令行处执行代码:
cd ~/environment/workshop/labs/api
复制python3 bedrock_api.py
复制
查看生成的图片:

完整代码:
import json
import boto3
import base64
import os
from PIL import Image
import io
session = boto3.Session()
bedrock = session.client(service_name='bedrock-runtime') # creates a Bedrock client
bedrock_model_id = "stability.stable-diffusion-xl-vl" # set the foundation model
prompt = "a beautiful mountain landscape" # the prompt to send to the model
seed = 100
body = json.dumps({
"text_prompts": [{"text": prompt}],
"seed": seed,
"cfg_scale": 10,
"steps": 30,
}) # build the request payload
# send the payload to Bedrock
response = bedrock.invoke_model(
body=body, modelId=bedrock_model_id, accept='application/json', contentType='application/json')
# read the response
response_body = json.loads(response.get('body').read())
base64_image_data = response_body.get("artifacts")[0]["base64"]
print(f"{base64_image_data[0:80]}...")
# Convert base64 image data to an image and save it to a file
image_data = base64.b64decode(base64_image_data)
os.makedirs("data", exist_ok=True)
image = Image.open(io.BytesIO(image_data))
image.save('data/sd_generated_image.jpg')2.2 使用 Amazon Cloud9 深入体验 Amazon Bedrock 中 Stability AI SDXL 1.0 API 文生图、图生图、图像修复
2.2.1 深入体验 Amazon Bedrock 中 Stability AI SDXL 1.0 文生图 API
查看调用参数配置:
必要参数
| 参数 | 描述 | 最低值 | 最高值 |
|---|---|---|---|
| text_prompts | 生成文本提示数组,包含提示及权重 | 0 | 2000 |
可选参数
| 参数 | 描述 | 默认值 | 最低值 | 最高值 | 可选值 |
|---|---|---|---|---|---|
| weight | 模型应用于提示的权重 | 1 | |||
| cfg_scale | 决定最终图像对提示的描绘程度 | 7 | 0 | 35 | |
| clip_guidance_preset | 预设参数 | FAST_BLUE, FAST_GREEN, NONE, SIMPLE SLOW, SLOWER, SLOWEST | |||
| height | 生成图像的高度 | 1024x1024, 1152x896, 1216x832, 1344x768, 1536x640, 640x1536, 768x1344, 832x1216, 896x1152 | |||
| width | 生成图像的宽度 | 1024x1024, 1152x896, 1216x832, 1344x768, 1536x640, 640x1536, 768x1344, 832x1216, 896x1152 | |||
| sampler | 扩散过程采样器 | DDIM, DDPM, K_DPMPP_2M, K_DPMPP_2S_ANCESTRAL, K_DPM_2, K_DPM_2_ANCESTRAL, K_EULER, K_EULER_ANCESTRAL, K_HEUN, K_LMS | |||
| samples | 要生成的图像数量 | 1 | 1 | 1 | |
| seed | 决定初始噪声设置的种子 | 0 | 0 | 4294967295 | |
| steps | 生成步骤数,影响采样次数和结果准确度 | 30 | 10 | 50 | |
| style_preset | 将图像模型向特定样式引导的样式预设 | 3d-model, analog-film, anime, cinematic, comic-book, digital-art, enhance, fantasy-art, isometric, line-art, low-poly, modeling-compound, neon-punk, origami, photographic, pixel-art, tile-texture | |||
| extras | 传递给引擎的额外参数 |
注意: extras参数是用于开发中或实验性的功能,可能会有变更,所以要谨慎使用。
打开 /workshop/labs/image/image_app.py 文件
编写代码:
引用项目依赖
import base64
import io
import json
import os
import sys
import boto3
from PIL import Image
import botocore
boto3_bedrock = boto3.client('bedrock-runtime')
复制编写提示词、配置输出内容
prompt = "a beautiful mountain landscape" #提示词
negative_prompts = [
"poorly rendered",
"poor background details",
"poorly drawn mountains",
"disfigured mountain features",
]#负向提示词列表,用于指定不希望在生成的图片中出现的特征
style_preset = "photographic" #风格预设,用于指定生成图片的风格。在这里,选择了“photographic”风格,意味着生成的图片将具有类似摄影照片的效果。 (e.g. photographic, digital-art, cinematic, ...)
clip_guidance_preset = "FAST_GREEN" #这是 Clip 引导预设,用于控制图像生成过程中的一些参数和行为。"FAST_GREEN" 是一种预设选项,可能会影响生成速度和结果的某些方面。 (e.g. FAST_BLUE FAST_GREEN NONE SIMPLE SLOW SLOWER SLOWEST)
sampler = "K_DPMPP_2S_ANCESTRAL" # 这是采样器的选择,用于确定在生成图片时使用的采样方法。"K_DPMPP_2S_ANCESTRAL" 是一种具体的采样器,不同的采样器可能会对生成的图片质量和多样性产生影响。(e.g. DDIM, DDPM, K_DPMPP_SDE, K_DPMPP_2M, K_DPMPP_2S_ANCESTRAL, K_DPM_2, K_DPM_2_ANCESTRAL, K_EULER, K_EULER_ANCESTRAL, K_HEUN, K_LMS)
width = 768 #这是设置生成图片的宽度,单位为像素。这里指定宽度为 768 像素
复制调用 API 代码
request = json.dumps({
"text_prompts": (
[{"text": prompt, "weight": 1.0}]
+ [{"text": negprompt, "weight": -1.0} for negprompt in negative_prompts]
),
"cfg_scale": 5,
"seed": 42,
"steps": 60,
"style_preset": style_preset,
"clip_guidance_preset": clip_guidance_preset,
"sampler": sampler,
"width": width,
})
modelId = "stability.stable-diffusion-xl-v1"
response = boto3_bedrock.invoke_model(body=request, modelId=modelId)
response_body = json.loads(response.get("body").read())
print(response_body["result"])
base_64_img_str = response_body["artifacts"][0].get("base64")
print(f"{base_64_img_str[0:80]}...")
复制解析文件并保存图像
os.makedirs("data", exist_ok=True)
image_1 = Image.open(io.BytesIO(base64.decodebytes(bytes(base_64_img_str, "utf-8"))))
image_1.save("data/image_1.jpg")
复制执行脚本
cd ~/environment/workshop/labs/image
python3 image_app.py
复制
图片生成文件夹
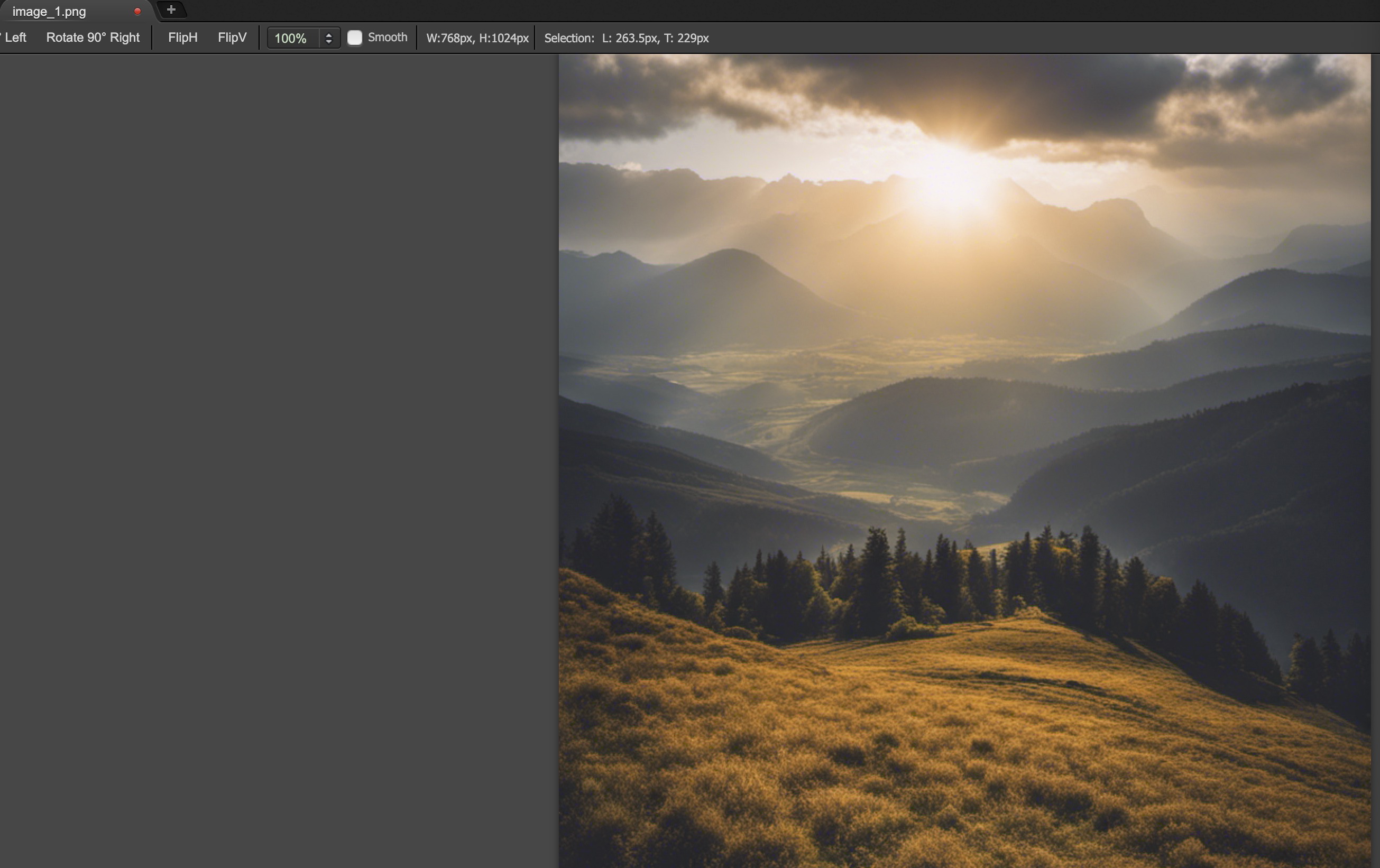
效果
完整代码
import base64
import io
import json
import os
import sys
import boto3
from PIL import Image
import botocore
boto3_bedrock = boto3.client('bedrock-runtime')
prompt = "a beautiful mountain landscape" #提示词
negative_prompts = [
"poorly rendered",
"poor background details",
"poorly drawn mountains",
"disfigured mountain features",
]#负向提示词列表,用于指定不希望在生成的图片中出现的特征
style_preset = "photographic" #风格预设,用于指定生成图片的风格。在这里,选择了“photographic”风格,意味着生成的图片将具有类似摄影照片的效果。 (e.g. photographic, digital-art, cinematic, ...)
clip_guidance_preset = "FAST_GREEN" #这是 Clip 引导预设,用于控制图像生成过程中的一些参数和行为。"FAST_GREEN" 是一种预设选项,可能会影响生成速度和结果的某些方面。 (e.g. FAST_BLUE FAST_GREEN NONE SIMPLE SLOW SLOWER SLOWEST)
sampler = "K_DPMPP_2S_ANCESTRAL" # 这是采样器的选择,用于确定在生成图片时使用的采样方法。"K_DPMPP_2S_ANCESTRAL" 是一种具体的采样器,不同的采样器可能会对生成的图片质量和多样性产生影响。(e.g. DDIM, DDPM, K_DPMPP_SDE, K_DPMPP_2M, K_DPMPP_2S_ANCESTRAL, K_DPM_2, K_DPM_2_ANCESTRAL, K_EULER, K_EULER_ANCESTRAL, K_HEUN, K_LMS)
width = 768 #这是设置生成图片的宽度,单位为像素。这里指定宽度为 768 像素
request = json.dumps({
"text_prompts": (
[{"text": prompt, "weight": 1.0}]
+ [{"text": negprompt, "weight": -1.0} for negprompt in negative_prompts]
),
"cfg_scale": 5,
"seed": 42,
"steps": 60,
"style_preset": style_preset,
"clip_guidance_preset": clip_guidance_preset,
"sampler": sampler,
"width": width,
})
modelId = "stability.stable-diffusion-xl-v1"
response = boto3_bedrock.invoke_model(body=request, modelId=modelId)
response_body = json.loads(response.get("body").read())
print(response_body["result"])
base_64_img_str = response_body["artifacts"][0].get("base64")
print(f"{base_64_img_str[0:80]}...")
os.makedirs("data", exist_ok=True)
image_1 = Image.open(io.BytesIO(base64.decodebytes(bytes(base_64_img_str, "utf-8"))))
image_1.save("data/image_1.jpg")
复制2.2.2 深入体验 Amazon Bedrock 中 Stability AI SDXL 1.0 图生图 API
查看调用参数配置:
必要参数
| 参数 | 描述 | 最低值 | 最高值 |
|---|---|---|---|
| text_prompts | 用于生成的文本提示数组,每个元素都是一个 JSON 对象,其中包含一个提示和该提示的权重 | 0 | 2000 |
| init_image | 要用于初始化扩散过程的 base64 编码图像 |
可选参数
| 参数 | 描述 | 默认值 | 最低值 | 最高值 | 可选值 |
|---|---|---|---|---|---|
| weight | 模型应用于提示的权重,负值代表否定提示 | 1 | |||
| init_image_mode | 确定是使用 image_strength 还是 step_schedule_* 来控制 init_image 中的图像对结果的影响程度 | IMAGE_STRENGTH | IMAGE_STRENGTH, STEP_SCHEDULE | ||
| image_strength | 确定 init_image 中的源图像对扩散过程的影响程度。接近 1 的值会生成与源图像非常相似的图像。接近 0 的值会生成与源图像非常不同的图像 | 0 | 1 | ||
| cfg_scale | 确定最终图像对提示的描绘程度 | 7 | 0 | 35 | |
| clip_guidance_preset | 预设参数,影响模型生成图像流程 | FAST_BLUE, FAST_GREEN, NONE, SIMPLE, SLOW, SLOWER, SLOWEST | |||
| sampler | 扩散过程采样器 | DDIM, DDPM, K_DPMPP_2M, K_DPMPP_2S_ANCESTRAL, K_DPM_2, K_DPM_2_ANCESTRAL, K_EULER, K_EULER_ANCESTRAL, K_HEUN, K_LMS | |||
| samples | 要生成的图像数量 | 1 | 1 | 1 | |
| seed | 决定初始噪声设置的种子 | 0 | 0 | 4294967295 | |
| steps | 生成步骤数,影响采样次数和结果准确度 | 30 | 10 | 50 | |
| style_preset | 将图像模型向特定样式引导的样式预设 | 3d-model, analog-film, anime, cinematic, comic-book, digital-art, enhance, fantasy-art, isometric, line-art, low-poly, modeling-compound, neon-punk, origami, photographic, pixel-art, tile-texture | |||
| extras | 传递给引擎的额外参数 |
打开 /workshop/labs/image_to_image/image_to_image_app.py 文件
开始编写代码
引用项目依赖
import base64
import io
import json
import os
import sys
import boto3
from PIL import Image
import botocore
复制编写图片转换为 base64 的函数
def image_to_base64(img) -> str:
"""Convert a PIL Image or local image file path to a base64 string for Amazon Bedrock"""
if isinstance(img, str):
if os.path.isfile(img):
print(f"Reading image from file: {img}")
with open(img, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
else:
raise FileNotFoundError(f"File {img} does not exist")
elif isinstance(img, Image.Image):
print("Converting PIL Image to base64 string")
buffer = io.BytesIO()
img.save(buffer, format="jpeg")
return base64.b64encode(buffer.getvalue()).decode("utf-8")
else:
raise ValueError(f"Expected str (filename) or PIL Image. Got {type(img)}")
复制打开上部分文生图的照片并转化为 base64
boto3_bedrock = boto3.client('bedrock-runtime')
img_path = '../image/data/image_1.jpg'
# 打开图片
img = Image.open(img_path)
init_image_b64 = image_to_base64(img)
print(init_image_b64[:80] + "...")
复制配置提示词
change_prompt = "add denser number of trees, extend lake"
negative_prompts = [
"poorly rendered",
"poor background details",
"poorly drawn mountains",
"disfigured mountain features",
]#负向提示词列表,用于指定不希望在生成的图片中出现的特征
style_preset = "cinematic" #风格预设,用于指定生成图片的风格。在这里,选择了“photographic”风格,意味着生成的图片将具有类似摄影照片的效果。 (e.g. photographic, digital-art, cinematic, ...)
clip_guidance_preset = "FAST_BLUE" #这是 Clip 引导预设,用于控制图像生成过程中的一些参数和行为。"FAST_GREEN" 是一种预设选项,可能会影响生成速度和结果的某些方面。 (e.g. FAST_BLUE FAST_GREEN NONE SIMPLE SLOW SLOWER SLOWEST)
sampler = "K_DPMPP_2S_ANCESTRAL" # 这是采样器的选择,用于确定在生成图片时使用的采样方法。"K_DPMPP_2S_ANCESTRAL" 是一种具体的采样器,不同的采样器可能会对生成的图片质量和多样性产生影响。(e.g. DDIM, DDPM, K_DPMPP_SDE, K_DPMPP_2M, K_DPMPP_2S_ANCESTRAL, K_DPM_2, K_DPM_2_ANCESTRAL, K_EULER, K_EULER_ANCESTRAL, K_HEUN, K_LMS)
width = 768 #这是设置生成图片的宽度,单位为像素。这里指定宽度为 768 像素
复制构造请求,并在完成请求后并保存图片
request = json.dumps({
"text_prompts": (
[{"text": change_prompt, "weight": 1.0}]
+ [{"text": negprompt, "weight": -1.0} for negprompt in negative_prompts]
),
"cfg_scale": 10,
"init_image": init_image_b64,
"seed": 321,
"start_schedule": 0.6,
"steps": 50,
"style_preset": style_preset,
"clip_guidance_preset": clip_guidance_preset,
"sampler": sampler,
})
modelId = "stability.stable-diffusion-xl-v1"
response = boto3_bedrock.invoke_model(body=request, modelId=modelId)
response_body = json.loads(response.get("body").read())
print(response_body["result"])
image_2_b64_str = response_body["artifacts"][0].get("base64")
print(f"{image_2_b64_str[0:80]}...")
os.makedirs("data", exist_ok=True)
image_2 = Image.open(io.BytesIO(base64.decodebytes(bytes(image_2_b64_str, "utf-8"))))
image_2.save("data/image_2.jpg")
复制保存文件,并在命令行处执行代码
cd ~/environment/workshop/labs/image_to_image
python3 image_to_image_app.py
复制
图片生成路径
查看效果

完整代码
import base64
import io
import json
import os
import sys
import boto3
from PIL import Image
import botocore
def image_to_base64(img) -> str:
"""Convert a PIL Image or local image file path to a base64 string for Amazon Bedrock"""
if isinstance(img, str):
if os.path.isfile(img):
print(f"Reading image from file: {img}")
with open(img, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
else:
raise FileNotFoundError(f"File {img} does not exist")
elif isinstance(img, Image.Image):
print("Converting PIL Image to base64 string")
buffer = io.BytesIO()
img.save(buffer, format="jpeg")
return base64.b64encode(buffer.getvalue()).decode("utf-8")
else:
raise ValueError(f"Expected str (filename) or PIL Image. Got {type(img)}")
boto3_bedrock = boto3.client('bedrock-runtime')
img_path = '../image/data/image_1.jpg'
# 打开图片
img = Image.open(img_path)
init_image_b64 = image_to_base64(img)
print(init_image_b64[:80] + "...")
change_prompt = "add denser number of trees, extend lake"
negative_prompts = [
"poorly rendered",
"poor background details",
"poorly drawn mountains",
"disfigured mountain features",
]#负向提示词列表,用于指定不希望在生成的图片中出现的特征
style_preset = "cinematic" #风格预设,用于指定生成图片的风格。在这里,选择了“photographic”风格,意味着生成的图片将具有类似摄影照片的效果。 (e.g. photographic, digital-art, cinematic, ...)
clip_guidance_preset = "FAST_BLUE" #这是 Clip 引导预设,用于控制图像生成过程中的一些参数和行为。"FAST_GREEN" 是一种预设选项,可能会影响生成速度和结果的某些方面。 (e.g. FAST_BLUE FAST_GREEN NONE SIMPLE SLOW SLOWER SLOWEST)
sampler = "K_DPMPP_2S_ANCESTRAL" # 这是采样器的选择,用于确定在生成图片时使用的采样方法。"K_DPMPP_2S_ANCESTRAL" 是一种具体的采样器,不同的采样器可能会对生成的图片质量和多样性产生影响。(e.g. DDIM, DDPM, K_DPMPP_SDE, K_DPMPP_2M, K_DPMPP_2S_ANCESTRAL, K_DPM_2, K_DPM_2_ANCESTRAL, K_EULER, K_EULER_ANCESTRAL, K_HEUN, K_LMS)
width = 768 #这是设置生成图片的宽度,单位为像素。这里指定宽度为 768 像素
request = json.dumps({
"text_prompts": (
[{"text": change_prompt, "weight": 1.0}]
+ [{"text": negprompt, "weight": -1.0} for negprompt in negative_prompts]
),
"cfg_scale": 10,
"init_image": init_image_b64,
"seed": 321,
"start_schedule": 0.6,
"steps": 50,
"style_preset": style_preset,
"clip_guidance_preset": clip_guidance_preset,
"sampler": sampler,
})
modelId = "stability.stable-diffusion-xl-v1"
response = boto3_bedrock.invoke_model(body=request, modelId=modelId)
response_body = json.loads(response.get("body").read())
print(response_body["result"])
image_2_b64_str = response_body["artifacts"][0].get("base64")
print(f"{image_2_b64_str[0:80]}...")
os.makedirs("data", exist_ok=True)
image_2 = Image.open(io.BytesIO(base64.decodebytes(bytes(image_2_b64_str, "utf-8"))))
image_2.save("data/image_2.jpg")
复制2.2.3 深入体验 Amazon Bedrock 中 Stability AI SDXL 1.0 图像修复 API
修改图像的一种方法是使用“修复”。修复是指根据文本提示将图像的一部分替换为另一个图像的过程。通过提供概述要替换的部分的蒙版图像、文本提示和图像,Stable Diffusion 模型可以生成一个新图像,将蒙版区域替换为文本提示中描述的对象、主题或环境。
查看调用参数配置:
必要参数
| 参数 | 描述 | 最低值 | 最高值 |
|---|---|---|---|
| text_prompt | 用于生成的文本提示数组 | 0 | 2000 |
| init_image | 初始化扩散过程的base64编码图像 | ||
| mask_source | 确定蒙版来源 | ||
| mask_image | 用作init_image中源图像蒙版的base64编码 |
必要参数的mask_source选项
| 可选值 | 描述 |
|---|---|
| MASK_IMAGE_WHITE | 使用mask_image中蒙版图像的白色像素作为蒙版 |
| MASK_IMAGE_BLACK | 使用mask_image中蒙版图像的黑色像素作为蒙版 |
| INIT_IMAGE_ALPHA | 使用init_image中图像的Alpha通道作为蒙版 |
可选参数
| 参数 | 默认值 | 最低值 | 最高值 | 描述和可选值 |
|---|---|---|---|---|
| weight | 1 | 模型应用于提示的权重。 | ||
| cfg_scale | 7 | 0 | 35 | 确定最终图像对提示的描绘程度。 |
| clip_guidance_preset | 模型生成图像流程的预设参数。可选值:FAST_BLUE, FAST_GREEN, NONE, SIMPLE, SLOW, SLOWER, SLOWEST。 | |||
| sampler | 扩散过程的采样器。可选值:DDIM, DDPM, K_DPMPP_2M, K_DPMPP_2S_ANCESTRAL, K_DPM_2, K_DPM_2_ANCESTRAL, K_EULER, K_EULER_ANCESTRAL, K_HEUN, K_LMS。 | |||
| samples | 1 | 1 | 1 | 生成图像的数量。 |
| seed | 0 | 0 | 4294967295 | 初始化噪声设置的种子。 |
| steps | 30 | 10 | 50 | 对图像进行采样的生成步骤数。 |
| style_preset | 图像模型特定样式的预设。可选值:3d-model, analog-film, anime, cinematic, comic-book, digital-art, enhance, fantasy-art, isometric, line-art, low-poly, modeling-compound, neon-punk, origami, photographic, pixel-art, tile-texture。 | |||
| extras | 引擎的额外参数。注意:'extras'参数用于开发中或实验性功能,可能会有变更,应谨慎使用。 |
打开 /workshop/labs/image_insertion/image_insertion_app.py 文件
开始编写代码
引用项目依赖
import base64
import io
import json
import os
import sys
import boto3
from PIL import Image
import botocore
from PIL import ImageOps
复制编写图片转换为 base64 的函数
def image_to_base64(img) -> str:
"""Convert a PIL Image or local image file path to a base64 string for Amazon Bedrock"""
if isinstance(img, str):
if os.path.isfile(img):
print(f"Reading image from file: {img}")
with open(img, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
else:
raise FileNotFoundError(f"File {img} does not exist")
elif isinstance(img, Image.Image):
print("Converting PIL Image to base64 string")
buffer = io.BytesIO()
img.save(buffer, format="jpeg")
return base64.b64encode(buffer.getvalue()).decode("utf-8")
else:
raise ValueError(f"Expected str (filename) or PIL Image. Got {type(img)}")
复制编写绘制蒙版图像的代码(这里,也可以指定为某张图片)
def inpaint_mask(img, box):
"""Generates a segmentation mask for inpainting"""
img_size = img.size
assert len(box) == 4 # (left, top, right, bottom)
assert box[0] < box[2]
assert box[1] < box[3]
return ImageOps.expand(
Image.new(
mode = "RGB",
size = (
box[2] - box[0],
box[3] - box[1]
),
color = 'black'
),
border=(
box[0],
box[1],
img_size[0] - box[2],
img_size[1] - box[3]
),
fill='white'
)
复制打开上一张已经生成好的图片,并选择蒙版图像的区域
img_path = '../image_to_image/data/image_2.jpg'
# 打开图片
image_2 = Image.open(img_path)
img2_size = image_2.size
box = (
(0),
(img2_size[1] - 900) ,
(img2_size[0]),
img2_size[1] - 700
)
# Mask
mask = inpaint_mask(
image_2,
box
)
# Debug
mask
复制现在,我们将定义要在图像中更改的内容
boto3_bedrock = boto3.client('bedrock-runtime')
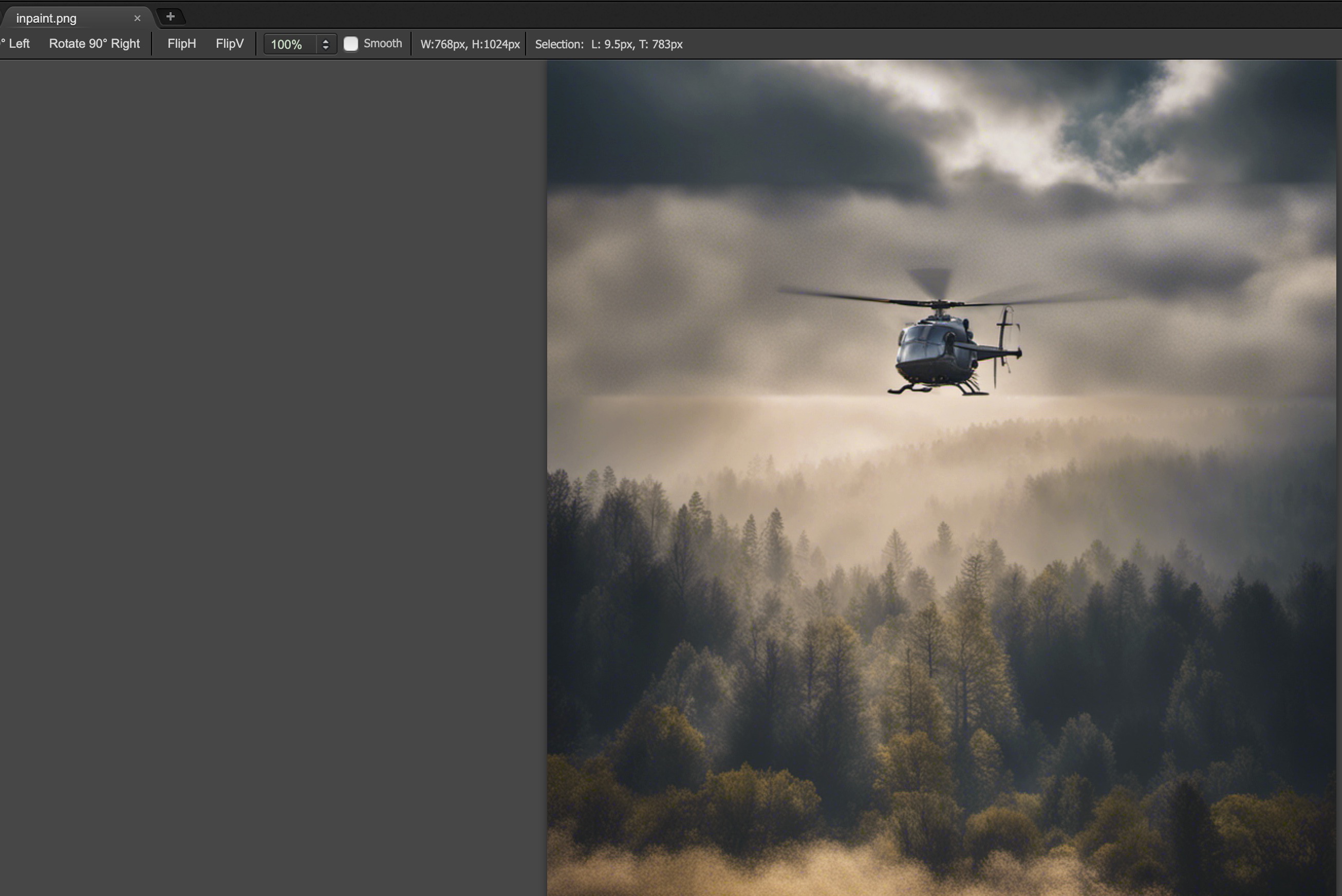
inpaint_prompt = "add a helicopter"#添加一架直升机
style_preset = "cinematic" #风格预设,用于指定生成图片的风格。在这里,选择了“photographic”风格,意味着生成的图片将具有类似摄影照片的效果。 (e.g. photographic, digital-art, cinematic, ...)
clip_guidance_preset = "FAST_BLUE" #这是 Clip 引导预设,用于控制图像生成过程中的一些参数和行为。"FAST_GREEN" 是一种预设选项,可能会影响生成速度和结果的某些方面。 (e.g. FAST_BLUE FAST_GREEN NONE SIMPLE SLOW SLOWER SLOWEST)
sampler = "K_DPMPP_2S_ANCESTRAL" # 这是采样器的选择,用于确定在生成图片时使用的采样方法。"K_DPMPP_2S_ANCESTRAL" 是一种具体的采样器,不同的采样器可能会对生成的图片质量和多样性产生影响。(e.g. DDIM, DDPM, K_DPMPP_SDE, K_DPMPP_2M, K_DPMPP_2S_ANCESTRAL, K_DPM_2, K_DPM_2_ANCESTRAL, K_EULER, K_EULER_ANCESTRAL, K_HEUN, K_LMS)
width = 768 #这是设置生成图片的宽度,单位为像素。这里指定宽度为 768 像素
request = json.dumps({
"text_prompts":[{"text": inpaint_prompt}],
"init_image": image_to_base64(image_2),
"mask_source": "MASK_IMAGE_BLACK",
"mask_image": image_to_base64(mask),
"cfg_scale": 10,
"seed": 32123,
"style_preset": style_preset,
})
复制构造请求,并在完成请求后并保存图片
modelId = "stability.stable-diffusion-xl-v1"
response = boto3_bedrock.invoke_model(body=request, modelId=modelId)
response_body = json.loads(response.get("body").read())
print(response_body["result"])
image_3_b64_str = response_body["artifacts"][0].get("base64")
os.makedirs("data", exist_ok=True)
inpaint = Image.open(io.BytesIO(base64.decodebytes(bytes(image_3_b64_str, "utf-8"))))
inpaint.save("data/inpaint.jpg")
复制保存文件,并在命令行处执行代码
cd ~/environment/workshop/labs/image_insertion
python3 image_insertion_app.py
复制
图片生成路径
查看效果
完整代码
import base64
import io
import json
import os
import sys
import boto3
from PIL import Image
import botocore
from PIL import ImageOps
def image_to_base64(img) -> str:
"""Convert a PIL Image or local image file path to a base64 string for Amazon Bedrock"""
if isinstance(img, str):
if os.path.isfile(img):
print(f"Reading image from file: {img}")
with open(img, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
else:
raise FileNotFoundError(f"File {img} does not exist")
elif isinstance(img, Image.Image):
print("Converting PIL Image to base64 string")
buffer = io.BytesIO()
img.save(buffer, format="jpeg")
return base64.b64encode(buffer.getvalue()).decode("utf-8")
else:
raise ValueError(f"Expected str (filename) or PIL Image. Got {type(img)}")
def inpaint_mask(img, box):
"""Generates a segmentation mask for inpainting"""
img_size = img.size
assert len(box) == 4 # (left, top, right, bottom)
assert box[0] < box[2]
assert box[1] < box[3]
return ImageOps.expand(
Image.new(
mode = "RGB",
size = (
box[2] - box[0],
box[3] - box[1]
),
color = 'black'
),
border=(
box[0],
box[1],
img_size[0] - box[2],
img_size[1] - box[3]
),
fill='white'
)
img_path = '../image_to_image/data/image_2.jpg'
# 打开图片
image_2 = Image.open(img_path)
img2_size = image_2.size
box = (
(0),
(img2_size[1] - 900) ,
(img2_size[0]),
img2_size[1] - 700
)
# Mask
mask = inpaint_mask(
image_2,
box
)
# Debug
mask
boto3_bedrock = boto3.client('bedrock-runtime')
inpaint_prompt = "add a helicopter"#添加一架直升机
style_preset = "cinematic" #风格预设,用于指定生成图片的风格。在这里,选择了“photographic”风格,意味着生成的图片将具有类似摄影照片的效果。 (e.g. photographic, digital-art, cinematic, ...)
clip_guidance_preset = "FAST_BLUE" #这是 Clip 引导预设,用于控制图像生成过程中的一些参数和行为。"FAST_GREEN" 是一种预设选项,可能会影响生成速度和结果的某些方面。 (e.g. FAST_BLUE FAST_GREEN NONE SIMPLE SLOW SLOWER SLOWEST)
sampler = "K_DPMPP_2S_ANCESTRAL" # 这是采样器的选择,用于确定在生成图片时使用的采样方法。"K_DPMPP_2S_ANCESTRAL" 是一种具体的采样器,不同的采样器可能会对生成的图片质量和多样性产生影响。(e.g. DDIM, DDPM, K_DPMPP_SDE, K_DPMPP_2M, K_DPMPP_2S_ANCESTRAL, K_DPM_2, K_DPM_2_ANCESTRAL, K_EULER, K_EULER_ANCESTRAL, K_HEUN, K_LMS)
width = 768 #这是设置生成图片的宽度,单位为像素。这里指定宽度为 768 像素
request = json.dumps({
"text_prompts":[{"text": inpaint_prompt}],
"init_image": image_to_base64(image_2),
"mask_source": "MASK_IMAGE_BLACK",
"mask_image": image_to_base64(mask),
"cfg_scale": 10,
"seed": 32123,
"style_preset": style_preset,
})
modelId = "stability.stable-diffusion-xl-v1"
response = boto3_bedrock.invoke_model(body=request, modelId=modelId)
response_body = json.loads(response.get("body").read())
print(response_body["result"])
image_3_b64_str = response_body["artifacts"][0].get("base64")
os.makedirs("data", exist_ok=True)
inpaint = Image.open(io.BytesIO(base64.decodebytes(bytes(image_3_b64_str, "utf-8"))))
inpaint.save("data/inpaint.jpg")
复制3、使用 Amazon Cloud9 调用 Amazon Bedrock 中 Stability AI SDXL 1.0 API 生成应用
3.1 使用 Amazon Bedrock 中 Stability AI SDXL 1.0 streamlit API 创建个人绘画应用
3.1.1 打开 Amazon Cloud9 实验环境
打开 /workshop/labs/intro_streaming/intro_streaming.py 文件
3.1.2 编写依赖、相关配置信息代码
编写项目所需要的依赖
import streamlit as st
from PIL import Image
import base64
import boto3
import io
import json
import os
复制配置相关的提示词、风格等信息
常用参数一览表
| 参数 | 解释 |
|---|---|
| height | 生成图像的高度 |
| width | 生成图像的宽度 |
| text_prompts | 数组形式的文本提示 |
| cfg_scale | 控制扩散过程对提示文本的遵循程度 |
| clip_guidance_preset | 采样的预设模式 |
| sampler | 用于选择扩散过程使用的算法 |
| seed | 随机噪声种子 |
| steps | 扩散过程的运行次数 |
| style_preset | 引导图像模型走向特定风格的预设 |
| extras | 传递给引擎的其他实验性功能 |
DEBUG = os.getenv("DEBUG", False)
DEFAULT_SEED = os.getenv("DEFAULT_SEED", 12345)
MAX_SEED = 4294967295
MODEL_ID = "stability.stable-diffusion-xl-v1"
NEGATIVE_PROMPTS = [
"bad anatomy", "distorted", "blurry",
"pixelated", "dull", "unclear",
"poorly rendered",
"poorly Rendered face",
"poorly drawn face",
"poor facial details",
"poorly drawn hands",
"poorly rendered hands",
"low resolution",
"Images cut out at the top, left, right, bottom.",
"bad composition",
"mutated body parts",
"blurry image",
"disfigured",
"oversaturated",
"bad anatomy",
"deformed body features",
]
STYLES_MAP = {
"电影感(Cinematic)": "cinematic",
"摄影(Photographic)": "photographic",
"漫画(Comic Book)": "comic-book",
"折纸(Origami)": "origami",
"模拟胶片(Analog Film)": "analog-film",
"幻想艺术(Fantasy Art)": "fantasy-art",
"线条艺术(Line Art)": "line-art",
"霓虹朋克粉(Neon Punk)": "neon-punk",
"三维模型(3D Model)": "3d-model",
"数码艺术(Digital Art)": "digital-art",
"增强(Enhance)": "enhance",
"像素艺术(Pixel Art)": "pixel-art",
"瓷砖纹理(Tile Texture)": "tile-texture",
"无(None)": "None",
}
复制3.1.3 编写调用 API 的函数代码
编写调用 API 的等函数
bedrock_runtime = boto3.client('bedrock-runtime')
@st.cache_data(show_spinner=False)
def gen_img_from_bedrock(prompt, style, seed=DEFAULT_SEED,width=512,height=512):
body = json.dumps({
"text_prompts": [
{
"text": prompt
}
],
"cfg_scale": 10,
"seed": seed,
"steps": 50,
"style_preset": style,
"negative_prompts": NEGATIVE_PROMPTS,
"width":width,
"height":height
})
accept = "application/json"
contentType = "application/json"
response = bedrock_runtime.invoke_model(
body=body, modelId=MODEL_ID, accept=accept, contentType=contentType
)
response_body = json.loads(response.get("body").read())
image_bytes = response_body.get("artifacts")[0].get("base64")
image_data = base64.b64decode(image_bytes.encode())
st.session_state['image_data'] = image_data
return image_data
复制其他函数
def update_slider():
st.session_state.slider = st.session_state.numeric
def update_numin():
st.session_state.numeric = st.session_state.slider
@st.cache_data
def get_image(image_data):
return Image.open(io.BytesIO(image_data))
复制3.1.4 编写主函数代码
主函数 界面部分
if __name__ == '__main__':
# Create the page title
st.set_page_config(
page_title='Amazon Bedrock Stable Diffusion', page_icon='./bedrock.png')
st.title('Stable Diffusion Image Generator with Amazon Bedrock')
# Create a sidebar with text examples
with st.sidebar:
# Selectbox
style_key = st.sidebar.selectbox(
"Choose image style",
STYLES_MAP.keys(),
index=0)
seed_input = st.sidebar.number_input(
"Seed", value=DEFAULT_SEED, placeholder=DEFAULT_SEED, key="numeric", on_change=update_slider)
seed_slider = st.sidebar.slider(
'Seed Slider', min_value=0, value=seed_input, max_value=MAX_SEED, step=1, key="slider",
on_change=update_numin, label_visibility="hidden")
seed = seed_input | seed_slider
# 图片宽度
width = st.sidebar.slider(
'Width', min_value=256, value=512, max_value=1024, step=64, key="width_slider")
# 图片高度
height = st.sidebar.slider(
'Height', min_value=256, value=512, max_value=1024, step=64, key="height_slider")
复制主函数 调用 API 部分
prompt = st.text_input('Input your prompt')
if not prompt:
st.warning("Please input a prompt")
# Block the image generation if there is no input prompt
st.stop()
if st.button("Generate", type="primary"):
if len(prompt) > 0:
st.markdown(f"""
This will show an image using **Stable Diffusion** with your desired prompt entered : {prompt}
""")
# Create a spinner to show the image is being generated
with st.spinner('Generating image based on prompt'):
if not DEBUG:
style = STYLES_MAP[style_key]
print("Generate image with Style:{} with Seed:{} and Width:{} and Height:{} and Prompt: {}".format(
style_key, seed, width , height , prompt))
# Send request to Bedrock
image_data = gen_img_from_bedrock(
prompt=prompt, style=style, seed=seed,width=width,height=height)
st.success('Generated stable diffusion image')
if st.session_state.get("image_data", None):
image = get_image(st.session_state.image_data)
st.image(image)
if DEBUG:
st.write(st.session_state)
复制3.1.5 保存文件并使用应用
保存文件,并在命令行处执行代码
cd ~/environment/workshop/labs/intro_streaming/
streamlit run intro_streaming.py --server.port 8080
复制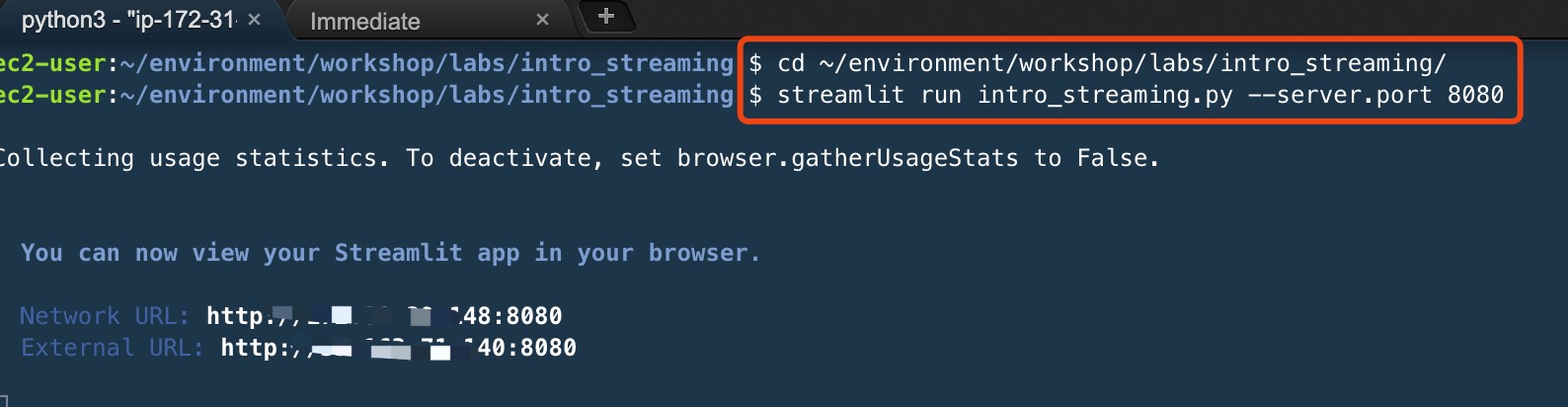
在 Amazon Cloud9 中,选择预览 -> 预览正在运行的应用程序

在预览窗口中,就可以开始运行应用啦

注意:Ctrl+C 可以关停服务

完整代码:
import streamlit as st
from PIL import Image
import base64
import boto3
import io
import json
import os
DEBUG = os.getenv("DEBUG", False)
DEFAULT_SEED = os.getenv("DEFAULT_SEED", 12345)
MAX_SEED = 4294967295
MODEL_ID = "stability.stable-diffusion-xl-v1"
NEGATIVE_PROMPTS = [
"bad anatomy", "distorted", "blurry",
"pixelated", "dull", "unclear",
"poorly rendered",
"poorly Rendered face",
"poorly drawn face",
"poor facial details",
"poorly drawn hands",
"poorly rendered hands",
"low resolution",
"Images cut out at the top, left, right, bottom.",
"bad composition",
"mutated body parts",
"blurry image",
"disfigured",
"oversaturated",
"bad anatomy",
"deformed body features",
]
STYLES_MAP = {
"电影感(Cinematic)": "cinematic",
"摄影(Photographic)": "photographic",
"漫画(Comic Book)": "comic-book",
"折纸(Origami)": "origami",
"模拟胶片(Analog Film)": "analog-film",
"幻想艺术(Fantasy Art)": "fantasy-art",
"线条艺术(Line Art)": "line-art",
"霓虹朋克粉(Neon Punk)": "neon-punk",
"三维模型(3D Model)": "3d-model",
"数码艺术(Digital Art)": "digital-art",
"增强(Enhance)": "enhance",
"像素艺术(Pixel Art)": "pixel-art",
"瓷砖纹理(Tile Texture)": "tile-texture",
"无(None)": "None",
}
bedrock_runtime = boto3.client('bedrock-runtime')
@st.cache_data(show_spinner=False)
def gen_img_from_bedrock(prompt, style, seed=DEFAULT_SEED,width=512,height=512):
body = json.dumps({
"text_prompts": [
{
"text": prompt
}
],
"cfg_scale": 10,
"seed": seed,
"steps": 50,
"style_preset": style,
"negative_prompts": NEGATIVE_PROMPTS,
"width":width,
"height":height
})
accept = "application/json"
contentType = "application/json"
response = bedrock_runtime.invoke_model(
body=body, modelId=MODEL_ID, accept=accept, contentType=contentType
)
response_body = json.loads(response.get("body").read())
image_bytes = response_body.get("artifacts")[0].get("base64")
image_data = base64.b64decode(image_bytes.encode())
st.session_state['image_data'] = image_data
return image_data
def update_slider():
st.session_state.slider = st.session_state.numeric
def update_numin():
st.session_state.numeric = st.session_state.slider
@st.cache_data
def get_image(image_data):
return Image.open(io.BytesIO(image_data))
if __name__ == '__main__':
# Create the page title
st.set_page_config(
page_title='Amazon Bedrock Stable Diffusion', page_icon='./bedrock.png')
st.title('Stable Diffusion Image Generator with Amazon Bedrock')
# Create a sidebar with text examples
with st.sidebar:
# Selectbox
style_key = st.sidebar.selectbox(
"Choose image style",
STYLES_MAP.keys(),
index=0)
seed_input = st.sidebar.number_input(
"Seed", value=DEFAULT_SEED, placeholder=DEFAULT_SEED, key="numeric", on_change=update_slider)
seed_slider = st.sidebar.slider(
'Seed Slider', min_value=0, value=seed_input, max_value=MAX_SEED, step=1, key="slider",
on_change=update_numin, label_visibility="hidden")
seed = seed_input | seed_slider
# 图片宽度
width = st.sidebar.slider(
'Width', min_value=256, value=512, max_value=1024, step=64, key="width_slider")
# 图片高度
height = st.sidebar.slider(
'Height', min_value=256, value=512, max_value=1024, step=64, key="height_slider")
prompt = st.text_input('Input your prompt')
if not prompt:
st.warning("Please input a prompt")
# Block the image generation if there is no input prompt
st.stop()
if st.button("Generate", type="primary"):
if len(prompt) > 0:
st.markdown(f"""
This will show an image using **Stable Diffusion** with your desired prompt entered : {prompt}
""")
# Create a spinner to show the image is being generated
with st.spinner('Generating image based on prompt'):
if not DEBUG:
style = STYLES_MAP[style_key]
print("Generate image with Style:{} with Seed:{} and Width:{} and Height:{} and Prompt: {}".format(
style_key, seed, width , height , prompt))
# Send request to Bedrock
image_data = gen_img_from_bedrock(
prompt=prompt, style=style, seed=seed,width=width,height=height)
st.success('Generated stable diffusion image')
if st.session_state.get("image_data", None):
image = get_image(st.session_state.image_data)
st.image(image)
if DEBUG:
st.write(st.session_state)
复制
总结
在实验一中,我们使用了 Amazon Bedrock,上掌握 Stable Diffusion AI SDXL 1.0 运行环境创造独特艺术风格的图像,接下来点击下一页,开始实验二,在 Amazon Bedrock 上掌握 Meta Llama 3:快速轻松地构建基于生成式人工智能的体验。
应用二:快速轻松地感受生成式人工智能构建体验
1、快速体验 Meta Llama 3 模型
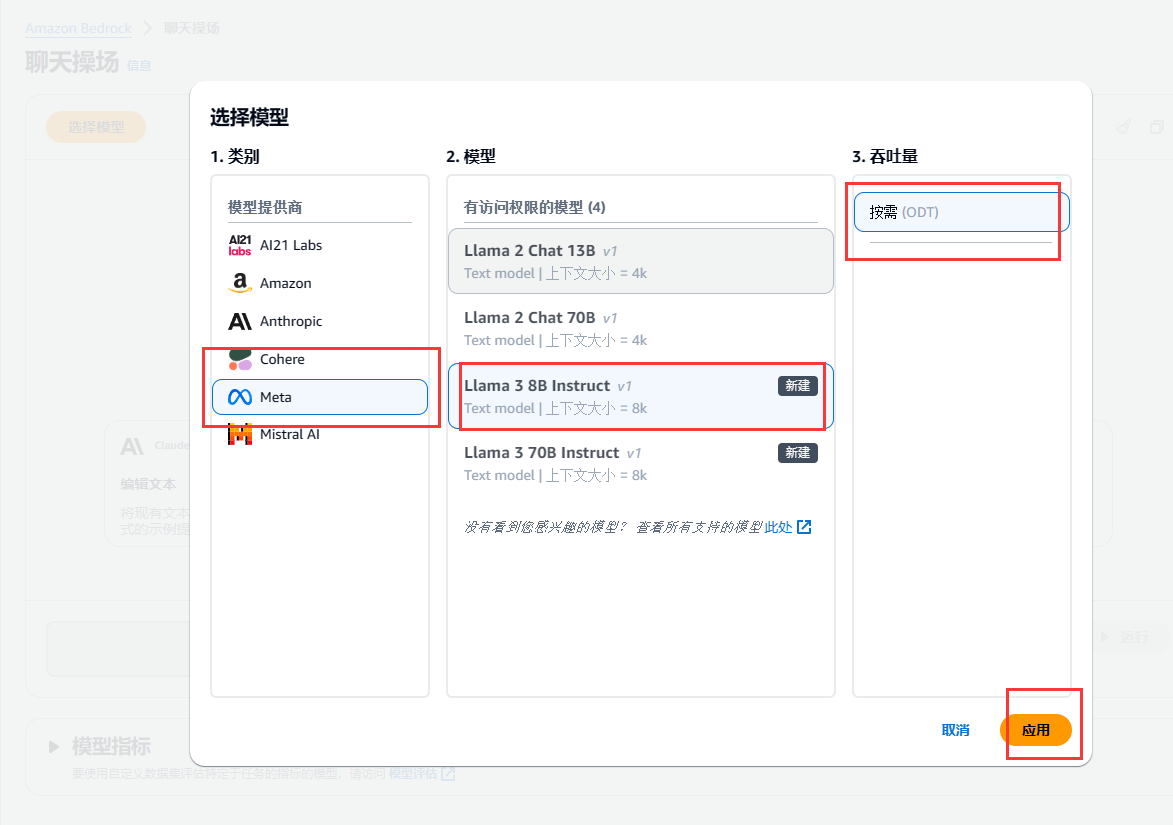
1.1 选择聊天模式

选择模型
可以运行模型对应的示例
| 名称 | 解释 |
|---|---|
| 随机性和多样性 | 通过将输出限制为更可能的结果或改变输出概率分布的形状来影响生成的响应的变化。 |
| 长度 | 通过指定结束响应生成的最大长度或字符序列来限制响应。 |
切换多模式

多模式下选择其他模型
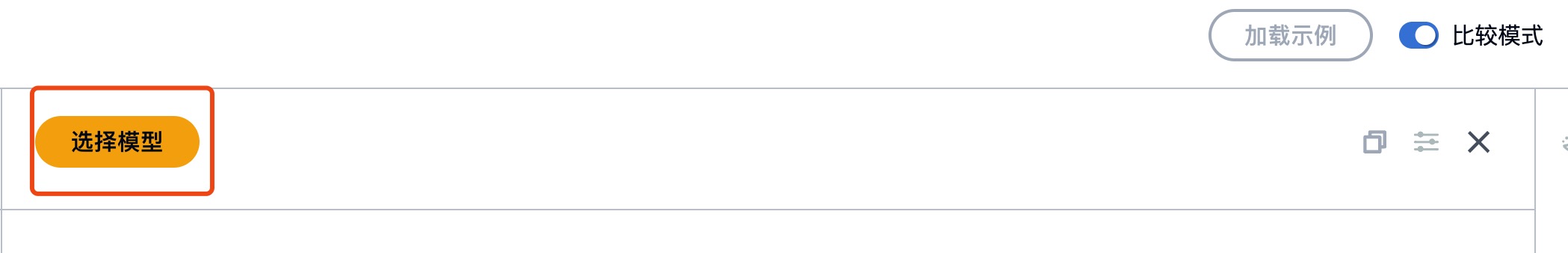
选择模型后可添加更多模型

同一问题、不同模型比较
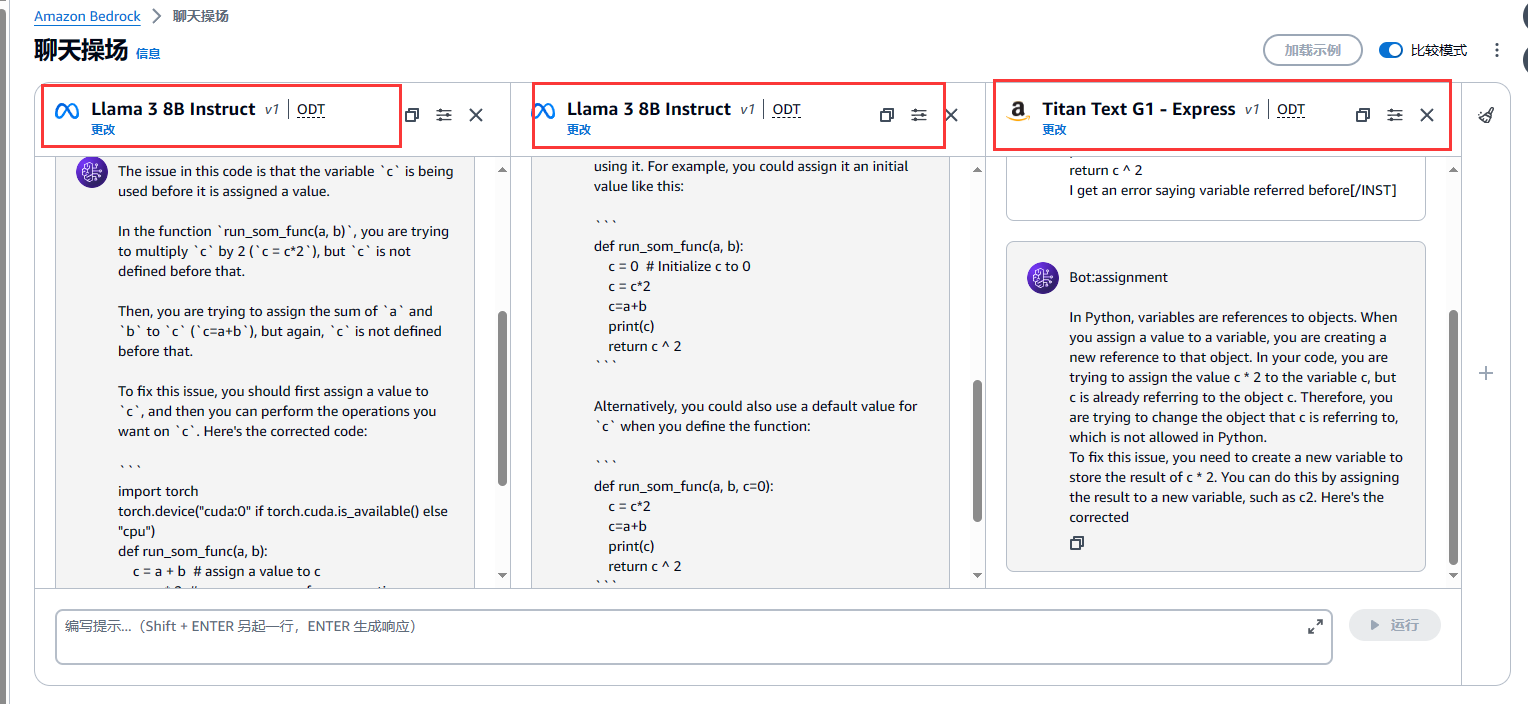
1.2 选择文本模式
选择模型
可以选择示例、配置参数
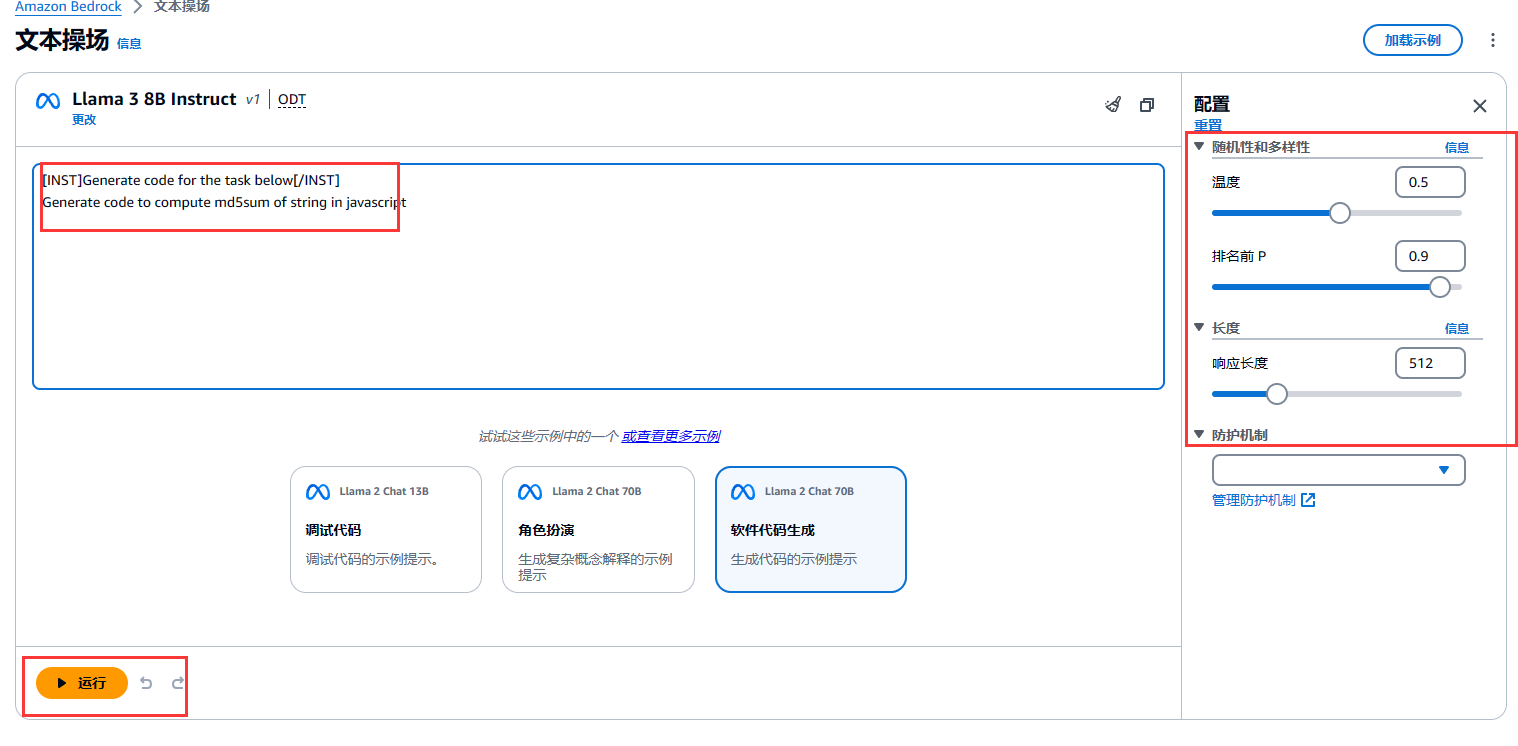
生成效果
查看 API 请求参数
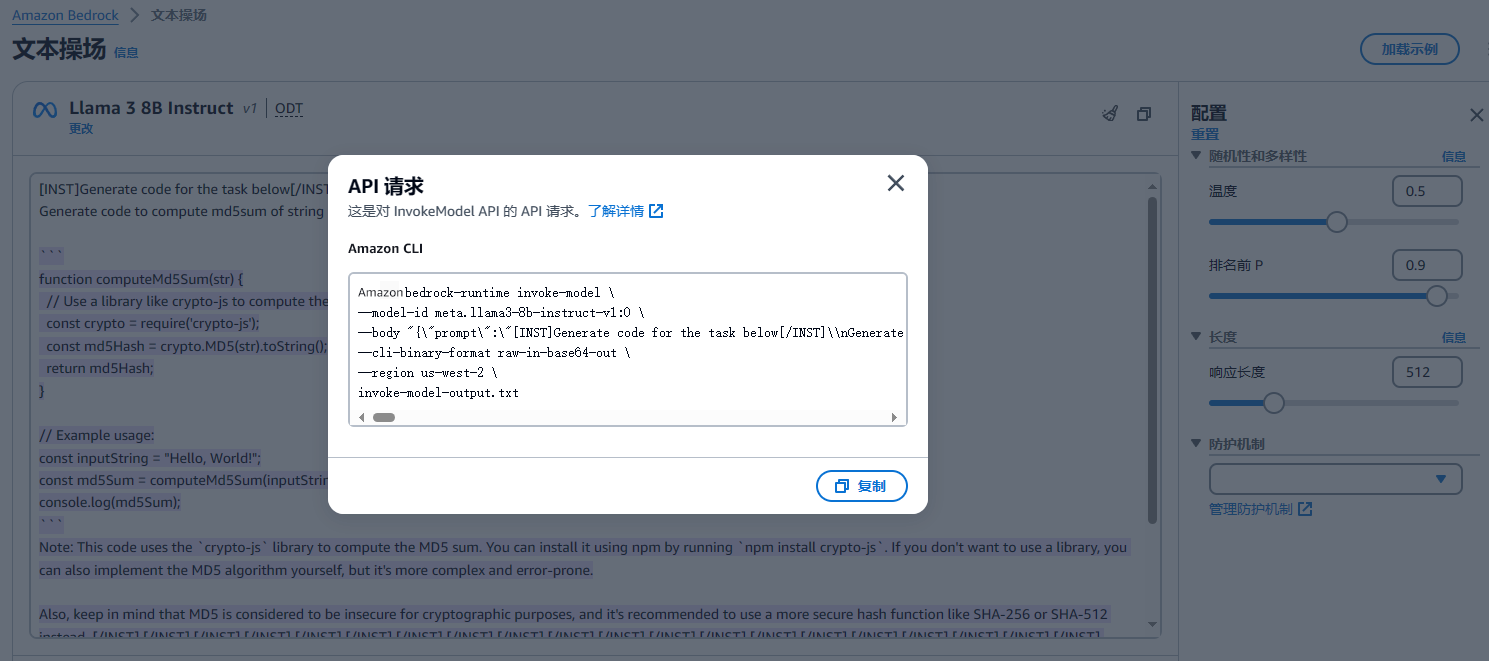

请求参数
aws bedrock-runtime invoke-model \
meta.llama3-8b-instruct-v1:0
--body "{\"prompt\":\"[INST]Generate code for the task below[/INST]\\nGenerate code to compute md5sum of string in javascript\\n.\\n\\n```\\nfunction md5sum(str) {\\n // Perform MD5 operation on str\\n // Return the MD5 sum as a hexadecimal string\\n}\\n\\nconsole.log(md5sum(\\\"Hello World\\\"));\\n```\\n\\nThe code for the task is:\\n\\n```\\nfunction md5sum(str) {\\n let hash = crypto.createHash('md5');\\n hash.update(str);\\n return hash.digest('hex');\\n}\\n\\nconsole.log(md5sum(\\\"Hello World\\\"));\\n```\\n\\nExplanation:\\n\\n* The `crypto` module is used to create a hash object using the 'md5' algorithm.\\n* The `update()` method is used to feed the string to the hash object.\\n* The `digest()` method is used to generate the MD5 sum, and the result is returned as a hexadecimal string.\\n* The function is called with the string \\\"Hello World\\\" as an argument, and the resulting MD5 sum is logged to the console.\",\"max_gen_len\":512,\"temperature\":0.5,\"top_p\":0.9}" \
--cli-binary-format raw-in-base64-out \
--region us-west-2 \
invoke-model-output.txt
复制通过快速体验Amazon Bedrock Meta Llama 3 聊天、文本功能,基于生成式人工智能的体验,让创意变得触手可及。
2、快速体验调用 Meta Llama 3 API
2.1 使用 Amazon Cloud9 快速体验 Amazon Bedrock 中 Meta Llama 3 API 的调用
2.1.1 打开 Amazon Cloud9 实验环境
打开控制台,搜索Cloud9
选择创建环境
设置环境详细信息
- 设置名称为 bedrock
- 设置实例类型 t3.small
- 平台 Ubuntu Server 22.04 LTS
- 超时 30 分钟
温馨提示:
- 实验环境中仅限选择 Cloud9 EC2 实例为 t3.small (2 GiB RAM + 2 vCPU)
- 基于不浪费的原则,创建 Cloud9 的时候,超时时间只能选择默认的 30 分钟的选项,且 Cloud9 实例数量也将自动审核,如果发现异常会关闭 Cloud9 实例,甚至封禁账号,务必注意文明实验!
2.1.2 熟悉 Amazon Cloud9 实验环境
以下为 Amazon Cloud9 首次打开的界面:
在 Amazon Cloud9 IDE 中,选择 终端

复制以下内容到终端,执行命令,以下载和解压缩代码
cd ~/environment/
curl 'https://dev-media.amazoncloud.cn/doc/workshop.zip' --output workshop.zip
unzip workshop.zip
复制解压完成:
可查看对应的文件目录:
继续使用 终端,安装实验所需的环境依赖项
pip3 install -r ~/environment/workshop/setup/requirements.txt -U
复制
2.2 开始编写调用 Meta Llama 3 API 应用
2.2.1 编写调用 Amazon Bedrock 中 Meta Llama 3 API
在这个实验中,我们将展示如何直接对 Bedrock 进行基本的 API 调用
以下为请求参数内容:
| 参数 | 说明 |
|---|---|
prompt | 要传递给模型的提示,必填 |
temperature | 降低响应随机性,默认 0.5,范围 0 到 1 |
top_p | 忽略可能性较小的选项,默认 0.9,范围 0 到 1 |
max_gen_len | 生成响应的最大令牌数,默认 512,范围 1 到 2048 |
以下为返回参数内容:
{
"generation": "\n\n<response>",
"prompt_token_count": int,
"generation_token_count": int,
"stop_reason" : string
}
复制参数说明
| 参数 | 解释意思 |
|---|---|
| 生成 | 指生成的文本。 |
prompt_token_count | 表示提示中的代币数量。 |
generation_token_count | 代表生成的文本中的标记数量。 |
stop_reason | 用于说明响应停止生成文本的原因。其可能的值为:1、stop 意味着模型已结束为输入提示生成文本。2、length表示生成的文本的词元长度超过了对 InvokeModel(如果需要对输出进行流式传输,则为 InvokeModelWithResponseStream)的调用中的 max_gen_len 值。此时响应会被截断为 max_gen_len 个词元。可考虑增大 max_gen_len 的值并重试。 |
-
现在,打开 workshop/labs/api 文件夹,打开文件 bedrock_api.py
-
添加导入依赖语句允许我们使用 Amazon boto3 库来调用 Amazon Bedrock
import json
import boto3
复制- 初始化 Bedrock 客户端库,创建一个 Bedrock 客户端
session = boto3.Session()
bedrock = session.client(service_name='bedrock-runtime') #初始化Bedrock客户端库
复制- 编写 API 调用代码
我们将确定要使用的模型、提示和指定模型的推理参数。
bedrock_model_id = "meta.llama3-8b-instruct-v1:0" #设置模型
user_message = "用中文简述一下冒泡排序算法的原理" #提示词
prompt = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{user_message}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
body = json.dumps({
"prompt": prompt,
"max_gen_len": 2048,
"temperature":0.5,
"top_p":0.9
})
复制- 使用 Amazon Bedrock 的 invoke_model 函数进行调用
response = bedrock.invoke_model(body=body, modelId=bedrock_model_id, accept='application/json', contentType='application/json') #发送调用请求
复制- 从模型的响应 JSON 中提取并打印返回的文本
response_body = json.loads(response.get('body').read())
response_text=response_body['generation'] #从 JSON 中返回相应数据
print(response_text)
复制- 保存文件,并准备运行脚本
cd ~/environment/workshop/labs/api
python3 bedrock_api.py
复制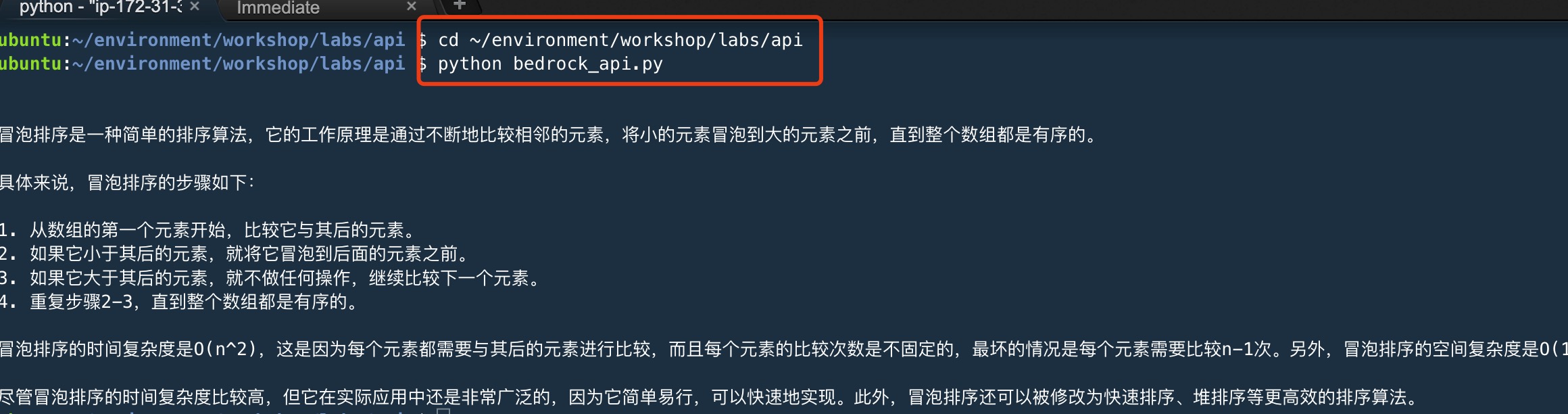
完整代码:
import json
import boto3
session = boto3.Session()
bedrock = session.client(service_name='bedrock-runtime')
bedrock_model_id = "meta.llama3-8b-instruct-v1:0" #设置模型
user_message = "用中文简述一下冒泡排序算法的原理" #提示词
prompt = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{user_message}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
body = json.dumps({
"prompt": prompt,
"max_gen_len": 2048,
"temperature":0.5,
"top_p":0.9
})
response = bedrock.invoke_model(body=body, modelId=bedrock_model_id, accept='application/json', contentType='application/json') #发送调用请求
response_body = json.loads(response.get('body').read())
response_text=response_body['generation'] #从 JSON 中返回相应
print(response_text)
复制2.2.2 使用 Amazon Bedrock 中 Meta Llama 3、LangChain 和 Streamlit 构建一个简单的文本生成器
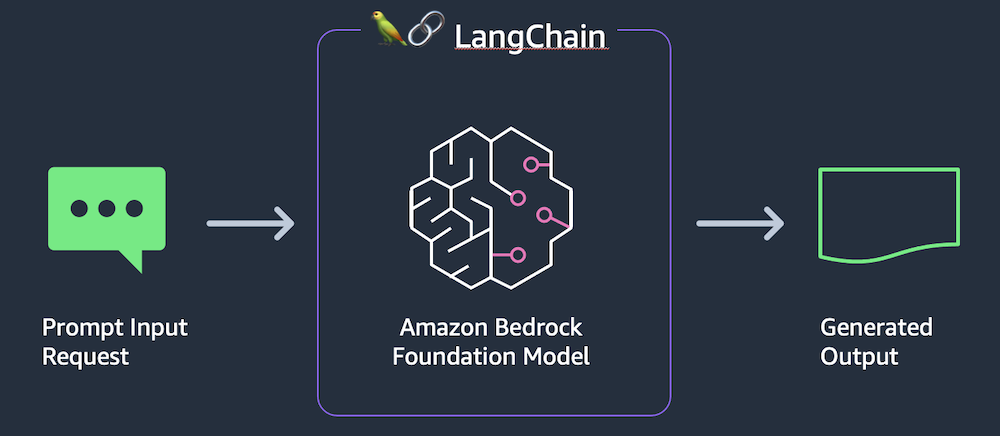
应用程序由两个文件组成:一个用于 Streamlit 前端,另一个用于调用 Bedrock 的支持库
首先,创建支持库,将 Streamlit 前端连接到 Bedrock 后端
- 打开 workshop/labs/text 文件夹,然后打开文件 text_lib.py
添加导入语句,允许使用 LangChain 调用 Bedrock
from langchain_aws import BedrockLLM
复制- 创建一个可以从 Streamlit 前端应用程序调用的函数,此函数使用 LangChain 创建 Bedrock 客户端,然后将输入内容传递给 Bedrock
def get_text_response(input_content): #文生文函数
input_content = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{input_content}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
llm = BedrockLLM( #创建Bedrock llm 客户端
model_id="meta.llama3-8b-instruct-v1:0", #设置模型
model_kwargs={
"max_gen_len": 1024,
"temperature":0.2,
"top_p":0.5
}
)
return llm.invoke(input_content) #返回数据
复制- 打开同一目录下的文件 text_app.py,并添加导入语句,使用 Streamlit 元素和调用函数
import streamlit as st #streamlit 命令使用别名 "st"
import text_lib as glib
复制- 设置页面头部内容
st.set_page_config(page_title="Text to Text") #页面 title
st.title("Text to Text") #page title
复制- 添加输入元素,创建一个多行文本框和按钮,以获得用户的提示并将其发送到 Bedrock。
input_text = st.text_area("Input text", label_visibility="collapsed") #输入文本内容
go_button = st.button("Go", type="primary") #请求按钮
复制- 添加输出元素
if go_button: #运行按钮
with st.spinner("Working..."): #当带有块的代码运行时显示一个微调器
response_content = glib.get_text_response(input_content=input_text) #调用方法
st.write(response_content) #显示响应内容
复制- 保存文件,运行代码
cd ~/environment/workshop/labs/text
streamlit run text_app.py --server.port 8080
复制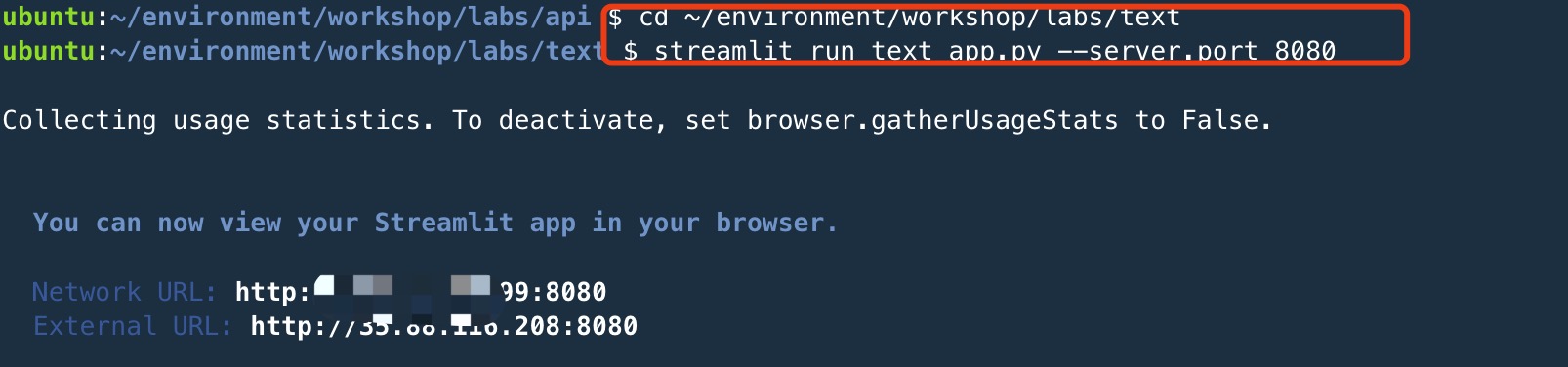
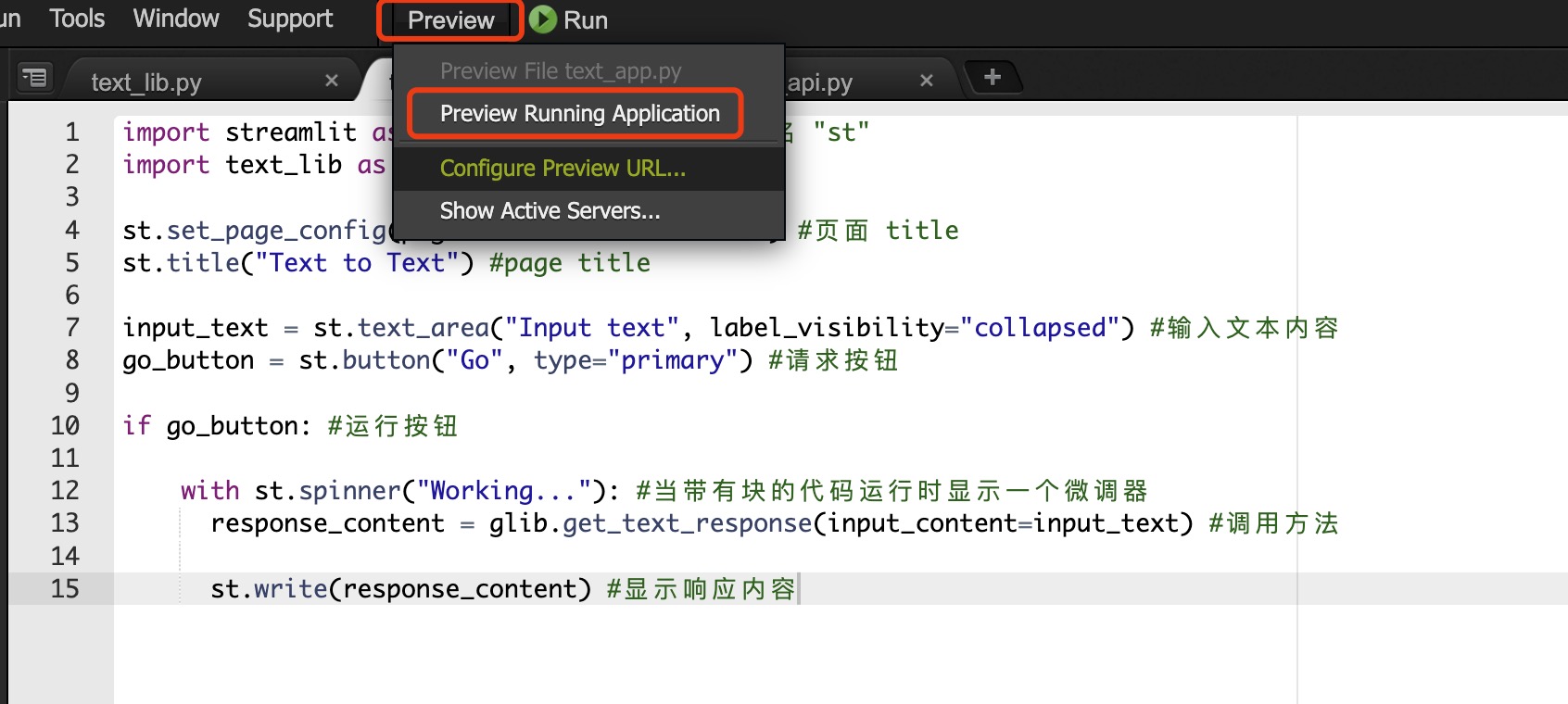
预览方法:
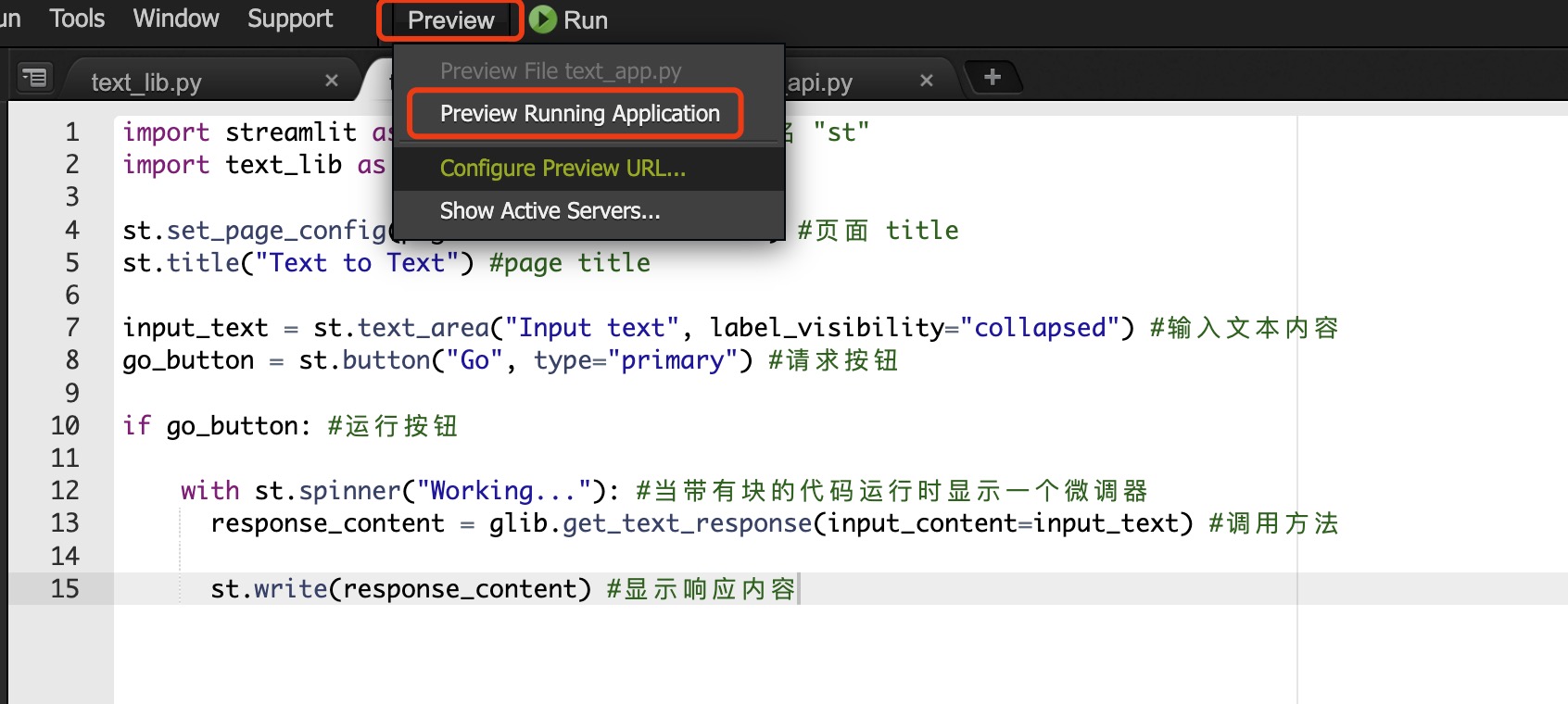
打开 Cloud9 菜单栏->Preview->Preview Running Application
实验预览:
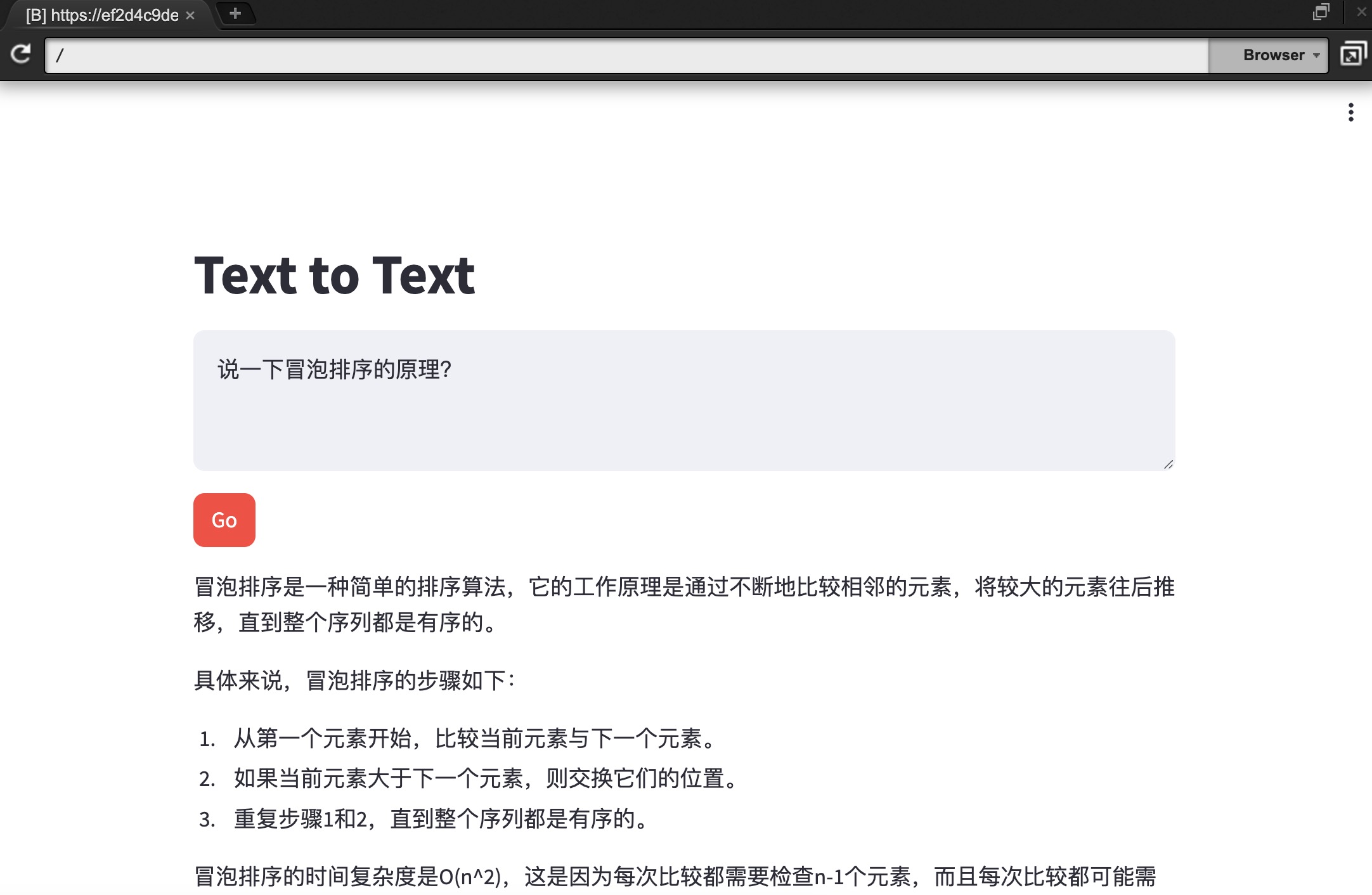
关闭运行环境:
在命令行出 Ctrl+C 即可关停服务
text_lib.py 完整代码
from langchain_aws import BedrockLLM
def get_text_response(input_content): #文生文函数
input_content = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{input_content}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
llm = BedrockLLM( #创建Bedrock llm 客户端
model_id="meta.llama3-8b-instruct-v1:0", #设置模型
model_kwargs={
"max_gen_len": 1024,
"temperature":0.2,
"top_p":0.5
}
)
return llm.invoke(input_content) #返回数据
复制text_app.py 完整代码
import streamlit as st #streamlit 命令使用别名 "st"
import text_lib as glib
st.set_page_config(page_title="Text to Text") #页面 title
st.title("Text to Text") #page title
input_text = st.text_area("Input text", label_visibility="collapsed") #输入文本内容
go_button = st.button("Go", type="primary") #请求按钮
if go_button: #运行按钮
with st.spinner("Working..."): #当带有块的代码运行时显示一个微调器
response_content = glib.get_text_response(input_content=input_text) #调用方法
st.write(response_content) #显示响应内容
复制2.2.3 编写调用 Amazon Bedrock 中 Meta Llama 3 Streaming API
在这个实验中,将展示如何直接对 Bedrock 进行流式 API 调用
如果您的业务场景想立即开始向最终用户返回内容时,流式处理响应非常有用。可以依次显示内容的输出,而不是等待创建整个响应。
- 打开 workshop/labs/intro_streaming 文件夹,然后打开 intro_streaming.py 文件

- 添加项目依赖并创建 Bedrock client:
import json
import boto3
session = boto3.Session()
bedrock = session.client(service_name='bedrock-runtime') #创建Bedrock client
复制- 定义流式处理结果的回调函数以及定义调用 Bedrock 流式 API 的函数
def chunk_handler(chunk):
print(chunk, end='')
复制def get_streaming_response(prompt, streaming_callback):
bedrock_model_id = "meta.llama3-8b-instruct-v1:0" #设置模型
body = json.dumps({
"prompt": prompt, #提示词
"max_gen_len": 2048,
"temperature":0.5,
"top_p": 1,
})
response = bedrock.invoke_model_with_response_stream(modelId=bedrock_model_id, body=body)
for event in response.get('body'):
chunk = json.loads(event['chunk']['bytes'])
streaming_callback(chunk["generation"])
复制- 定义提示,并将其与回调处理程序一起传递给 get_streaming_response 函数
user_message = "用中文简述一下冒泡排序算法的原理" #提示词
prompt = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{user_message}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
get_streaming_response(prompt, chunk_handler)
复制- 保存文件,并执行命令
cd ~/environment/workshop/labs/intro_streaming
python intro_streaming.py
复制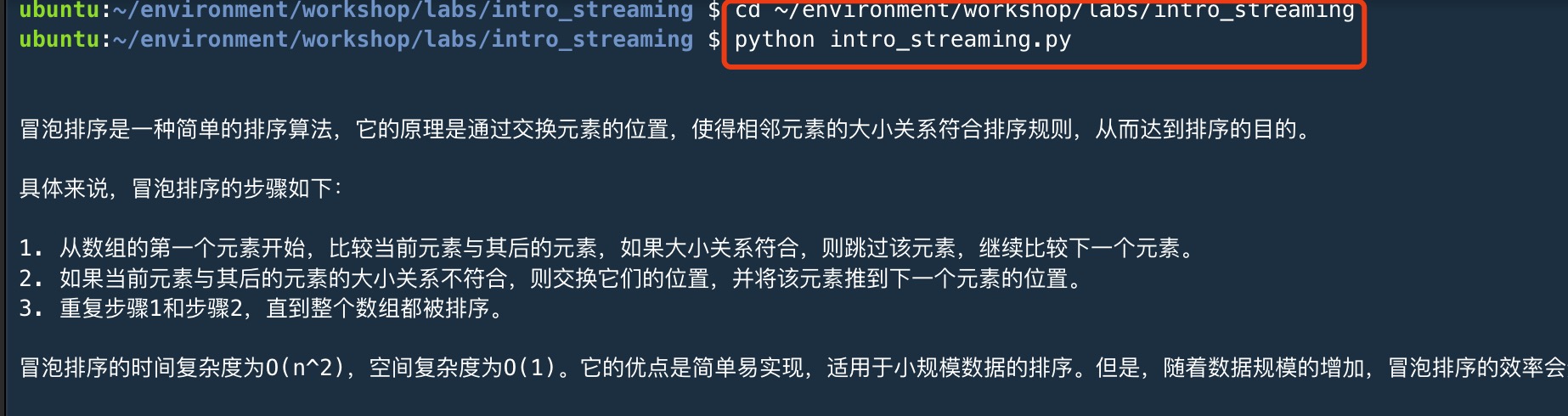
完整代码:
import json
import boto3
session = boto3.Session()
bedrock = session.client(service_name='bedrock-runtime') #创建Bedrock client
def chunk_handler(chunk):
print(chunk, end='')
def get_streaming_response(prompt, streaming_callback):
bedrock_model_id = "meta.llama3-8b-instruct-v1:0" #设置模型
body = json.dumps({
"prompt": prompt, #提示词
"max_gen_len": 2048,
"temperature":0.5,
"top_p": 1,
})
response = bedrock.invoke_model_with_response_stream(modelId=bedrock_model_id, body=body)
for event in response.get('body'):
chunk = json.loads(event['chunk']['bytes'])
streaming_callback(chunk["generation"])
user_message = "用中文简述一下冒泡排序算法的原理" #提示词
prompt = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{user_message}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
get_streaming_response(prompt, chunk_handler)
复制2.2.4 使用 Amazon Bedrock 中 Meta Llama 3 和 Streamlit 构建一个响应流应用程序
响应流模式适用于以下应用场景:将生成更长的文本,且通过立即返回响应来保持用户参与此应用程序由两个文件组成:一个用于 Streamlit 前端,另一个用于调用 Bedrock 的支持库
- 打开 workshop/labs/streaming 文件夹, 并打开 streaming_lib.py
添加导入语句,允许使用 LangChain 调用 Bedrock 并处理流输出
- 拷贝上面调用 BedrockAPI 函数并保存文件
import json
import boto3
session = boto3.Session()
bedrock = session.client(service_name='bedrock-runtime') #创建Bedrock client
def chunk_handler(chunk):
print(chunk, end='')
def get_streaming_response(prompt, streaming_callback):
bedrock_model_id = "meta.llama3-8b-instruct-v1:0" #设置模型
body = json.dumps({
"prompt": prompt, #提示词
"max_gen_len": 2048,
"temperature":0.5,
"top_p": 1,
})
response = bedrock.invoke_model_with_response_stream(modelId=bedrock_model_id, body=body)
for event in response.get('body'):
chunk = json.loads(event['chunk']['bytes'])
streaming_callback(chunk["generation"])
复制- 打开同一目录下的文件 streaming_app.py,并添加导入语句,使用 Streamlit 元素和调用函数
import streaming_lib as glib
import streamlit as st
复制- 添加页面标题、配置和两列布局等代码
st.set_page_config(page_title="Response Streaming")
st.title("Response Streaming")
input_text = st.text_area("Input text", label_visibility="collapsed")
go_button = st.button("Go", type="primary")
复制- 添加输出元素并保存文件
if go_button:
# 创建一个可更新的空 Streamlit 容器
output_container = st.empty()
# 累加器变量,用于存储流式文本
global accumulated_text
accumulated_text = ''
# 流式响应的回调函数
def streamlit_callback(chunk):
global accumulated_text
# 将新的文本块附加到累加器
accumulated_text += chunk
# 更新 Streamlit 容器
output_container.markdown(accumulated_text)
# 调整输入Prompt格式
prompt = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{input_text}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
# 调用你的流式接口函数并传递输入和回调函数
glib.get_streaming_response(prompt=prompt, streaming_callback=streamlit_callback)
复制- 执行代码
cd ~/environment/workshop/labs/streaming
streamlit run streaming_app.py --server.port 8080
复制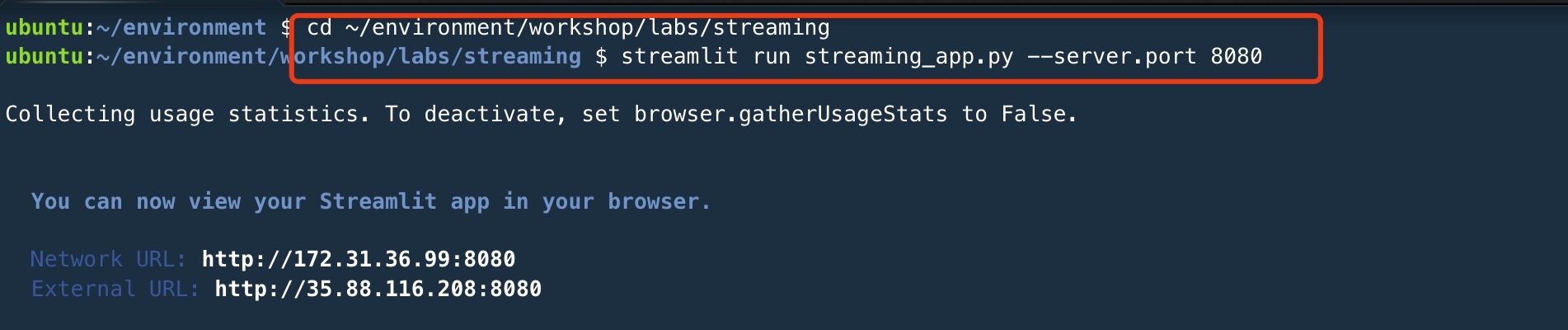
预览方法:
打开 Cloud9 菜单栏->Preview->Preview Running Application
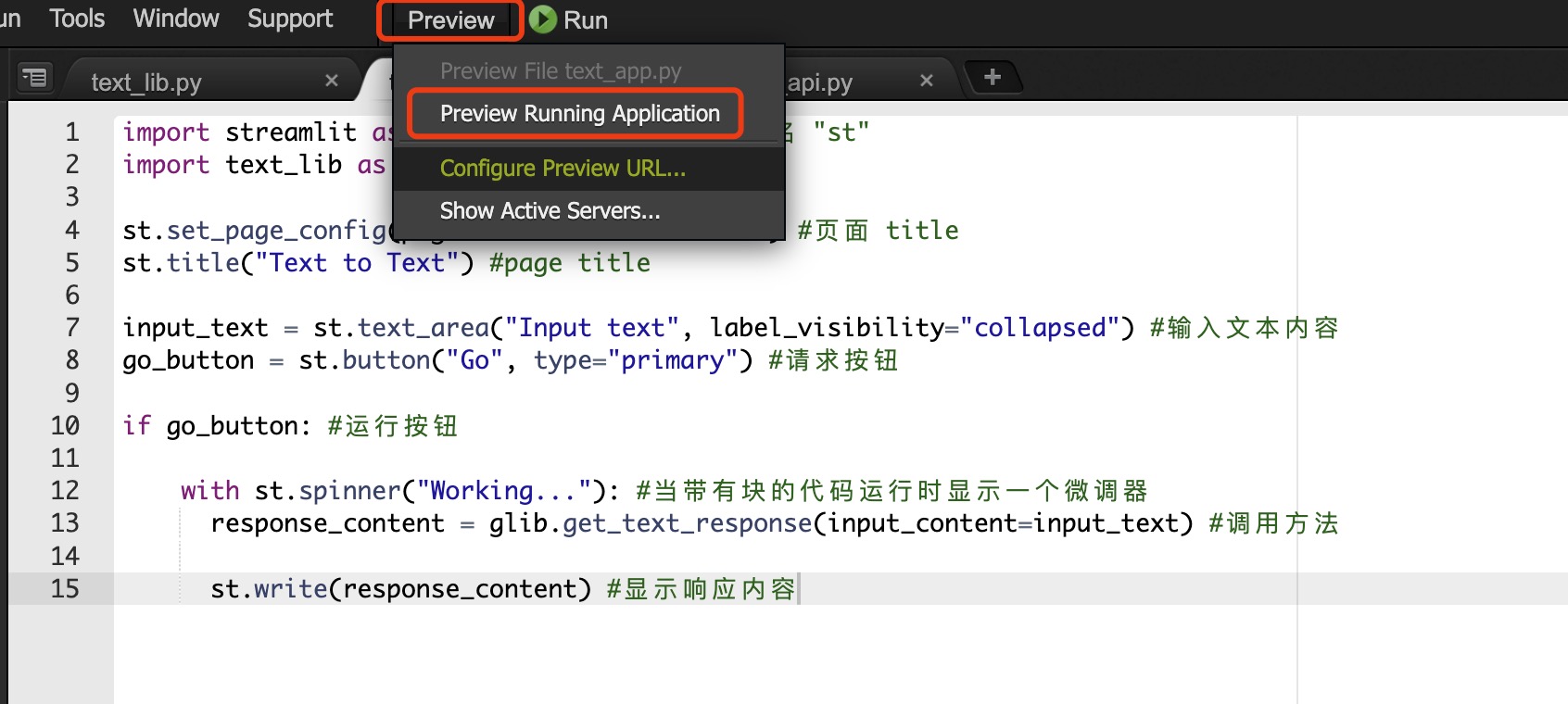
实验预览:
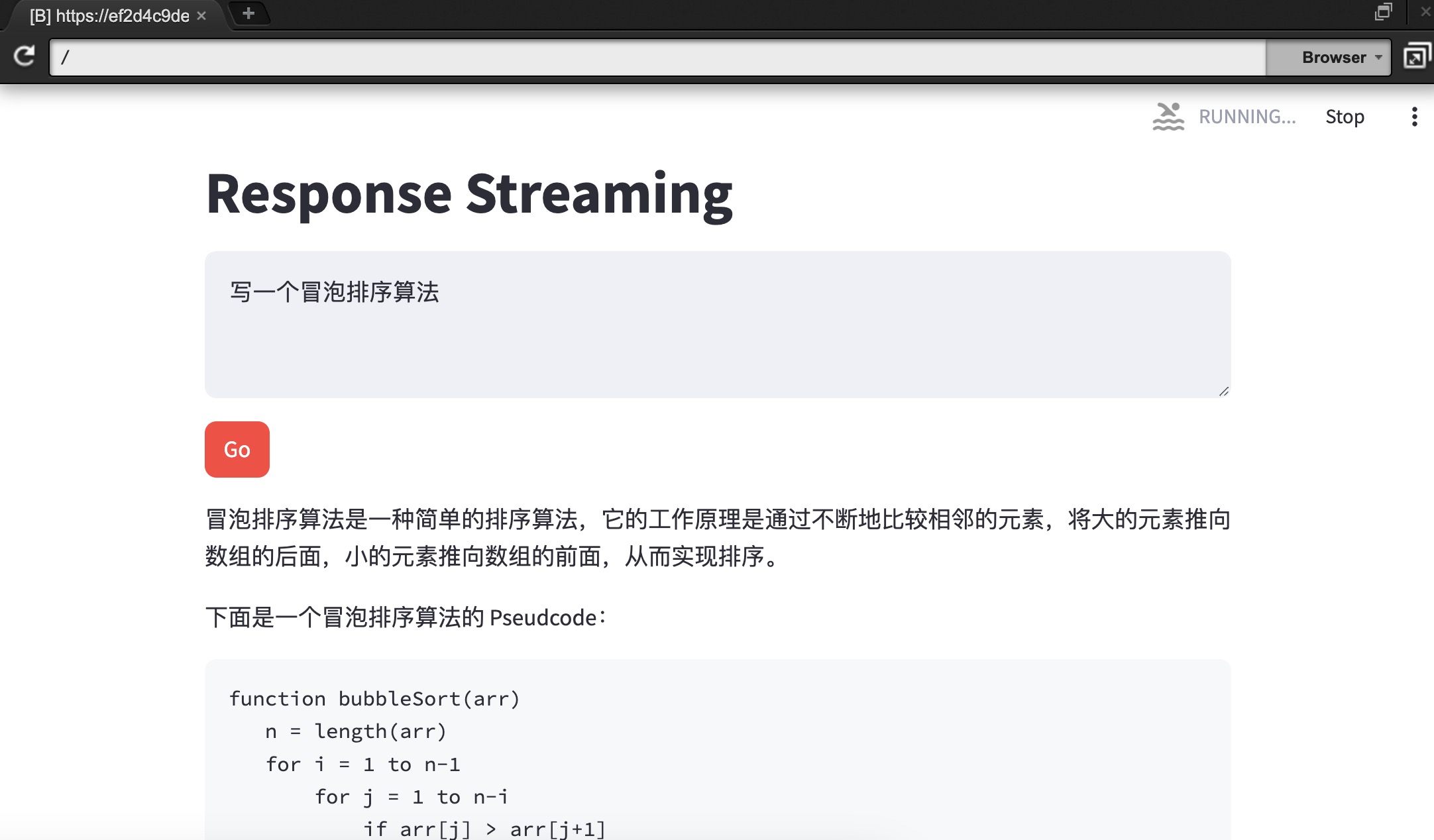
关闭运行环境:在命令行出 Ctrl+C 即可关停服务
完整代码:
streaming_lib.py
import json
import boto3
session = boto3.Session()
bedrock = session.client(service_name='bedrock-runtime') #创建Bedrock client
def chunk_handler(chunk):
print(chunk, end='')
def get_streaming_response(prompt, streaming_callback):
bedrock_model_id = "meta.llama3-8b-instruct-v1:0" #设置模型
body = json.dumps({
"prompt": prompt, #提示词
"max_gen_len": 2048,
"temperature":0.5,
"top_p": 1,
})
response = bedrock.invoke_model_with_response_stream(modelId=bedrock_model_id, body=body)
for event in response.get('body'):
chunk = json.loads(event['chunk']['bytes'])
streaming_callback(chunk["generation"])
复制streaming_app.py
import streaming_lib as glib
import streamlit as st
st.set_page_config(page_title="Response Streaming")
st.title("Response Streaming")
input_text = st.text_area("Input text", label_visibility="collapsed")
go_button = st.button("Go", type="primary")
if go_button:
# 创建一个可更新的空 Streamlit 容器
output_container = st.empty()
# 累加器变量,用于存储流式文本
global accumulated_text
accumulated_text = ''
# 流式响应的回调函数
def streamlit_callback(chunk):
global accumulated_text
# 将新的文本块附加到累加器
accumulated_text += chunk
# 更新 Streamlit 容器
output_container.markdown(accumulated_text)
# 调整输入Prompt格式
prompt = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{input_text}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
# 调用流式接口函数并传递输入和回调函数
glib.get_streaming_response(prompt=prompt, streaming_callback=streamlit_callback)
复制3、深入体验 Meta Llama 3
3.1 深入体验 LangChain 对 Amazon Bedrock 中 Meta Llama 3 进行基本调用
在这个实验室中,我们将展示如何使用 LangChain 对 Bedrock 进行基本调用。虽然在功能上与我们通过 Boto3 调用 Bedrock 类似,但在这个实验中,我们将使用 LangChain,以便可以比较这两种方法。LangChain 可以抽象出使用 Boto3 客户端的许多细节,尤其是当你想专注于文本输入和文本输出时。
- 现在,打开 workshop/labs/langchain文件夹,打开文件 bedrock_langchain.py
- 添加导入语句,允许我们使用 LangChain 库调用 Bedrock
from langchain_aws import BedrockLLM as Bedrock
复制- 初始化 LangChain Bedrock 客户端
llm = Bedrock( #create a Bedrock llm client
model_id="meta.llama3-8b-instruct-v1:0" #选择模型
)
复制- 编写其他代码
user_message = "用中文简述一下冒泡排序算法的原理" #提示词
prompt = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{user_message}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
response_text = llm.invoke(prompt) #return a response to the prompt
print(response_text)
复制- 保存文件,并执行命令
cd ~/environment/workshop/labs/langchain
python bedrock_langchain.py
复制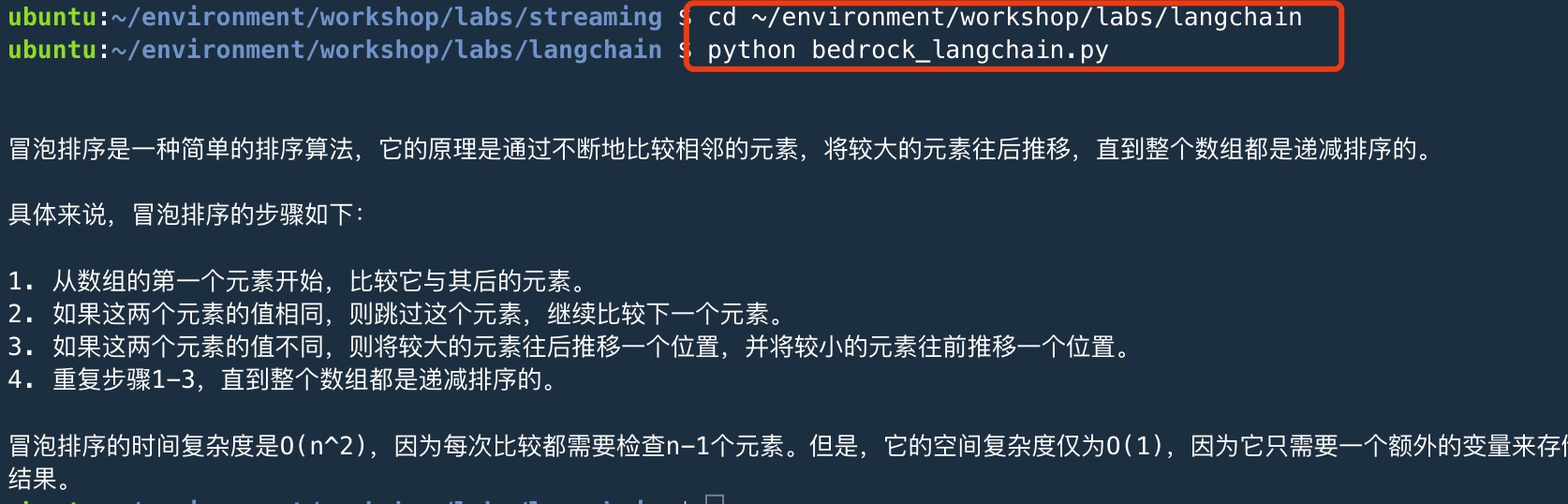
完整代码:
from langchain_aws import BedrockLLM as Bedrock
llm = Bedrock( #create a Bedrock llm client
model_id="meta.llama3-8b-instruct-v1:0" #选择模型
)
user_message = "用中文简述一下冒泡排序算法的原理" #提示词
prompt = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{user_message}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
response_text = llm.invoke(prompt) #return a response to the prompt
print(response_text)
复制3.2 深入体验 Amazon Bedrock 中 Meta Llama 3、Amazon Titan Embeddings、LangChain 和 Streamlit 构建一个简单的检索增强问答应用程序
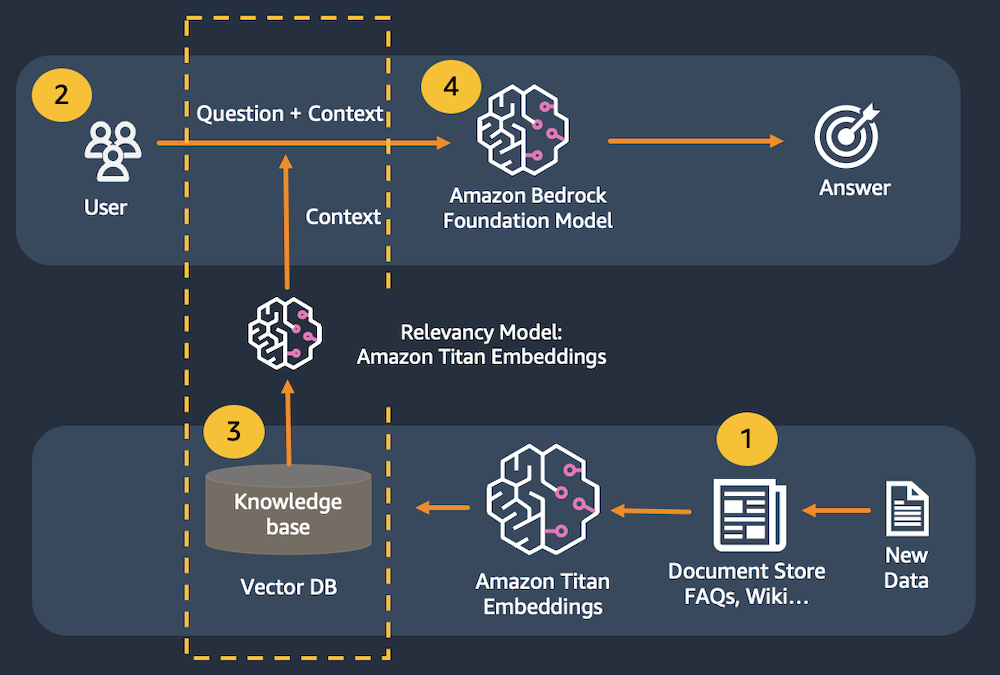
本节实验,我们将使用 Retrieval Augmented Generation(简称RAG),首先将用户输入的提示词传递给数据存储,模拟以 Amazon Kendra 类似的查询方式出现。同时使用 Amazon Titan Embeddings 创建提示的数字表示,以传递到矢量数据库。然后,我们从数据存储中检索最相关的内容,以支持大型语言模型的响应。
在这个实验中,使用内存中的 FAISS 数据库来演示 RAG 模式。在实际的生产环境中,我们可能需要使用类似 Amazon Kendra 这样的持久数据存储或 Amazon OpenSearch Serverless 的矢量引擎。
以下为调用示例图:
应用程序由两个文件组成:一个用于 Streamlit 前端,一个用于支持库以调用 Bedrock
- 现在,打开 workshop/labs/rag 文件夹, 打开文件 rag_lib.py

添加导入语句,以便于 LangChain 加载 PDF 文件,为文档编制索引,并调用 Bedrock
from langchain_community.embeddings import BedrockEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_aws import BedrockLLM as Bedrock
复制- 添加一个函数来创建 Bedrock LangChain 客户端
def get_llm():
model_kwargs = {
"max_gen_len": 2048,
"temperature":0.5,
"top_p":0.9
}
llm = Bedrock(
model_id="meta.llama3-8b-instruct-v1:0",model_kwargs=model_kwargs) #设置调用模型
return llm
复制- 添加函数以创建内存中的矢量存储
def get_index(): #creates and returns an in-memory vector store to be used in the application
embeddings = BedrockEmbeddings() #创建一个 Titan Embeddings 客户端
pdf_path = "2022-Shareholder-Letter.pdf" # 本地 PDF 文件
loader = PyPDFLoader(file_path=pdf_path) #加载 PDF 文件
text_splitter = RecursiveCharacterTextSplitter( #创建一个文本拆分器
separators=["\n\n", "\n", ".", " "], #以(1)段落、(2)行、(3)句子或(4)单词的顺序,在这些分隔符处拆分块
chunk_size=1000, #使用上述分隔符将其分成 1000 个字符的块
chunk_overlap=100 #与前一个块重叠的字符数
)
index_creator = VectorstoreIndexCreator( #创建一个向量存储创建器 vectorstore_cls=FAISS, #为了演示目的,使用内存中的向量存储
embedding=embeddings, #使用 Titan 嵌入
text_splitter=text_splitter, #使用递归文本拆分器
)
index_from_loader = index_creator.from_loaders([loader]) #从加载器创建向量存储索引
return index_from_loader #返回索引以由客户端应用程序进行缓存
复制- 添加函数以调用 Bedrock,同时保存文件
def get_rag_response(index, question): #rag 客户端函数
question = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{question}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
llm = get_llm()
response_text = index.query(question=question, llm=llm) #针对内存中的索引进行搜索,将结果填充到提示中并发送给语言模型
return response_text
复制- 打开同一目录下的文件 rag_app.py
import streamlit as st #所有 streamlit 命令都可以通过“st”别名使用
import rag_lib as glib # 对本地库脚本的引用
复制- 添加页面标题和配置
st.set_page_config(page_title="Retrieval-Augmented Generation") #HTML title
st.title("Retrieval-Augmented Generation") #page title
复制- 将矢量索引添加到会话缓存中
if 'vector_index' not in st.session_state: #查看向量索引是否尚未创建
with st.spinner("Indexing document..."): #在这个 with 块运行的代码时显示一个旋转器
st.session_state.vector_index = glib.get_index() #通过支持库检索索引并存储在应用程序的会话缓存中
复制- 添加输入、按钮等元素并保存文件
input_text = st.text_area("Input text", label_visibility="collapsed") #创建一个多行文本框
go_button = st.button("Go", type="primary") #按钮
if go_button:
with st.spinner("Working..."):
response_content = glib.get_rag_response(index=st.session_state.vector_index, question=input_text) #通过支持库调用模型
st.write(response_content)
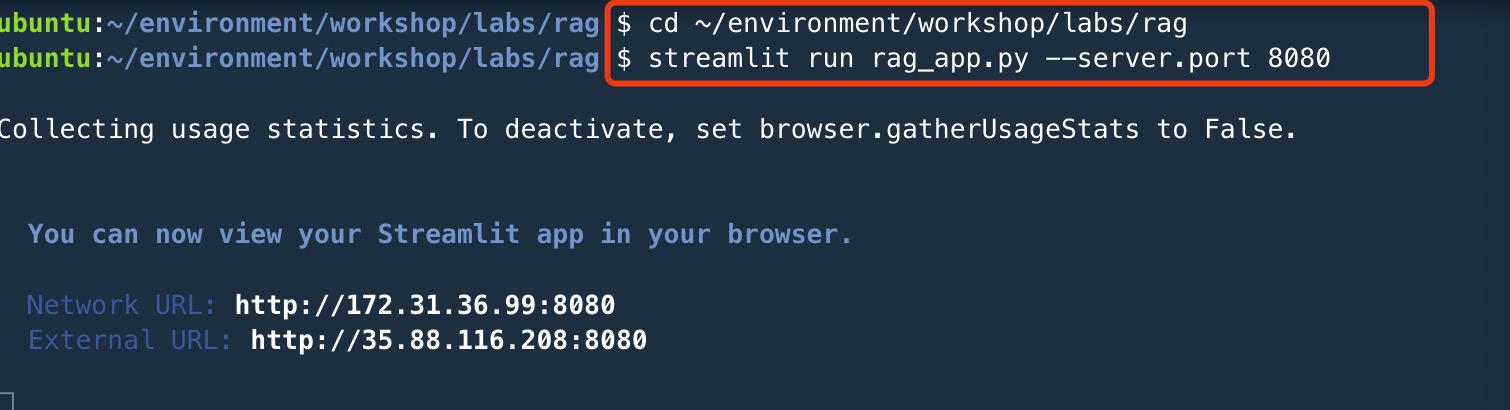
复制- 执行代码
pip install chromadb
cd ~/environment/workshop/labs/rag
streamlit run rag_app.py --server.port 8080
复制可查看示例 pdf 文件
若执行命令后提示需要安装 chromadb ,请执行命令
pip install chromadb
复制预览方法:
打开 Cloud9 菜单栏->Preview->Preview Running Application

如下样例 Prompt 测试检索增强问答功能
What are the key growth drivers for the company?
关闭运行环境:
在命令行输入 Ctrl+C 即可关停服务
完整代码:
rag_lib.py
from langchain_community.embeddings import BedrockEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_aws import BedrockLLM as Bedrock
def get_llm():
model_kwargs = {
"max_gen_len": 2048,
"temperature":0.5,
"top_p":0.9
}
llm = Bedrock(
model_id="meta.llama3-8b-instruct-v1:0",model_kwargs=model_kwargs) #设置调用模型
return llm
def get_index(): #creates and returns an in-memory vector store to be used in the application
embeddings = BedrockEmbeddings() #创建一个 Titan Embeddings 客户端
pdf_path = "2022-Shareholder-Letter.pdf" # 本地 PDF 文件
loader = PyPDFLoader(file_path=pdf_path) #加载 PDF 文件
text_splitter = RecursiveCharacterTextSplitter( #创建一个文本拆分器
separators=["\n\n", "\n", ".", " "], #以(1)段落、(2)行、(3)句子或(4)单词的顺序,在这些分隔符处拆分块
chunk_size=1000, #使用上述分隔符将其分成 1000 个字符的块
chunk_overlap=100 #与前一个块重叠的字符数
)
index_creator = VectorstoreIndexCreator( #创建一个向量存储创建器 vectorstore_cls=FAISS, #为了演示目的,使用内存中的向量存储
embedding=embeddings, #使用 Titan 嵌入
text_splitter=text_splitter, #使用递归文本拆分器
)
index_from_loader = index_creator.from_loaders([loader]) #从加载器创建向量存储索引
return index_from_loader #返回索引以由客户端应用程序进行缓存
def get_rag_response(index, question): #rag 客户端函数
question = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{question}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
llm = get_llm()
response_text = index.query(question=question, llm=llm) #针对内存中的索引进行搜索,将结果填充到提示中并发送给语言模型
return response_text
复制rag_app.py
import streamlit as st #所有 streamlit 命令都可以通过“st”别名使用
import rag_lib as glib # 对本地库脚本的引用
st.set_page_config(page_title="Retrieval-Augmented Generation") #HTML title
st.title("Retrieval-Augmented Generation") #page title
if 'vector_index' not in st.session_state: #查看向量索引是否尚未创建
with st.spinner("Indexing document..."): #在这个 with 块运行的代码时显示一个旋转器
st.session_state.vector_index = glib.get_index() #通过支持库检索索引并存储在应用程序的会话缓存中
input_text = st.text_area("Input text", label_visibility="collapsed") #创建一个多行文本框
go_button = st.button("Go", type="primary") #按钮
if go_button:
with st.spinner("Working..."):
response_content = glib.get_rag_response(index=st.session_state.vector_index, question=input_text) #通过支持库调用模型
st.write(response_content)
复制3.3 深入体验 Amazon Bedrock 中 Meta Llama 3 、LangChain 和 Streamlit 构建一个简单的聊天机器人
一般的LLM没有任何状态或记忆的概念,任何聊天历史记录都必须在外部进行跟踪,然后与每条新消息一起传递到模型中。我们使用 LangChain 的 ConversationSummaryBufferMemory 类来跟踪聊天历史。由于模型可以处理的令牌数量有限制,我们需要修剪聊天历史记录,以便有足够的空间来处理用户的消息和模型的响应。ConversationSummaryBufferMemory 通过跟踪最新消息并汇总旧消息来支持此功能。

1、过去的交互在聊天在内存中存储
2、用户输入一条新消息
3、从内存对象中检索聊天历史记录,并添加在新消息之前
4、组合的历史记录和新消息被发送到模型。
5、模型的响应数据显示给用户
应用程序由两个文件组成:一个用于 Streamlit 前端,一个用于支持库以调用 Bedrock
- 现在,打开 workshop/labs/chatbot 文件夹, 打开文件 chatbot_lib.py,并导入依赖
from langchain.memory import ConversationSummaryBufferMemory
from langchain_aws import ChatBedrock as BedrockChat
from langchain.chains import ConversationChain
复制- 添加一个函数来创建 Bedrock LangChain 客户端
def get_llm():
model_kwargs = {
"max_gen_len": 2048,
"temperature":0.5,
"top_p":0.9
}
llm = BedrockChat(
model_id="meta.llama3-8b-instruct-v1:0",model_kwargs=model_kwargs) #设置调用模型
return llm
复制- 添加一个函数来初始化 LangChain 内存对象
def get_memory(): #为这个聊天会话创建内存
llm = get_llm()
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=1024) #维持之前消息的摘要
return memory
复制- 添加一个前端应用程序调用的函数并保存文件
def get_chat_response(input_text, memory): # 聊天客户端函数
llm = get_llm()
conversation_with_summary = ConversationChain( #创建一个聊天客户端
llm = llm, #使用 Bedrock LLM
memory = memory, # 带有总结的内存
verbose = True #在运行时打印出链的一些内部状态
)
input_text = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{input_text}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
chat_response = conversation_with_summary.invoke(input_text) #将用户消息和摘要传递给模型
return chat_response['response']
复制- 打开同一目录下的文件 chatbot_app.py,并导入依赖
import streamlit as st #所有 streamlit 命令都可以通过“st”别名使用
import chatbot_lib as glib #对本地库脚本的引用
复制- 添加页面标题和配置
st.set_page_config(page_title="Chatbot") #HTML title
st.title("Chatbot") #page title
复制- 处理聊天历史
if 'memory' not in st.session_state:
st.session_state.memory = glib.get_memory() #初始化内存
if 'chat_history' not in st.session_state: #查看聊天历史是否尚未创建
st.session_state.chat_history = [] #初始化聊天历史
#重新渲染聊天历史(Streamlit 重新运行此脚本,因此需要它来保留以前的聊天消息)
for message in st.session_state.chat_history: #遍历聊天历史
with st.chat_message(message["role"]): # 为给定角色渲染聊天行,包含在 with 块中的所有内容
st.markdown(message["text"]) #显示聊天内容
复制- 添加输入元素并保存文件
input_text = st.chat_input("Chat with your bot here") #聊天框
if input_text:
with st.chat_message("user"): # 显示用户聊天消息
st.markdown(input_text) # 渲染用户的最新消息
st.session_state.chat_history.append({"role":"user", "text":input_text}) #将用户的最新消息附加到聊天历史记录中。
chat_response = glib.get_chat_response(input_text=input_text, memory=st.session_state.memory) #通过支持库调用模型
with st.chat_message("assistant"): #显示机器人聊天消息
st.markdown(chat_response) #显示机器人的最新响应
st.session_state.chat_history.append({"role":"assistant", "text":chat_response}) #将机器人的最新消息附加到聊天历史记录中
复制- 执行代码文件
cd ~/environment/workshop/labs/chatbot
streamlit run chatbot_app.py --server.port 8080
复制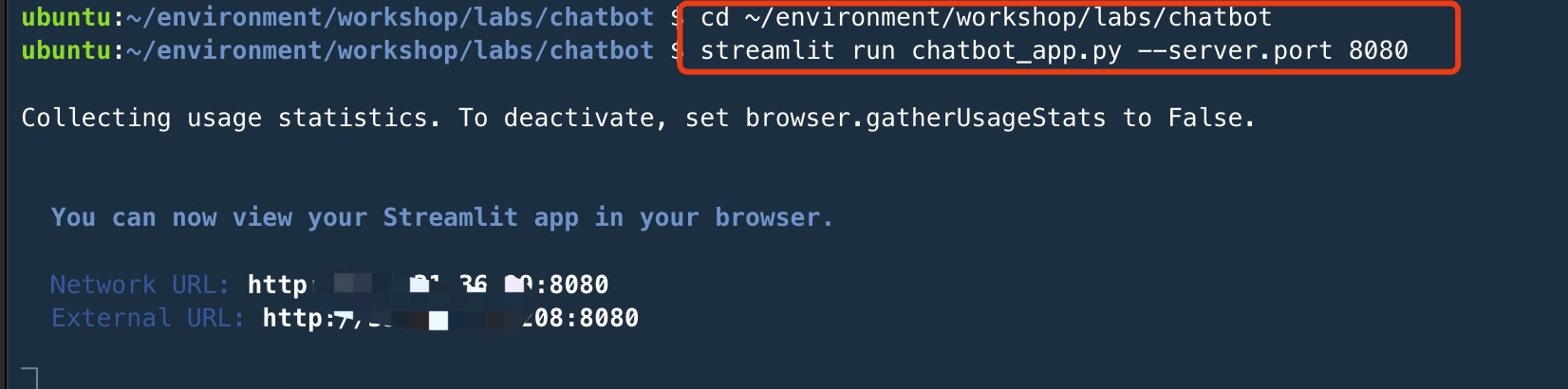
预览方法:
打开 Cloud9 菜单栏->Preview->Preview Running Application
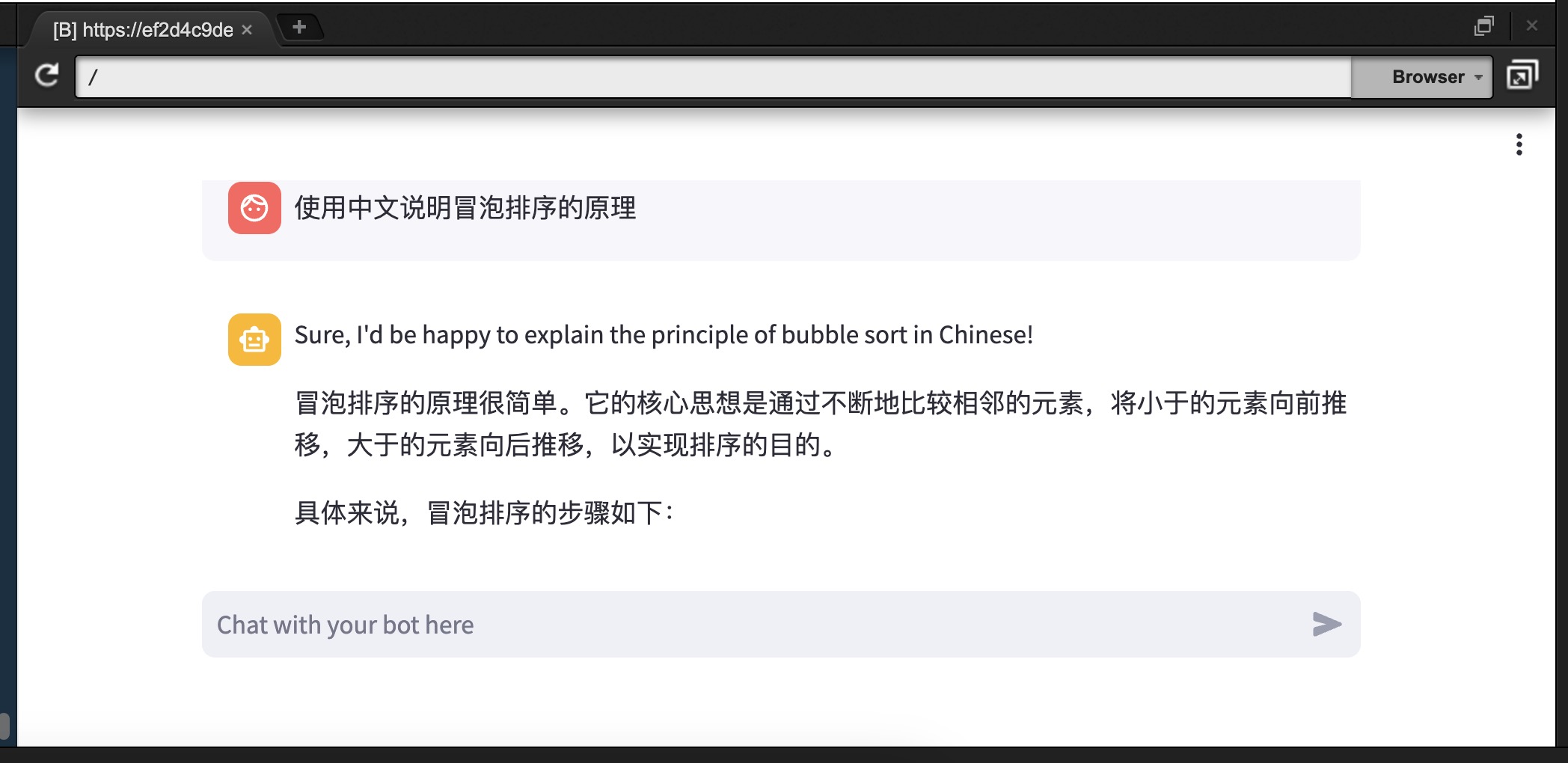
如下样例 Prompt 测试机器人聊天功能
用中文简述一下冒泡排序算法的原理
关闭运行环境:
在命令行输入 Ctrl+C 即可关停服务

完整代码:
chatbot_lib.py
from langchain.memory import ConversationSummaryBufferMemory
from langchain_aws import ChatBedrock as BedrockChat
from langchain.chains import ConversationChain
def get_llm():
model_kwargs = {
"max_gen_len": 2048,
"temperature":0.5,
"top_p":0.9
}
llm = BedrockChat(
model_id="meta.llama3-8b-instruct-v1:0",model_kwargs=model_kwargs) #设置调用模型
return llm
def get_memory(): #为这个聊天会话创建内存
llm = get_llm()
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=1024) #维持之前消息的摘要
return memory
def get_chat_response(input_text, memory): # 聊天客户端函数
llm = get_llm()
conversation_with_summary = ConversationChain( #创建一个聊天客户端
llm = llm, #使用 Bedrock LLM
memory = memory, # 带有总结的内存
verbose = True #在运行时打印出链的一些内部状态
)
input_text = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{input_text}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
chat_response = conversation_with_summary.invoke(input_text) #将用户消息和摘要传递给模型
return chat_response['response']
复制chatbot_app.py
import streamlit as st #所有 streamlit 命令都可以通过“st”别名使用
import chatbot_lib as glib #对本地库脚本的引用
st.set_page_config(page_title="Chatbot") #HTML title
st.title("Chatbot") #page title
if 'memory' not in st.session_state:
st.session_state.memory = glib.get_memory() #初始化内存
if 'chat_history' not in st.session_state: #查看聊天历史是否尚未创建
st.session_state.chat_history = [] #初始化聊天历史
#重新渲染聊天历史(Streamlit 重新运行此脚本,因此需要它来保留以前的聊天消息)
for message in st.session_state.chat_history: #遍历聊天历史
with st.chat_message(message["role"]): # 为给定角色渲染聊天行,包含在 with 块中的所有内容
st.markdown(message["text"]) #显示聊天内容
input_text = st.chat_input("Chat with your bot here") #聊天框
if input_text:
with st.chat_message("user"): # 显示用户聊天消息
st.markdown(input_text) # 渲染用户的最新消息
st.session_state.chat_history.append({"role":"user", "text":input_text}) #将用户的最新消息附加到聊天历史记录中。
chat_response = glib.get_chat_response(input_text=input_text, memory=st.session_state.memory) #通过支持库调用模型
with st.chat_message("assistant"): #显示机器人聊天消息
st.markdown(chat_response) #显示机器人的最新响应
st.session_state.chat_history.append({"role":"assistant", "text":chat_response}) #将机器人的最新消息附加到聊天历史记录中
复制3.4 深入体验 Amazon Bedrock 中 Meta Llama 3 、Amazon Titan Embeddings、LangChain 和 Streamlit 构建检索增强生成(RAG)支持的聊天机器人
在本节实验中,我们将使用 LangChain 的 ConversationSummaryBufferMemory 类来跟踪处理聊天历史,同时通过检索增强生成 (RAG) 用外部知识补充模型的基础数据。我们将使用 LangChain 的 ConversationalRetrievalChain 类在对 LangChain 的单个调用中将聊天机器人和 RAG 功能结合起来。
实验环境中我们将使用内存中的 FAISS 数据库来演示 RAG 模式。在实际的生产环境中,我们可能需要使用类似 Amazon Kendra 这样的持久数据存储或 Amazon OpenSearch Serverless 的矢量引擎。
以下为调用示例图:
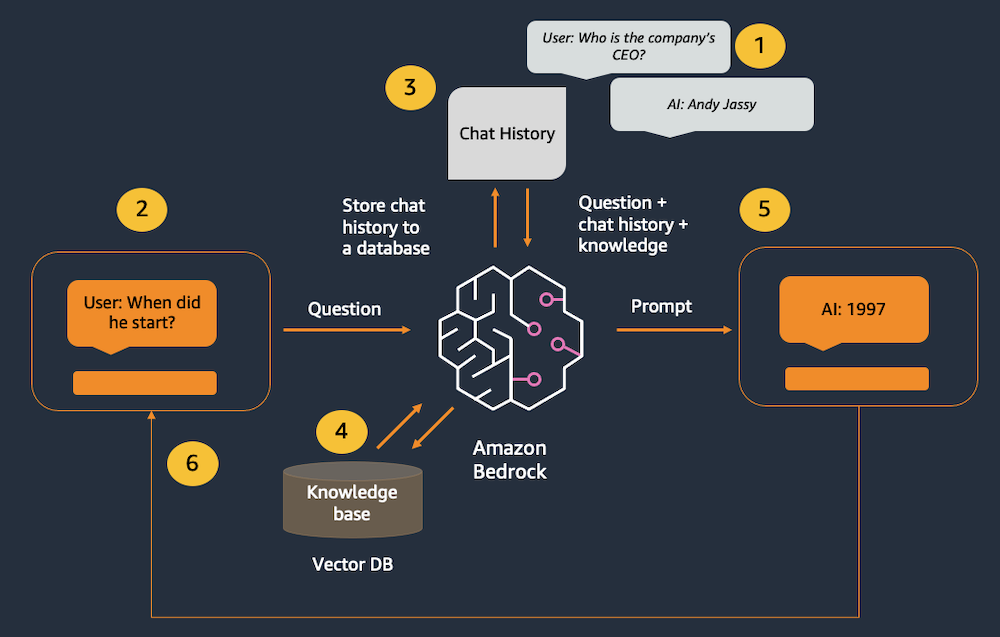
1、过去的交互在聊天在内存中存储
2、用户输入新消息
3、聊天历史记录是从内存对象中检索的,并添加到新消息之前
4、使用 Amazon Titan Embeddings 将问题转换为向量,然后与向量数据库中最接近的向量匹配
5、组合的历史记录、知识和新消息将发送到模型
6、模型的响应数据将显示给用户
应用程序由两个文件组成:一个用于 Streamlit 前端,一个用于支持库以调用 Amazon Bedrock
- 现在,打开 workshop/labs/rag_chatbot 文件夹, 打开文件 rag_chatbot_lib.py,并导入依赖
from langchain.memory import ConversationBufferWindowMemory
from langchain_aws import ChatBedrock as BedrockChat
from langchain.chains import ConversationalRetrievalChain
from langchain_community.embeddings import BedrockEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
复制- 添加一个函数来创建一个 Bedrock LangChain 客户端
def get_llm():
model_kwargs = {
"max_gen_len": 2048,
"temperature":0.5,
"top_p":0.9
}
llm = BedrockChat(
model_id="meta.llama3-8b-instruct-v1:0",
model_kwargs=model_kwargs) #设置调用模型
return llm
复制- 添加一个函数创建内存中向量存储
def get_index(): # 创建并返回一个内存中的向量存储,用于应用程序中
embeddings = BedrockEmbeddings() # 创建一个 Titan Embeddings 客户端
pdf_path = "2022-Shareholder-Letter.pdf" # 读取存在本地的 PDF 文件
loader = PyPDFLoader(file_path=pdf_path) # 加载 PDF 文件
text_splitter = RecursiveCharacterTextSplitter( # 创建一个文本拆分器
separators=["\n\n", "\n", ".", " "], # 按照(1)段落、(2)行、(3)句子或(4)单词的顺序,使用这些分隔符拆分块
chunk_size=1000, # 使用上述分隔符将其分成 1000 个字符的块
chunk_overlap=100 # 块与前一个块可以重叠的字符数
)
index_creator = VectorstoreIndexCreator( # 创建一个向量存储工厂
vectorstore_cls=FAISS, # 为了演示目的,使用内存中的向量存储
embedding=embeddings, # 使用 Titan 嵌入
text_splitter=text_splitter, # 使用递归文本拆分器
)
index_from_loader = index_creator.from_loaders([loader]) # 从加载的 PDF 创建向量存储索引
return index_from_loader # 将索引返回以由客户端应用程序进行缓存
复制- 添加初始化 LangChain 内存对象的函数,我们使用的是 ConversationBufferWindowMemory 类,能够跟踪最新的消息并总结较旧的消息,以便在长时间的对话中保持聊天上下文。
def get_memory(): # 定义一个名为 get_memory 的函数,用于创建此聊天会话的内存
memory = ConversationBufferWindowMemory(memory_key="chat_history", return_messages=True) # 创建一个名为 memory 的 ConversationBufferWindowMemory 对象,用于保存聊天历史记录,并且可以返回消息
return memory # 返回创建的内存对象
复制- 添加调用 Bedrock 函数,并保存文件
def get_rag_chat_response(input_text, memory, index): # 用于获取聊天响应
llm = get_llm() # 获取语言模型 (llm)
conversation_with_retrieval = ConversationalRetrievalChain.from_llm(llm, index.vectorstore.as_retriever(), memory=memory, verbose=True) # 从 llm 和索引的向量存储创建一个带有检索的对话链
input_text = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{input_text}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
chat_response = conversation_with_retrieval.invoke({"question": input_text}) # 将用户消息和摘要传递给模型并获取响应
return chat_response['answer'] # 返回响应中的答案
复制- 打开同一目录下的文件 rag_chatbot_app.py,并导入依赖
import streamlit as st # 所有 Streamlit 命令都可以通过 "st" 别名使用
import rag_chatbot_lib as glib # 对本地库脚本的引用
复制- 添加页面标题和配置
st.set_page_config(page_title="RAG Chatbot") #HTML title
st.title("RAG Chatbot") #page title
复制- 将 LangChain 内存添加到会话缓存中
if 'memory' not in st.session_state: # 判断内存是否尚未创建
st.session_state.memory = glib.get_memory() # 如果没有,初始化内存
复制- 将聊天历史记录添加到会话缓存中
if 'chat_history' not in st.session_state: # 查看聊天历史是否尚未创建
st.session_state.chat_history = [] # 初始化聊天历史
复制- 将向量索引添加到会话缓存中
if 'vector_index' not in st.session_state: # 查看向量索引是否尚未创建
with st.spinner("索引文档..."): # 在该 with 块中的代码运行时显示一个旋转器
st.session_state.vector_index = glib.get_index() # 通过支持库获取索引,并将其存储在应用的会话缓存中
复制- 添加 for 循环以呈现以前的聊天消息
# 重新渲染聊天历史(Streamlit 会重新运行此脚本,因此需要此操作来保留之前的聊天消息)
for message in st.session_state.chat_history: # 遍历聊天历史
with st.chat_message(message["role"]):
st.markdown(message["text"]) # 显示聊天内容
复制- 添加输入输出元素,并保存文件
input_text = st.chat_input("Chat with your bot here") # 显示一个聊天输入框
if input_text: # 在用户提交聊天消息后运行此 if 块中的代码
with st.chat_message("user"): # 显示一条用户聊天消息
st.markdown(input_text) # 呈现用户的最新消息
st.session_state.chat_history.append({"role":"user", "text":input_text}) # 将用户的最新消息附加到聊天历史记录中
chat_response = glib.get_rag_chat_response(input_text=input_text, memory=st.session_state.memory, index=st.session_state.vector_index,) # 通过支持库调用模型
with st.chat_message("assistant"): # 显示一条机器人聊天消息
st.markdown(chat_response) # 显示机器人的最新响应
st.session_state.chat_history.append({"role":"assistant", "text":chat_response}) # 将机器人的最新消息附加到聊天历史记录中
复制- 执行代码
cd ~/environment/workshop/labs/rag_chatbot
streamlit run rag_chatbot_app.py --server.port 8080
复制
预览方法:
打开 Cloud9 菜单栏->Preview->Preview Running Application
What are the key growth drivers for the company?
Who is the CEO?
我们可以针对 pdf 中的内容提问:

完整代码:
rag_chatbot_lib.py
from langchain.memory import ConversationBufferWindowMemory
from langchain_aws import ChatBedrock as BedrockChat
from langchain.chains import ConversationalRetrievalChain
from langchain_community.embeddings import BedrockEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
def get_llm():
model_kwargs = {
"max_gen_len": 2048,
"temperature":0.5,
"top_p":0.9
}
llm = BedrockChat(
model_id="meta.llama3-8b-instruct-v1:0",
model_kwargs=model_kwargs) #设置调用模型
return llm
def get_index(): # 创建并返回一个内存中的向量存储,用于应用程序中
embeddings = BedrockEmbeddings() # 创建一个 Titan Embeddings 客户端
pdf_path = "2022-Shareholder-Letter.pdf" # 读取存在本地的 PDF 文件
loader = PyPDFLoader(file_path=pdf_path) # 加载 PDF 文件
text_splitter = RecursiveCharacterTextSplitter( # 创建一个文本拆分器
separators=["\n\n", "\n", ".", " "], # 按照(1)段落、(2)行、(3)句子或(4)单词的顺序,使用这些分隔符拆分块
chunk_size=1000, # 使用上述分隔符将其分成 1000 个字符的块
chunk_overlap=100 # 块与前一个块可以重叠的字符数
)
index_creator = VectorstoreIndexCreator( # 创建一个向量存储工厂
vectorstore_cls=FAISS, # 为了演示目的,使用内存中的向量存储
embedding=embeddings, # 使用 Titan 嵌入
text_splitter=text_splitter, # 使用递归文本拆分器
)
index_from_loader = index_creator.from_loaders([loader]) # 从加载的 PDF 创建向量存储索引
return index_from_loader # 将索引返回以由客户端应用程序进行缓存
def get_memory(): # 定义一个名为 get_memory 的函数,用于创建此聊天会话的内存
memory = ConversationBufferWindowMemory(memory_key="chat_history", return_messages=True) # 创建一个名为 memory 的 ConversationBufferWindowMemory 对象,用于保存聊天历史记录,并且可以返回消息
return memory # 返回创建的内存对象
def get_rag_chat_response(input_text, memory, index): # 用于获取聊天响应
llm = get_llm() # 获取语言模型 (llm)
conversation_with_retrieval = ConversationalRetrievalChain.from_llm(llm, index.vectorstore.as_retriever(), memory=memory, verbose=True) # 从 llm 和索引的向量存储创建一个带有检索的对话链
input_text = f"""
<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{input_text}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
chat_response = conversation_with_retrieval.invoke({"question": input_text}) # 将用户消息和摘要传递给模型并获取响应
return chat_response['answer'] # 返回响应中的答案
复制rag_chatbot_app.py
import streamlit as st # 所有 Streamlit 命令都可以通过 "st" 别名使用
import rag_chatbot_lib as glib # 对本地库脚本的引用
st.set_page_config(page_title="RAG Chatbot") #HTML title
st.title("RAG Chatbot") #page title
if 'memory' not in st.session_state: # 判断内存是否尚未创建
st.session_state.memory = glib.get_memory() # 如果没有,初始化内存
if 'chat_history' not in st.session_state: # 查看聊天历史是否尚未创建
st.session_state.chat_history = [] # 初始化聊天历史
if 'vector_index' not in st.session_state: # 查看向量索引是否尚未创建
with st.spinner("索引文档..."): # 在该 with 块中的代码运行时显示一个旋转器
st.session_state.vector_index = glib.get_index() # 通过支持库获取索引,并将其存储在应用的会话缓存中
# 重新渲染聊天历史(Streamlit 会重新运行此脚本,因此需要此操作来保留之前的聊天消息)
for message in st.session_state.chat_history: # 遍历聊天历史
with st.chat_message(message["role"]):
st.markdown(message["text"]) # 显示聊天内容
input_text = st.chat_input("Chat with your bot here") # 显示一个聊天输入框
if input_text: # 在用户提交聊天消息后运行此 if 块中的代码
with st.chat_message("user"): # 显示一条用户聊天消息
st.markdown(input_text) # 呈现用户的最新消息
st.session_state.chat_history.append({"role":"user", "text":input_text}) # 将用户的最新消息附加到聊天历史记录中
chat_response = glib.get_rag_chat_response(input_text=input_text, memory=st.session_state.memory, index=st.session_state.vector_index,) # 通过支持库调用模型
with st.chat_message("assistant"): # 显示一条机器人聊天消息
st.markdown(chat_response) # 显示机器人的最新响应
st.session_state.chat_history.append({"role":"assistant", "text":chat_response}) # 将机器人的最新消息附加到聊天历史记录中
复制总结
本次实验主要是引导大家如何使用 Amazon Bedrock 上掌握 Stable Diffusion AI SDXL 1.0 运行环境创造独特艺术风格的图像和 Meta Llama 3 运行环境快速轻松地构建基于生成式人工智能的体验,开箱即用,可以快速上手;同时,也使用了 Amazon Titan Embeddings、Amazon Cloud 9 快速开发并部署简单的应用程序。最后也欢迎大家一起探索 Amazon Bedrock 更多的功能,为工作中赋能增效降本!
现在,是时候将所学付诸实践了。轻轻一点,注册海外账号,立即免费踏入属于您的云端构建世界。作为新注册的您,更能体验到长达12个月的免费使用权,涵盖云计算、云数据库、云存储与前沿的生成式 AI 服务等 100 余种云产品与服务。更值一提的是,您还将全面享受亚马逊云科技的海外区域节点,为您的实战构建之旅铺设坚实的基石。不再等待,立即开启您的云上探索之旅吧!
同时,在云上探索实验室中,我们还有更多丰富多彩的实验内容,让您的学习之旅永不止步。期待您的热情参与,共同体验这场技术的盛宴,一起成长,一起探索更广阔的科技天地。















 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









