







最近一直在忙于业务需求,突然发现很久没有整理技术文档了。之前我的习惯是把遇到的问题和自己整理的一些解决方案记录到印象笔记里面。以后尽量都搬到博客里面。
进入正题,做了快两年的推荐系统,从一无所知到略知一二,一路走来经历了很多,学到了很多东西。这篇文章主要梳理一下如何用spark来做ctr预估。
主要包括4部分
1 配置文件
2 特征提取
3 特征工程
4 模型训练
第一部分配置文件:这个文件里面配置的是训练日志天数,离散化参数配置,模型特征等等
比如 traning_days=7
第二部分特征提取:这一部分和业务日志结合比较紧密,通常是反作弊之后提取出展示日志,点击日志,用户信息,然后将展示点击日志合并,再扩展用户信息,商品信息,最终生成一条完整的日志。这一步主要基于Spark的RDD,以及Spark SQL完成,编程语言选择的是scala。日志产生之后按天保存到hive表里面。
例如:用户id,用户兴趣标签,用户性别,商品id,商品类别,商品详情,时间 是否点击
第三部分特征工程:首先说一下特征的命名方式,user_interest@car表示一个一维特征,user_interest,softid@car,999表示一个二维的交叉特征。
在特征工程里面首先是做特征的离散化,一是增强特征对异常数据的鲁棒性,另一方面也是方便做特征交叉。
离散化之后要做的就是特征交叉,根据配置文件自动的组合出模型训练需要的特征,对每条样本数据都做一次处理。
交叉之后做特征选择,去掉一些相关性不强,或者覆盖度太高或太低的特征。
最后做特征映射,目的是为了将我们的样本数据转换成特征向量,我们选择稀疏矩阵的存储方式。
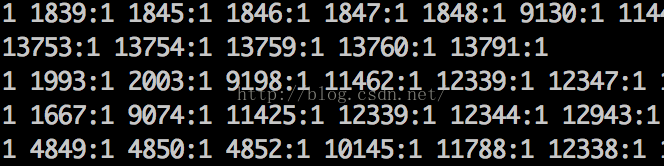
特征工程最后产生的就是如下用于模型训练的数据了
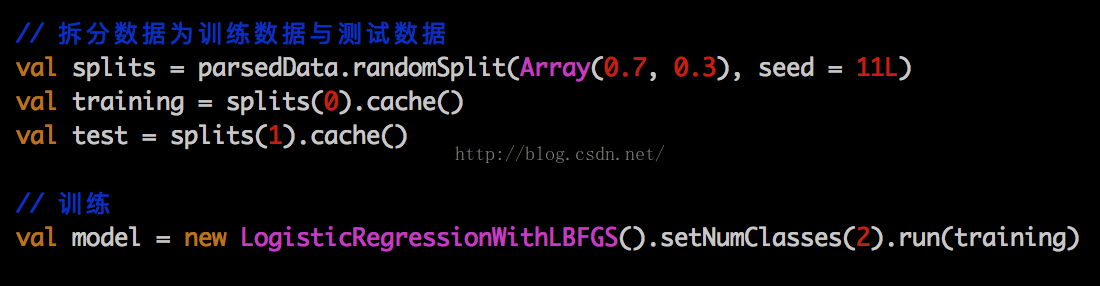
第四部分模型训练:训练数据产生之后,我们就可以用各种各样的模型来进行训练了,以逻辑回归为例
利用spark的libSVM库来加载稀疏矩阵

然后切分数据,利用mllib的LogisticRegressionWithLBFGS来进行训练
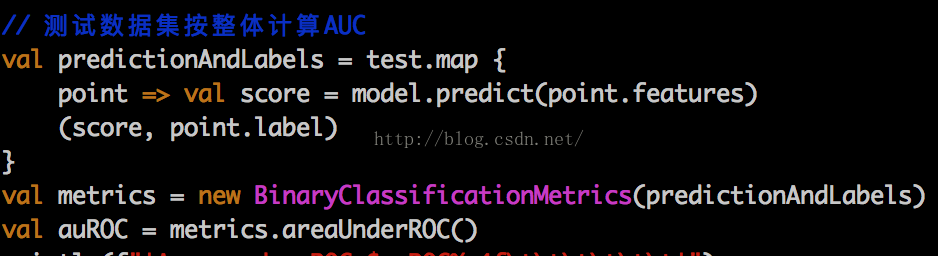
最后计算AUC
最后取到模型参数,将向量id映射回特征名称,更新线上模型,用于实时预测
最后:整个过程需要的技术基本都可以通过spark+scala完成,对scala不熟悉的同学可以考虑java,python等。














 564
564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









