







数据集简介
数据介绍
波士顿房价数据集(Boston Housing Dataset) 是一个经典的用于回归分析的数据集。它包含了波士顿地区506个街区的房价信息以及与房价相关的13个特征。这个数据集的目标是根据这些特征来预测波士顿地区房屋的中位数价格(以千美元为单位)
数据说明
Data Set Characteristics:
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive
:Median Value (attribute 14) is usually the target
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
目标变量
- MEDV:房屋的中位数价格,以千美元为单位
- 这个数据集常用于回归分析的学习和实践,例如线性回归、决策树回归、支持向量机回归和KNN回归等。通过分析这些特征与房价之间的关系,可以帮助我们更好地理解房价的影响因素。
KNN 回归建模
- 加载数据
- 数据拆分
- 交叉验证筛选最佳参数
- 模型评估预测
加载数据
导入包
from sklearn.neighbors import KNeighborsRegressor # 分类,平均值,计算房价中位数
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
X = data
y = target
y.shape
数据拆分
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
X_train.shape
交叉验证筛选最佳参数
# k值
k = [1,3,5,7,9,15,23,30]
# 权重
weights = ['uniform','distance']
# p表示距离的度量 :1:曼哈顿距离 2:欧式距离
p = [1,2]
# 生成字典
params = dict(n_neighbors=k,weights=weights,p=p)
# 创建模型
estimator = KNeighborsRegressor()
# 进行交叉验证
gCV = GridSearchCV(estimator, # 模型
params, # 参数
cv=5, # 分为几折
scoring='neg_mean_squared_error' # 指定评分对像
)
gCV.fit(X_train,y_train)
# 获取最佳参数
gCV.best_params_
# 获取最佳分数
gCV.best_score_
# 获取最好的模型
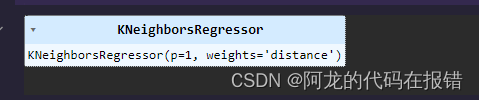
best_model = gCV.best_estimator_
best_model
模型评估预测
test = best_model.predict(X_test).round(1)
print(test[:20])
预测数据

print(y_test[:20])
真实数据

from sklearn.metrics import mean_squared_error # 均方误差
# 均方误差的值越小越好
mean_squared_error(y_test,test)
坚持学习,整理复盘

















 427
427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











