






姿态估计旨在 RGB 图片和 Video 中的人体像素映射到肢体的三维曲面(3D surface),其涉及了很多计算机视觉任务,如目标检测,姿态估计,分割,等等. 姿态估计的应用场景不仅包括关键点定位,如图形(Graphics),增强显示(Augmented Reality, AR),人机交互(Human-Computer Interaction,HCI),还包括 3D 目标识别的很多方面。
层出不穷的姿态检测深度网络模型,在最近两三年如雨后春笋般出现。今天我们选AlphaPose导出骨骼3D关键点位置,并在游戏引擎的去运行相关的模型。相关的代码都已提交到github, 我们提供算法解决视频2D到游戏3D骨骼的转换。算法不局限于抖音上的视频, 只是作者使用的视频都是从抖音上爬来的。
识别视频
首先将从抖音扒来的视频导入到模型,由AlphaPose生产识别后的运动姿势, 并使用Video3DPose中的方法渲染成视频, 如下:
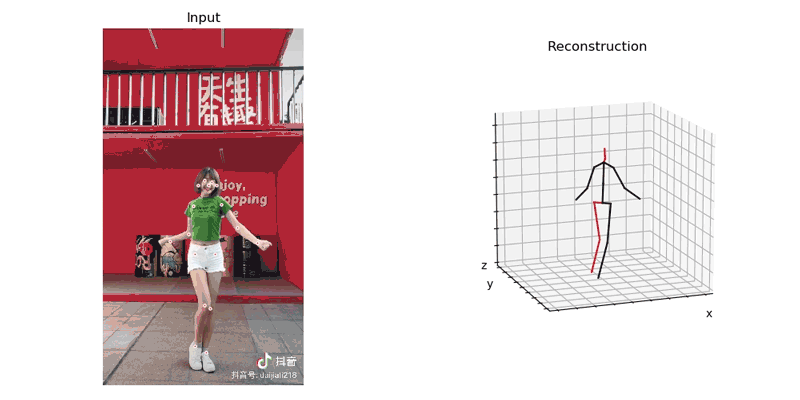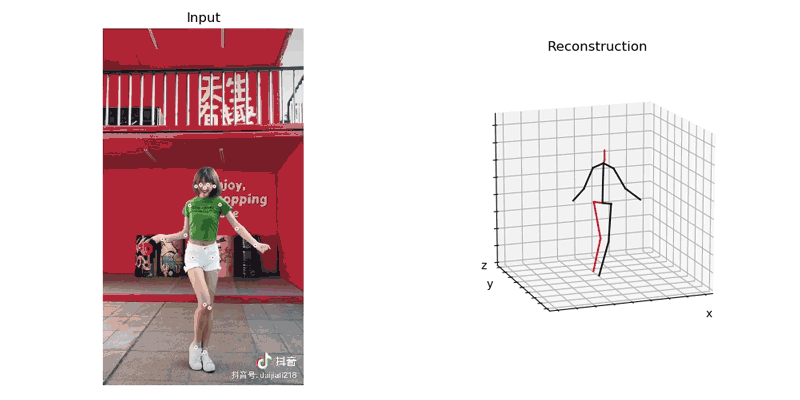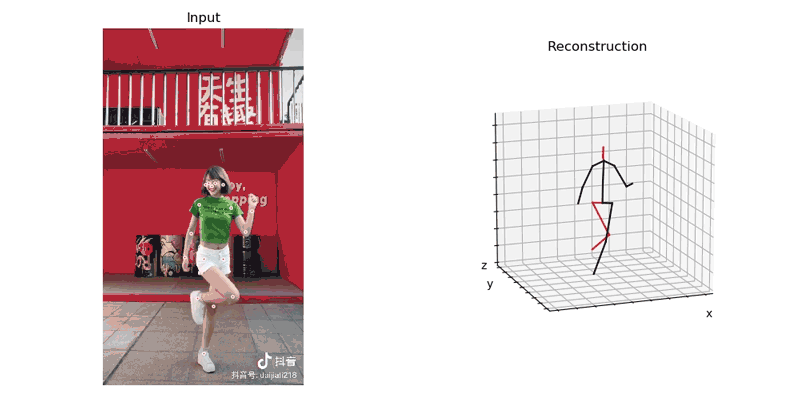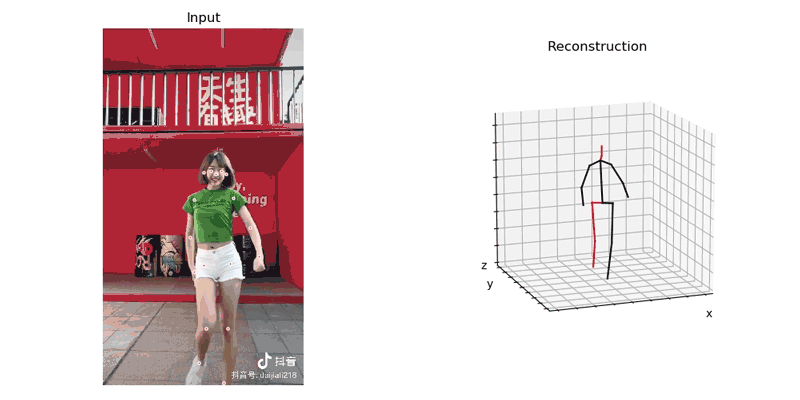
使用工具将numpy格式的数据转换成二进制(bytes), 以供之后在unity里解析使用。我们输出的时候查看numpy对象shape是(x,17,3), 地一维x代表帧数, 第二维代表17个关节,第三维代表关键点(joint)的3d位置。
Unity 运行模型
将上一步Python环境里生成的关键点信息(二进制文件),导入到Unity里,使用IO接口解析出来,由于Video3DPose默认使用的[hunman3.6数据集]骨骼的标记是17个部位,这里我们创建了17个GameObject,代表17个关节节点, 并使用LineRender组件把相关的关节连接成线。在Mono的Update函数,我们更新导出模型的3d关键点位置信息,于是一个运动的骨骼人行动起来了。 关于[hunman3.6数据集]关节编号的详细介绍,见本文最后的附录。
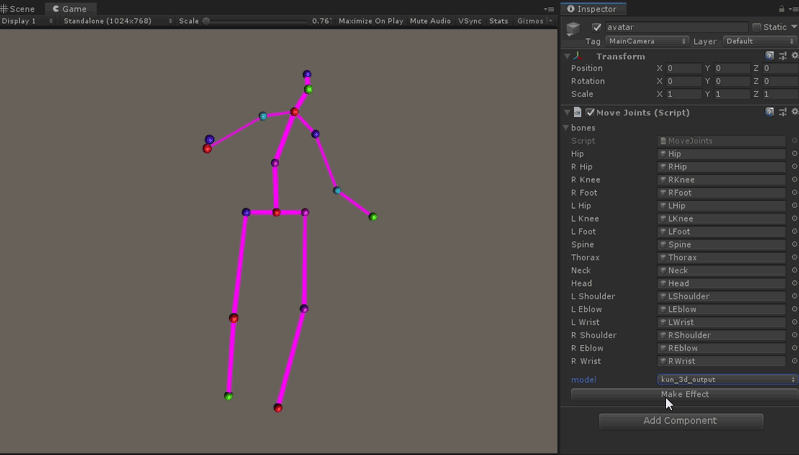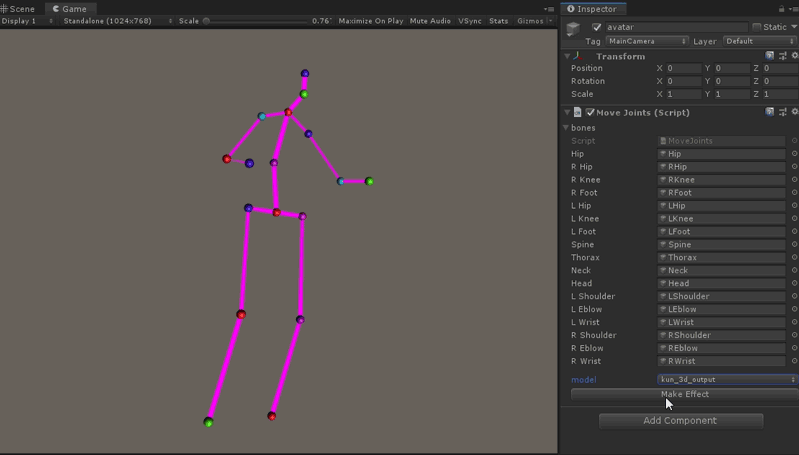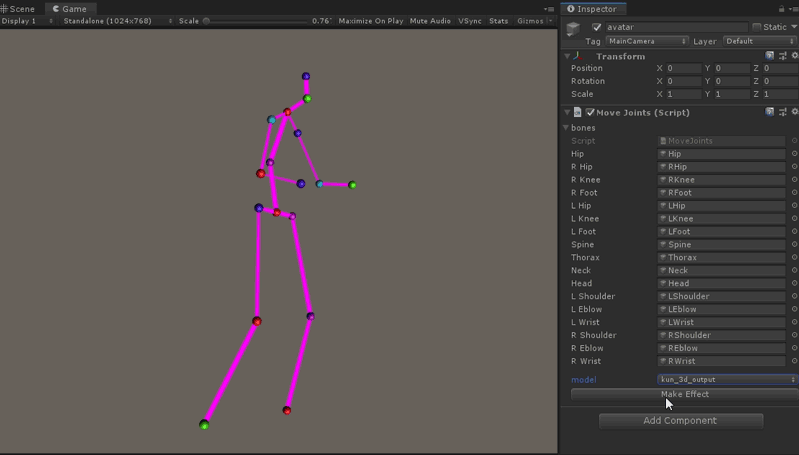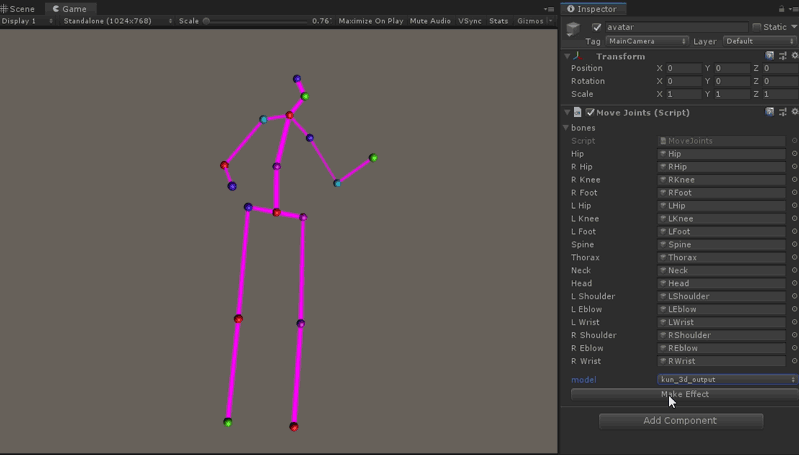
代码如下, 在Update中插值更新17组关节的位置,pose_joint数组的顺序对应到hunman3.6数据集关节编号。
protected override void LerpUpdate(float lerp)
{
Hip.position = Vector3.Lerp(Hip.position, pose_joint[0], lerp);
RHip.position = Vector3.Lerp(RHip.position, pose_joint[1], lerp);
RKnee.position = Vector3.Lerp(RKnee.position, pose_joint[2], lerp);
RFoot.position = Vector3.Lerp(RFoot.position, pose_joint[3], lerp);
LHip.position = Vector3.Lerp(LHip.position, pose_joint[4], lerp);
LKnee.position = Vector3.Lerp(LKnee.position, pose_joint[5], lerp);
LFoot.position = Vector3.Lerp(LFoot.position, pose_joint[6], lerp);
Spine.position = Vector3.Lerp(Spine.position, pose_joint[7], lerp);
Thorax.position = Vector3.Lerp(Thorax.position, pose_joint[8], lerp);
Neck.position = Vector3.Lerp(Neck.position, pose_joint[9], lerp);
Head.position = Vector3.Lerp(Head.position, pose_joint[10], lerp);
LShoulder.position = Vector3.Lerp(LShoulder.position, pose_joint[11], lerp);
LEblow.position = Vector3.Lerp(LEblow.position, pose_joint[12], lerp);
LWrist.position = Vector3.Lerp(LWrist.position, pose_joint[13], lerp);
RShoulder.position = Vector3.Lerp(RShoulder.position, pose_joint[14], lerp);
REblow.position = Vector3.Lerp(REblow.position, pose_joint[15], lerp);
RWrist.position = Vector3.Lerp(RWrist.position, pose_joint[16], lerp);
}
怎么能使游戏的Avatar的3D模型也能像输入模型那样运动起来呢? 换句话说,如何求一种解法将上一步的人形转换为游戏的绑定顶点的骨骼。我们知道3D角色的骨骼动画都是在CPU端层级计算的,上一级关节是下一节关节的原点坐标,由于关节之间的部位长度是固定的,于是问题转换成了求父关节的旋转,即四元数。当父关节的旋转固定的时候,子关节的位置随即也确定了。
对于旋转的求法, 先根据父子关节关系求一个角度, 然后在根据关键点模型里的位置算一个角度, 使用Quaternion.FromToRotation得到一个旋转四元数, 然后在当前的基础上旋转得到目标四元数,最后在Update里由当前插值到目标四元数就行了。代码实现如下:
private void UpdateBone(AvatarTree tree, float lerp)
{
var dir1 = tree.GetDir();
var dir2 = pose_joint[tree.idx] - pose_joint[tree.parent.idx];
Quaternion rot = Quaternion.FromToRotation(dir1, dir2);
Quaternion rot1 = tree.parent.transf.rotation;
tree.parent.transf.rotation = Quaternion.Lerp(rot1, rot * rot1, lerp);
}
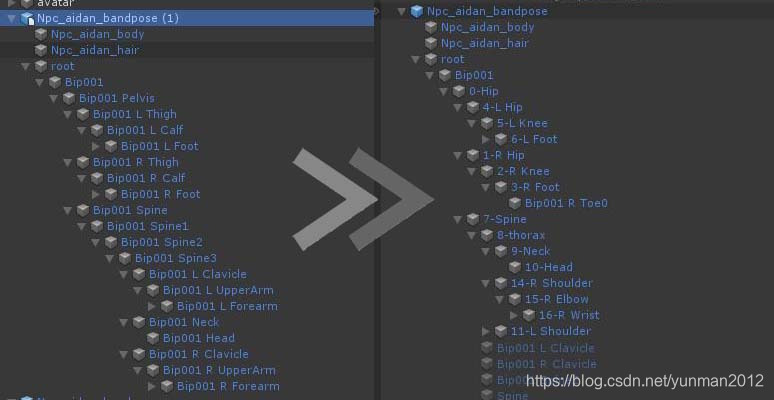
unity里运行效果如图所示:
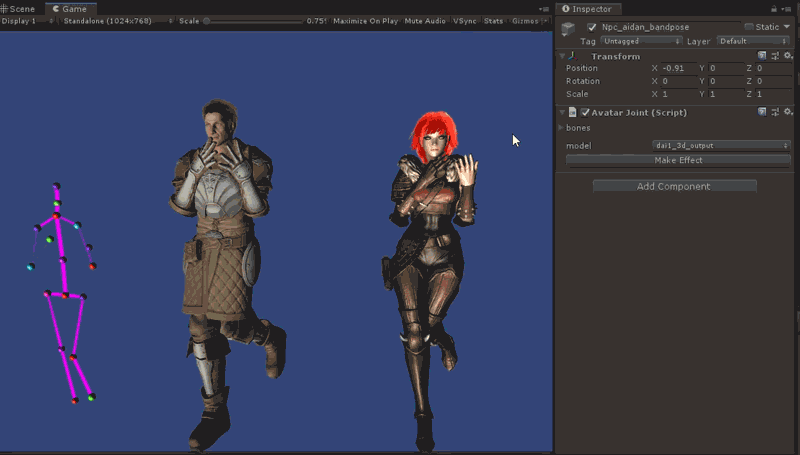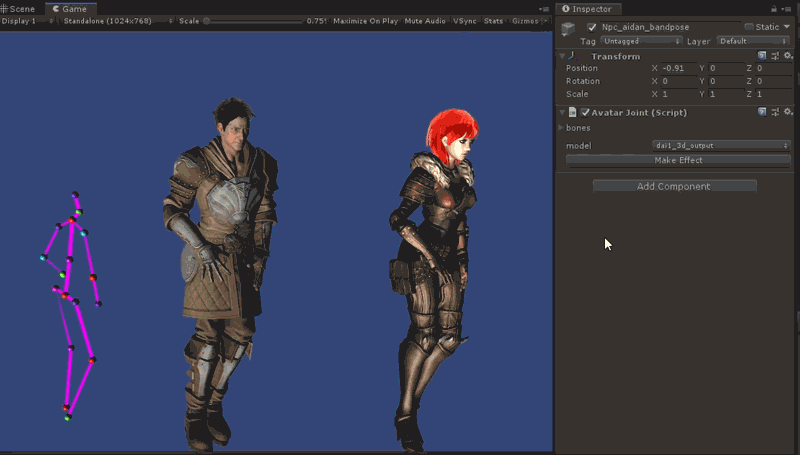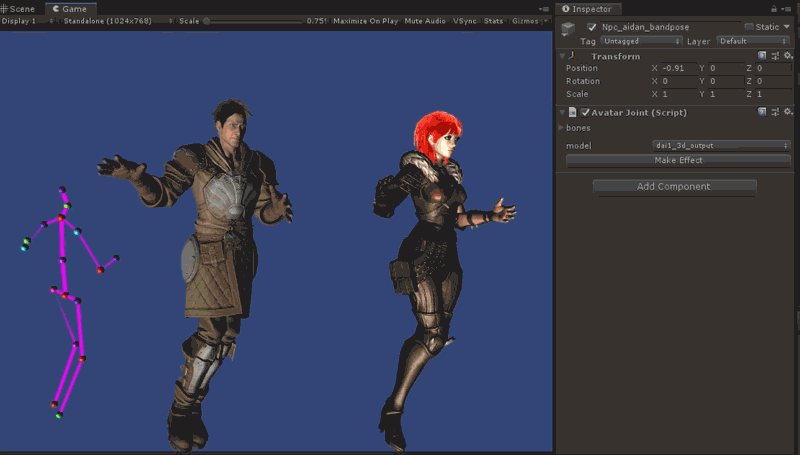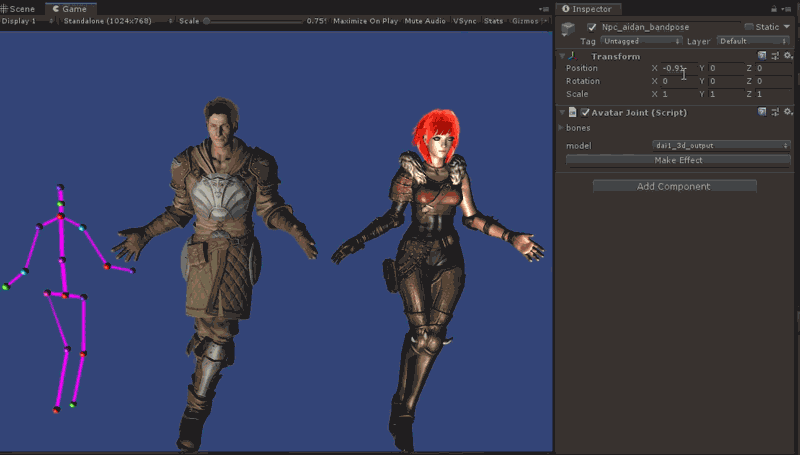
如果想看更多的运行效果,参考附录视频。
TIP
一般的情况下游戏里的Avatar关节和Human3.6数据集里的骨骼不是匹配的,往往游戏或者3D Max等美术制作的工具里的骨骼设置的更多,这时候可以跟动作设计师提出跟Hum3.6数据集的骨骼蒙皮解决方案。 如果是已经导出的fbx,我们也得保证关节层级的对应,应该上述算法得到的旋转四元数是基于父节点的local坐标系的。 解决方法就是把fbx在Unity引擎转换为Prefab, 然后再更改Prefab的关节层级结构。
从上面视频我们可以看到, AlphaPose 虽然能很好的识别出骨骼节点的位置, 但这不包含手指等小关节的姿势, 所以从上而下手都是僵硬的, 但是从卡内基梅隆大学的OpenPose(最新版)已经能识别手指的动作,甚至还包含一些脸部的表情,真的是非常强大了。
附录1:
姿态估计开源深度学习模型汇总:
AlphaPose
AlphaPose 是上海交通大学开源的精确多人姿态估计,声称是第一个开源系统.
AlphaPose 可以同时对图片, videos,以及图片列表,进行姿态估计和姿态追踪(pose tracking). 可以得到很多不同的输出,包括 PNG,JPEG,AVI 格式的关键点图片,JSON 格式的关键点输出,便于很多应用场景.AlphaPose 采用区域多人姿态估计(regional multi-person pose estimation, RMPE)框架,以在人体边界框不准确的情况下,提升姿态估计. 其主要包括三部分:
- Symmetric Spatial Transformer Network (SSTN)
- Parametric Pose Non-Maximum-Suppression (NMS)
- Pose-Guided Proposals Generator (PGPG)

OpenPose
OpenPose 是 CMU Perceptual Computing Lab 开源的一个实时多人关键点检测库.
OpenPose 提供了 2D 和 3D 多人关键点检测方法,以及特定参数的姿态估计的标准化工具包.
OpenPose 可以采用很多不同的输入方式,如,图片image, 视频video,IP相机camera,等等.
OpenPose 的输出也可以是很多不同形式,如图片和关键点(PNG,JPG,AVI),可读格式的关键点(JSON,XML,YML),甚至是数组类.OpenPose 的输入和输出参数,还可以根据需要进行调整. OpenPose 提供了 C++ API,可以在 CPU 和 GPU 上运行,也兼容 AMD 显卡.

DensePose
DensePose 出自 Facebook Research,其开源了 DensePose 实现的代码,模型和数据集.
DensePose 数据集,DensePose-COCO,用于人体姿态估计的大规模数据集.
DensePose-COCO 数据集,是在 50K COCO 图片上手工标注的图片-表面(image-to-surface)对应的大规模数据集.

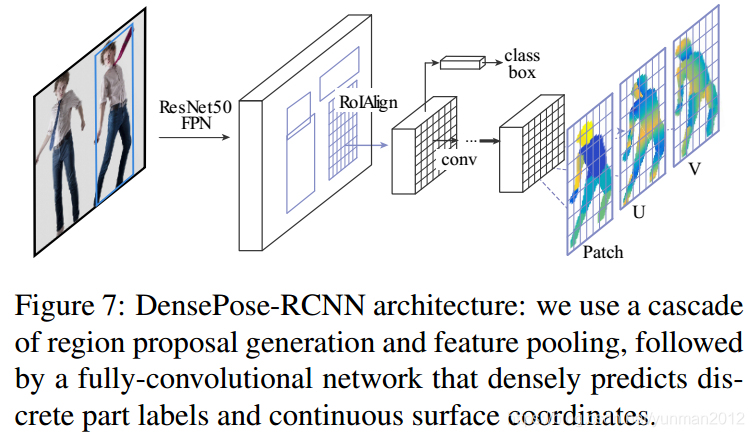
DensePose 论文提出了 DensePose-RCNN,是 Mask-RCNN 的一个变形,针对每秒多帧的每个人体区域,其回归密集地回归特定肢体部分的 UV 坐标.
DensePose 基于 DenseReg: Fully Convolutional Dense Shape Regression In-the-Wild - 2016.
DensePose 的目标是确定每个像素点的曲面位置(surface location),以及该肢体曲面所属的对应 2D 参数化.
DensePose 采用了基于 FPN 的 Mask R-CNN 结构,RoI-Align Pooling.
此外,DensePose 在 RoI-Pooling 的输出端加入全卷积网路.
附录2
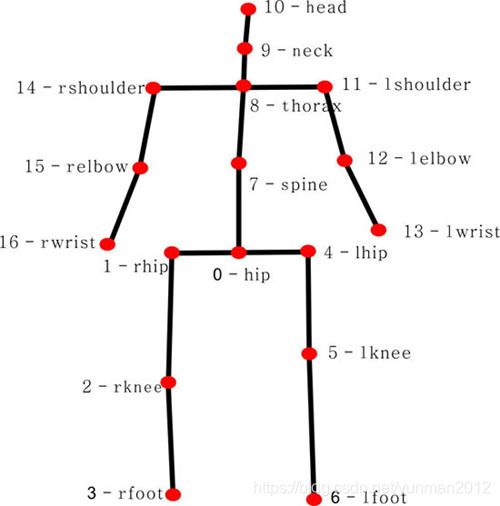
human3.6m关节点标注顺序
| 序号 | 数据集标注顺序 | 关节名 | 中文名 |
|---|---|---|---|
| 0 | 0 | hip | 臀部 |
| 1 | 1 | rhip | 右臀部 |
| 2 | 2 | rknee | 右膝盖 |
| 3 | 3 | rfoot | 右脚踝 |
| 4 | 6 | lhip | 左臀部 |
| 5 | 7 | lknee | 左膝盖 |
| 6 | 8 | lfoot | 左脚踝 |
| 7 | 12 | spine | 脊柱 |
| 8 | 13 | thorax | 胸部 |
| 9 | 14 | neck | 颈部 |
| 10 | 15 | head | 头部 |
| 11 | 17 | lshoulder | 左肩 |
| 12 | 18 | lelbow | 左手肘 |
| 13 | 19 | lwrist | 左手腕 |
| 14 | 25 | rshoulder | 右肩 |
| 15 | 26 | relbow | 右手肘 |
| 16 | 27 | rwrist | 右手腕 |
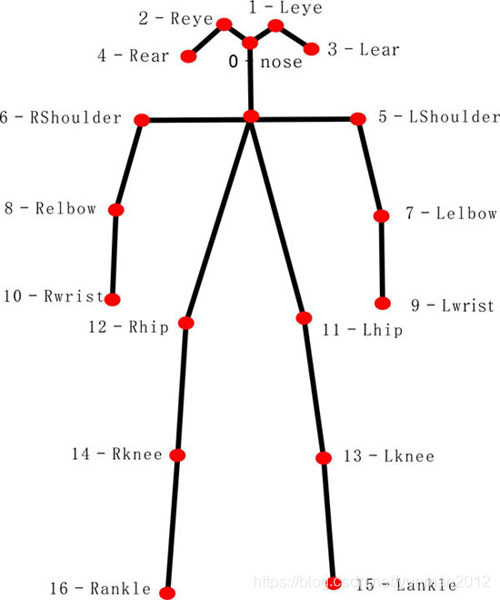
COCO数据集骨骼关节keypoint标注对应
| 序号 | 数据集标注顺序 | 关节名 | 中文名 |
|---|---|---|---|
| 0 | 0 | nose | 鼻子 |
| 1 | 1 | L eye | 左眼 |
| 2 | 2 | R eye | 右眼 |
| 3 | 3 | L ear | 左耳 |
| 4 | 4 | R ear | 右耳 |
| 5 | 5 | L shoulder | 左肩 |
| 6 | 6 | R shoulder | 右肩 |
| 7 | 7 | L elbow | 左手肘 |
| 8 | 8 | R elbow | 右手肘 |
| 9 | 9 | L wrist | 左手腕 |
| 10 | 10 | R wrist | 右手腕 |
| 11 | 11 | L hip | 左臀部 |
| 12 | 12 | R hip | 右臀部 |
| 13 | 13 | knee | 左膝盖 |
| 14 | 14 | R knee | 右膝盖 |
| 15 | 15 | L ankle | 左脚踝 |
| 16 | 16 | R ankle | 右脚踝 |
附录3
更多从抖音扒来的的视频姿势识别参见:
参考文献:

















 272
272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









