









- llama3&Grok
目前开源的超级大模型有Gork和Llama3
https://github.com/xai-org/grok-1;该模型称为史上最大开源LLM,参数高达3140亿!马斯克如约开源Grok,10小时狂揽10000颗Star,搞笑的是这个模型只开源了推理没有训练,同时这个模型按照源码分析是encoder-moe-decoder架构。
https://github.com/meta-llama/llama3;官方介绍 是目前提供生成式AI能力免费能力最大LLM,参数量4000亿!有了llama3全世界就能拥有最强大人工智能。
一:目前已经开源了8B和70B版本的llama3模型,包括提供预训练和微调不同的版本,这个确实能直接推动众多垂直和通用领域大模型基础研究和应用应用。
二:几个月后Meta将推出更大的400B+模型。Meta研究人员Aston Zhang在介绍中称研究团队本次对预训练方法、长文本、后训练、微调等众多领域进行相关研究工作。
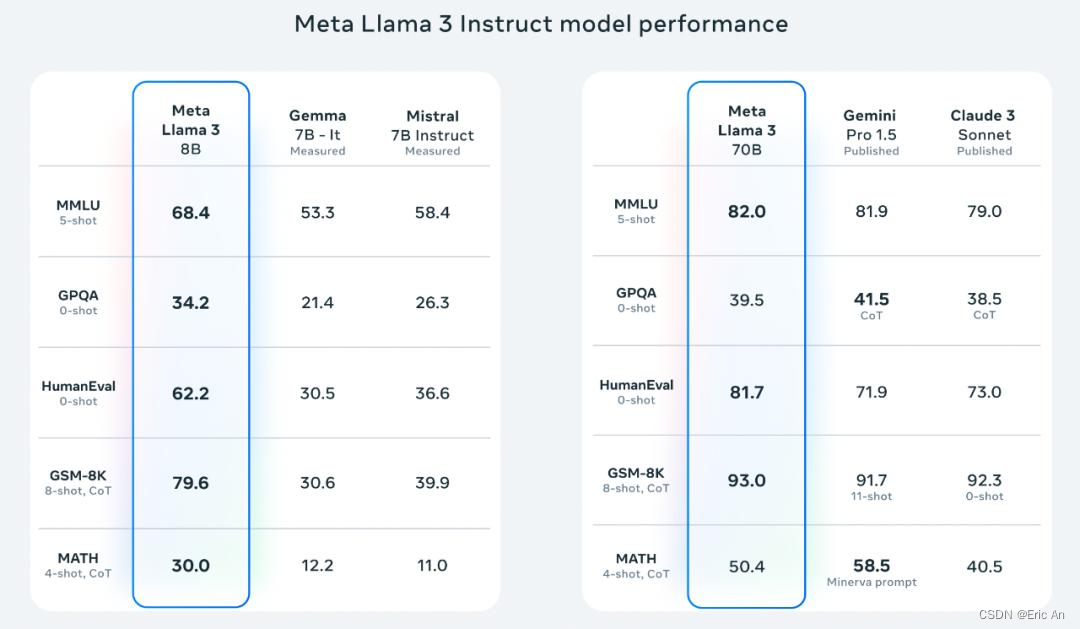
三:相关工作为preturning和postingtraining上进行了数据和规模性提升,使用了2.4万个GPU集群,超过了15T的token完成基础训练,数据量是llama2的7倍,代码是llama2的4倍,支持8k的上下文是llama的3倍。
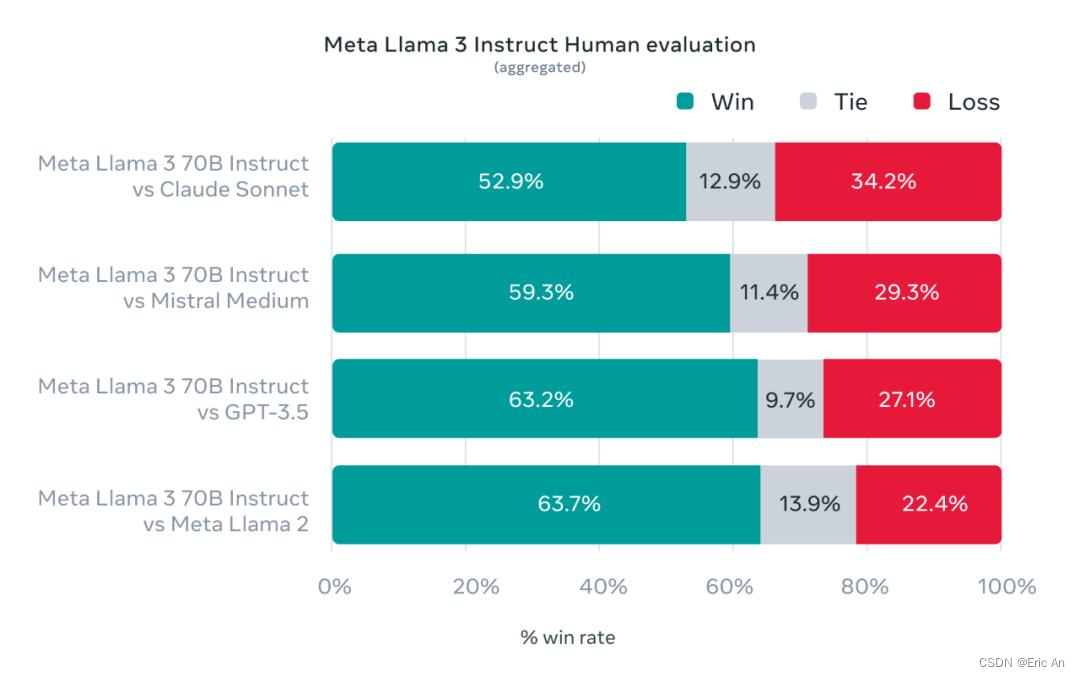
四:学习了人类高质量数据1800个提示涵盖12个关键用例(建议、思考、分类、封闭式问答、编码、写作、提取、角色、开放式问答、推理、重写总结),同时为了防止过拟合他们进行了相关工作人类评估。
五:模块结构方面采用了decoder-only设计思路,与llama2的关键改进为:
5.1 : 使用了128k的词汇表做tokenizer实现更加有效的分词从而显著的提高模型性能,并将sentencepiece换成了tiktoken。
5.2: 在自注意力阶段为了提升模型的推理效率,研究团队在目前开源的8B和70B模型均采用了分组查询注意力GQA。
5.3: 数据上在预训练阶段使用了15T的token,超过了30种语言,其中英语以外的语言占比5%。为了接受高质量的数据实现了一系列数据过滤的pipline,包括启发式过滤器、NSFW过滤器、语义重复删除法、文本分类器来预测数据质量,从而实现了为模型提供高质量的学习数据,此次最大的更新是仔细整理数据及人类注释进行多轮质量对齐。
5.4: 广泛的工程实验评估,测试包括日常提问、STEM、编码、历史等表现最佳。后训练方法采用了SFT有监督学习,拒绝采样、PPO和DPO组合、SFT使用的prompt质量和PPO中使用了偏好排序实现了模型对齐大幅提升。
5.5: 预训练在H100上进行了770万个GPU的小时计算、同时实现了数据并行、模型并行、管道并行,实现了有效训练时间超过95%。从而使得训练效率提升了3倍。
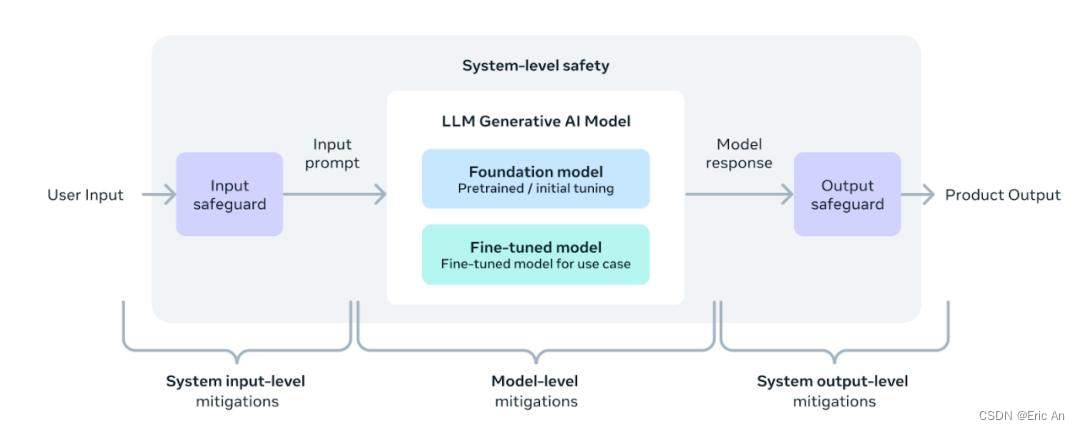
5.6: 增加了信任安全工具llama guard和cybersec eval,并且引入了code shield实现大模型在代码中对不安全代码拦截。
5.7: 使用了torchtune开发了llama3,可以更加便捷使用LLM模型创作、微调、实验。它可以高效的内存分析训练方法,同时与众多平台集成方便不同设备移植高效推理。同时还提供了和LangChain结合使用的开发部署的解决方案。
目前相关组织已经完成了对汉语的base和instruct模型
Github: https://github.com/UnicomAI/Unichat-llama3-Chinese
HF: https://huggingface.co/BoyangZ/llama3-chinese
shareAI/llama3-Chinese-chat-8b · Hugging Face
https://huggingface.co/xtuner/llava-llama-3-8b-v1_1
模型部分核心代码对比图

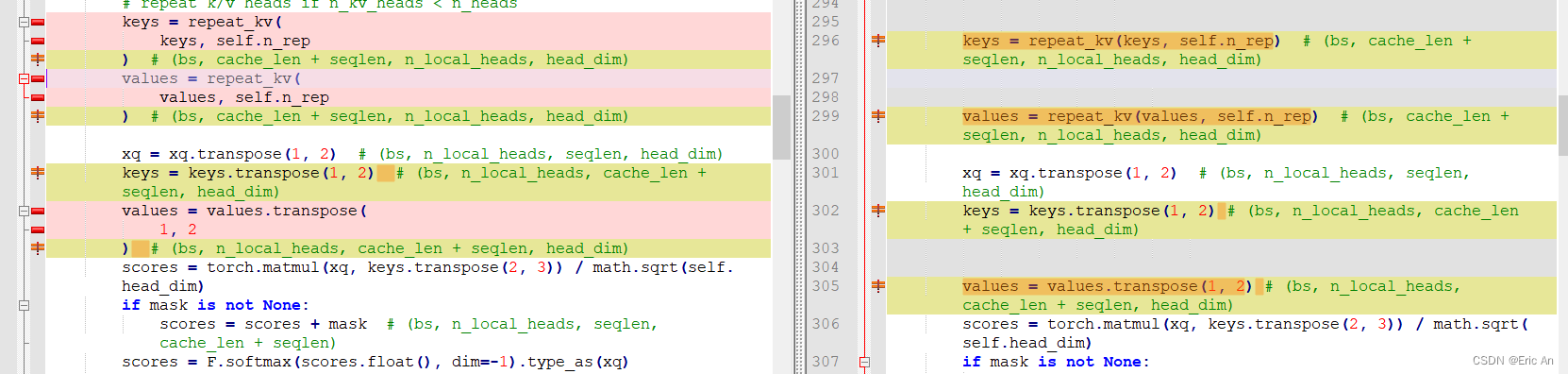
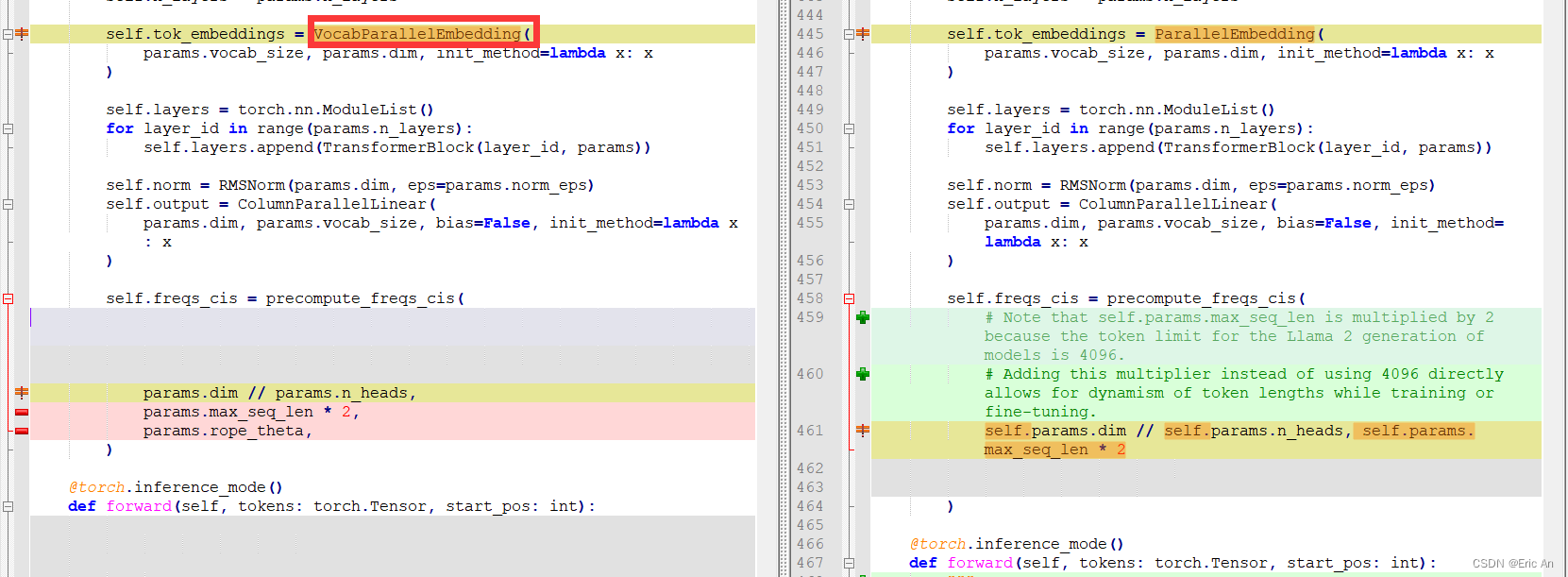
- Grok,马斯克旗下XAI开源了3140亿参数的混合专家模型Grok-1,成为迄今参数量最大的开源LLM。该模型在大量文本数据上训练,未针对特定任务微调,遵守Apache-2.0许可证,鼓励开发者使用、修改和分发。尽管存在关于开源技术利弊的争议,马斯克坚信开源将推动AI技术的发展。
- Grok,从源码分析这个模型结构同时基本熟悉了下这个模型属于MoE类的编解码设计范式,并且这个模型并没有开源训练代码,所以这种其实原则上不算开源,有炒作嫌疑。







综上述,根据我们对模型结构和训练方法的理解结论如下:
数据质量非常影响模型效果,在控制变量法的消融实验中增加高质量的数据可以线性提升性能。
影响模型推理最严重的问题是attention结构,其实kvcache可以根据设计attention,数据并行,结构并行提升。
目前google和openai在scaling law的观点是对立的,那么在工程上应该这种对立是统一的,也就是说在一定范围内两种方法都是有效的,只是不同的有效边界问题没解决。
个人针对大模型目前从以下几个角度开始学习研究:tokenizer算法、embedding算法、encoder-only,decoder-only,decoder-moe-only、activation function、loss function、数据并行、结构并行。
















 753
753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









