







思考:自己设计一份分布式文件系统
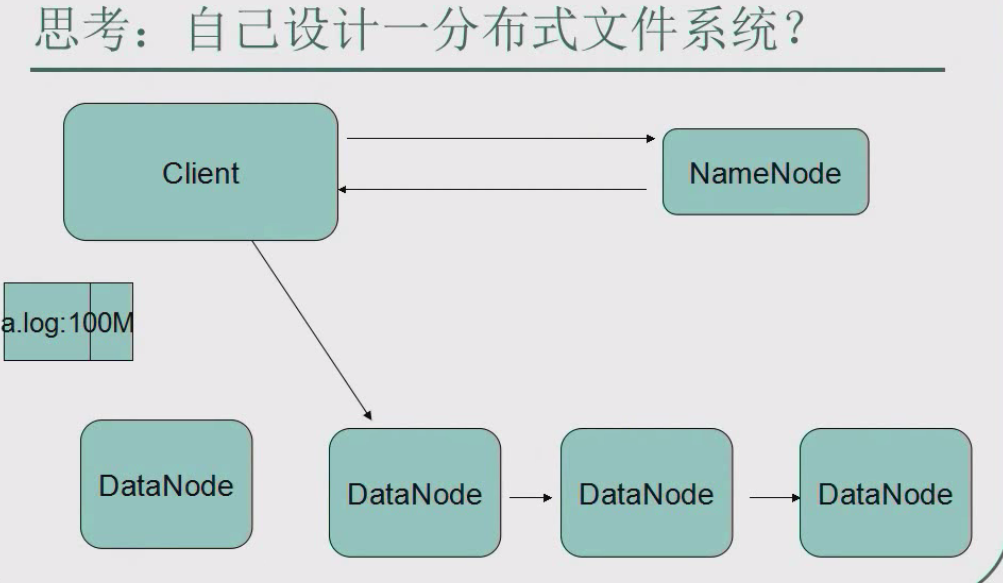
hdfs有两种角色:
namenode,
datanode.
(secondarynamenode先不考虑)
一个namenode,多个datanode。
namenode相当于仓库管理员,维护自己的一个账本
datanode相当于仓库,负责存储数据
client相当于送货员
a.log:100M 货物
客户端向namenode发送一个上传数据的请求
namenode查看每个datanode信息,看哪个仓库可以放东西,
并将保存位置的信息记录下来(保存到账本上,为了以后能找到该数据)
并将这条信息发送给客户端
客户端 知道了要把文件放到哪个仓库,
与那个datanode进行联系,将数据写入到datanode里面
datanode将数据复制到其他datanode上备份
最后将写成功的信息反馈给client注:副本并不是client写多次,而是datanode的水平复制
注:元数据信息保存在namenode里面
数据上传还会分块
Hadoop1.0 每个块默认64M
Hadoop2.0 每个块默认128M
client每写128M(一个块),就向namenode申请一个存放的datanode地址
写满一个,申请一个。。 写满一个,申请一个。。 写满一个,申请一个。。。
为什么要分块存储?
上传1G的文件,一共分8块。
上传。。
上传。。
上传。。
前7块都上传成功了,第8块出现问题了。
那么怎么办呢? —只要重新写第8块就可以了。
如果不是分块的,那么写到一半失败了,只能从头再写。
读取1G文件。
读取文件读到99%,出错了。 还得从头重新开始读。
如果分块,读到第八快出错了。 直接在另一个datanode上重新读第8块即可。
分布式文件系统介绍

常见分布式文件系统
GFS、HDFS、Lustre、Ceph、GridFS、mogileFS、TFS(淘宝的分布式系统)、FastDFS、















 2457
2457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









