







使用未标记数据进行显式和隐式知识蒸馏
一、Abstract
对于原始数据集不可用的场景,无数据知识蒸馏是一项具有挑战性的模型轻量级任务。以前的方法需要大量额外的计算成本来更新一个或多个生成器,它们幼稚的模拟学习导致蒸馏效率较低。在此基础上,我们首先提出了一种有效的无标记样本选择方法来取代高计算生成器,并着重于提高所选样本的训练效率。然后,设计了一种降类机制来抑制由数据域偏移引起的标签噪声。最后,我们提出了一种结合显式特征和隐式结构关系的蒸馏方法来提高蒸馏的效果。实验结果表明,该方法能快速收敛,收敛速度能获得更高的精度。
二、Introduction
在这里插入图片描述
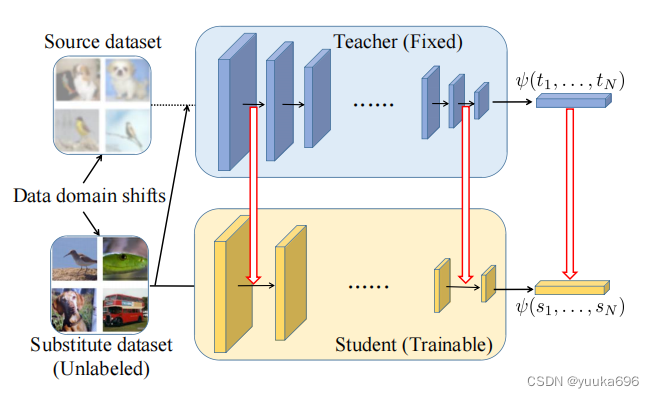
图:pipeline。在培训期间,只有教师模型和未标记的替代数据集可用。红色箭头表示我们提出的显式和隐式蒸馏损失。
贡献:我们提出了一种有效的显式和隐式知识蒸馏方法,该方法选择了未标记的替代样品,而不需要额外的生成模块计算和参数成本。
• 为了从替代数据集中寻找更有效的样本,我们提出了一个自适应阈值选择模块,该模块综合考虑了未标记样本的置信度和信息内容。
• 设计了一种轻量级的降类机制来抑制标签噪声。然后,结合外显知识和内隐式知识,显著提高了收敛速度和学习效率。
• 实验结果表明,与以往的最先进的DFKD方法相比,我们的EEIKD方法显著提高了学生的成绩。
三、Networks
1.Adaptive Threshold Selection自适应阈值选择
为了消除不必要的生成器成本,我们提出了一种无标记的数据选择方法。同时,我们尝试选择合适的样本来提高学习效率。一方面,教师网络对未标记样本的高置信度预测意味着它能更好地理解样本,这有助于提高样本的利用率。另一方面,置信度越高意味着教师网络的预测更接近one hot。与软目标相比,其预测比软目标[27]具有更低的熵,并且可以提供更少的训练信息,从而降低了样本的利用效率。在这里,我们设计了一个机制来平衡这两个部分。
我们将未标记的输入样本表示为 x x x,类别的数量表示为 n n n,未标记的替代数据集表示为 X \mathcal{X} X( x ∈ X x \in \mathcal{X} x∈X),候选数据集表示为 X ′ \mathcal{X}' X′以及选择后的最终学生训练数据集表示为 X ′ ′ \mathcal{X}'' X′′。
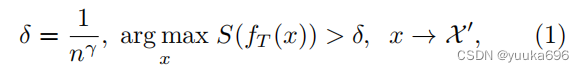
其中 δ \delta δ是自适应阈值, γ \gamma γ是满足 0 < γ < 1 0 < \gamma < 1 0<γ<1的超参数, S S S是softmax函数, f T ( x ) f_T(x) fT(x)是教师网络的预测。然后在 X ′ \mathcal{X}' X′中选择 n s n_s ns个样本来形成训练集 X ′ ′ \mathcal{X}'' X′′。随着 γ \gamma γ的增加和 δ \delta δ的减少,带有更多信息的样本被赋予了更高的价值。随着 γ \gamma γ的减少和 δ \delta δ的增加,选择了更有信心的样本。通过自适应阈值设置,低信心或信息量太少的样本将不会被选中。因此,最终选择了效率高的样本,这可以更好地帮助学生表现良好。
2.Class-Dropping Noise Suppression降级噪声抑制
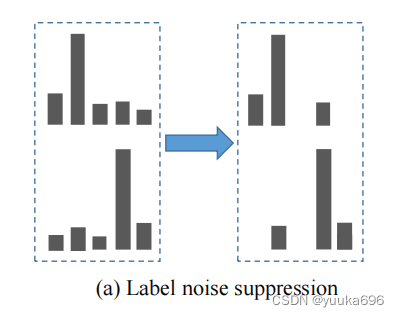
由于不可用的原始数据集和未标记的替代数据集之间的类存在差异,我们提出了一个去类的噪声抑制模块来面对数据集的域偏移,并提高了学生网络的学习效果。教师网络对低置信度的类给出的预测往往受到数据集域之间的变化的影响。首先,对这些部分的预测并不会对最终的结果产生积极的影响。此外,它还影响了噪声等复杂样本的学习效率。在这里,我们提出了一种简单而有效的置信掩模方法来抑制来自图(a)中所示的未标记数据域位移的噪声。
3. Explicit and Implicit Knowledge Distillation显式和隐式知识蒸馏
3.1 Knowledge distillation loss
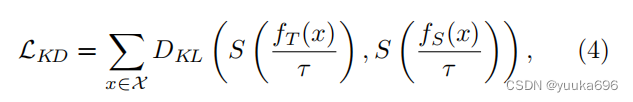
学生输出与教师输出-KL散度,面对数据集域的转移不算太有效。
3.2 Explicit feature distillation
在多层神经网络中,底层的输出局部与纹理信息有关。高水平的产出愿景正在逐渐增强,全球信息也日益集中。在这里,我们选择第一批归一化(BN)层[29]之后的输出和最后一个线性层之前的输入。前者注重局部纹理特征,并保留了训练图像的特征,有助于学生网络的快速收敛。后者与最终效果直接相关。注意蒸馏损失描述为:
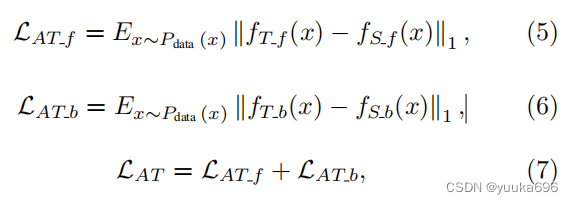
其中
∥
⋅
∥
1
\| \cdot \|_1
∥⋅∥1是
ℓ
1
\ell_1
ℓ1范数,
f
T
f
(
x
)
f_{T_f}(x)
fTf(x)和
f
T
b
(
x
)
f_{T_b}(x)
fTb(x)是在教师网络的第一个BN层之后以及最后一个线性层之前的输出,
f
S
f
(
x
)
f_{S_f}(x)
fSf(x)和
f
S
b
(
x
)
f_{S_b}(x)
fSb(x)是学生网络的两层输出。我们相信通过学习这些特征我们可以获得更快的收敛速度。相关的实验验证将在下一节中介绍。
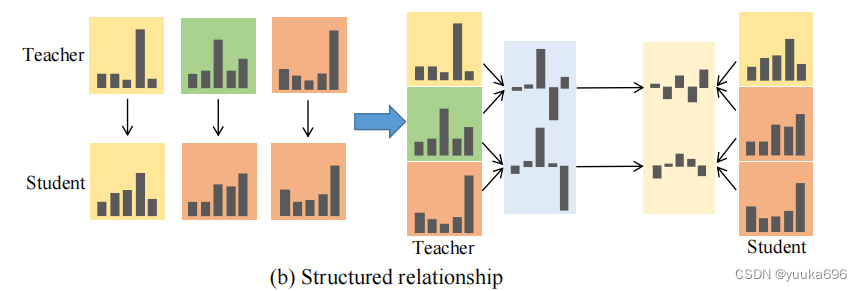
3.3 Implicit structured relation distillation
在模型学习的过程中,不同类的学习效果通常是不同的。直接学习复杂的类是具有挑战性的,但相对容易学习小批量中样本置信度分布的差异。我们的目标是通过图(b)所示的结构化关系蒸馏,有效地学习复杂类结构化关系表示多个样本之间的连接,而不是单个样本实例。
我们将批量大小表示为
N
N
N,结构化差异关系表示为
ψ
\psi
ψ,教师的预测表示为
f
T
N
=
(
t
1
,
…
,
t
N
)
f_{T}^{N} = (t_1, \ldots, t_N)
fTN=(t1,…,tN)以及结构化差异损失表示为
L
D
L_{D}
LD。隐式结构化蒸馏计算如下:
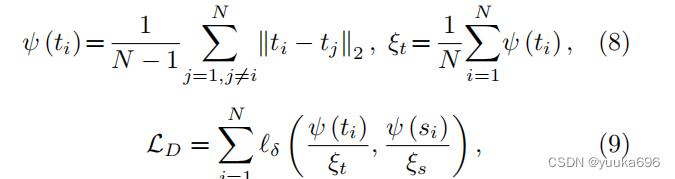
其中 ℓ δ \ell_{\delta} ℓδ是Huber损失。学生的结构化差异关系 ψ ( s i ) \psi(s_i) ψ(si)类似于等式8。最终,加一起得到总损失:
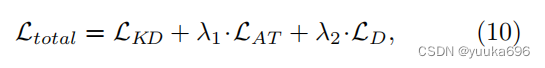
其中 λ 1 , λ 2 \lambda_1, \lambda_2 λ1,λ2是损失权衡参数。
四、Experiments
1、Settings
数据集:我们的设置是选择可以更好地帮助学生从未标记的替代数据集中学习的样本,以替换DFND [25]之后不可用的源数据集。
不可用的源数据集:32×32 CIFAR-10和CIFAR- 100 [30]包含来自10个和100个类的50K训练和10K测试数据集。
未标记的替代数据集: ImageNet数据集[26]。ImageNet数据集被调整为32×32,以满足原始模型的输入要求。ResNet-34 [32]作为教师网络,并选择ResNet-18 [32]作为过去baseline后的学生网络。
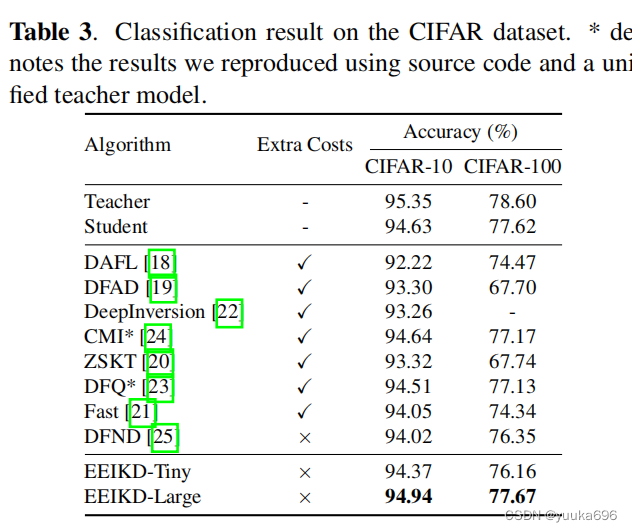
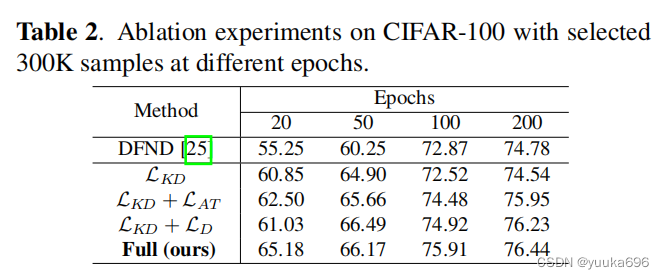
消融实验。
五、Conclusion
`在本文中,我们首先提出了一个自适应阈值模块来选择更有效的样本。然后,在此基础上,提出了一种抑制数据域间标签噪声的类丢弃机制。最后,通过在教师和学生之间添加特征蒸馏和学习隐式结构关系,学生可以快速收敛,更好地学习,甚至将训练后的学生网络的性能与原始数据相匹配。CIFAR-10和CIFAR-100数据集的准确率分别为94.94%和77.67%,优于其他无数据知识蒸馏方法。
主要想看看那个结构化关系蒸馏,不过看起来就是用的教师预测,提取了教师预测的相互关系,再看看有没有其他结构化的知识提取的方法。而且怎么比较还没有想好。















 5900
5900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









