






一、目的与架构
主要解决大数据存储问题
分布式文件系统:
二、设计目标:
- 通过多个廉价的计算机集群分布数据和处理来节约成本
- 通过自动维护多个数据副本和在故障发生时来实现可靠性
- 他们为存储和处理超大规模数据提供所需的扩展能力
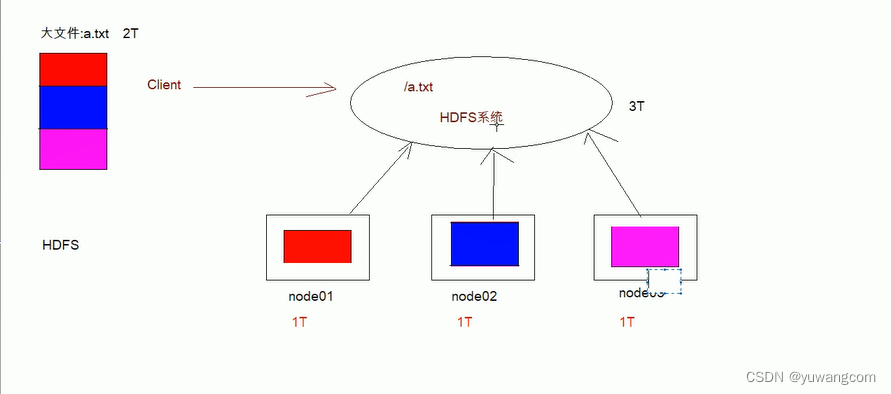
三、架构:
1、namenode是一个中心服务器,单一节点,负责管理文件系统的名字空间(NameSpace)以及客户端对文件的访问
2、文件操作,NameNode是负责文件元数据的操作,DataNode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过NameNode,只询问它跟哪个DataNode联系
3、副本存放在哪些DataNode上由NameNode来控制,根据全局情况做出块放置决定,读取文件时NameNode尽量让用户读取最近的副本,降低读取网络开销和读取延迟
4、NameNode全权管理数据库的复制,他周期性的从集群中的每个DataNode接受心跳信和块状态报告,块状态报告包括一个该DataNode上所有的数据列表
1.关系
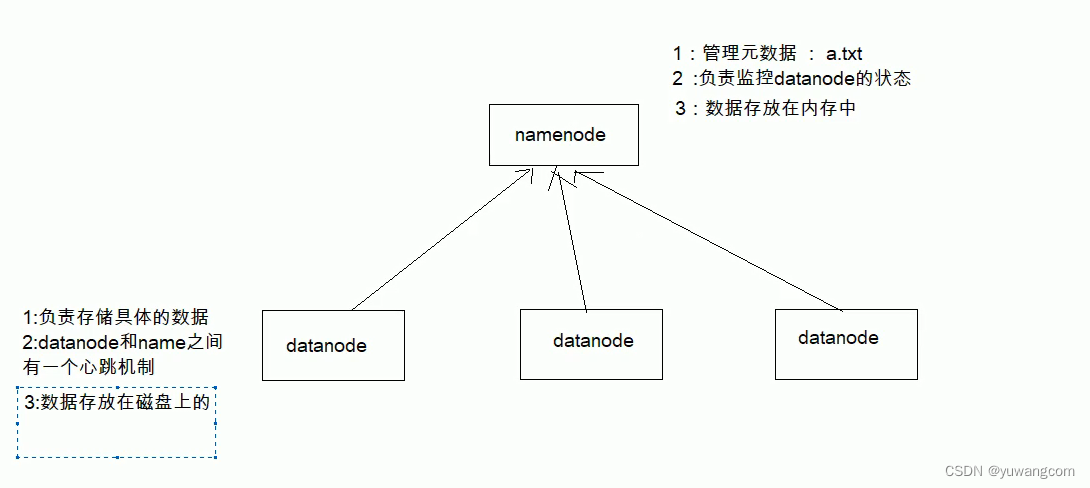
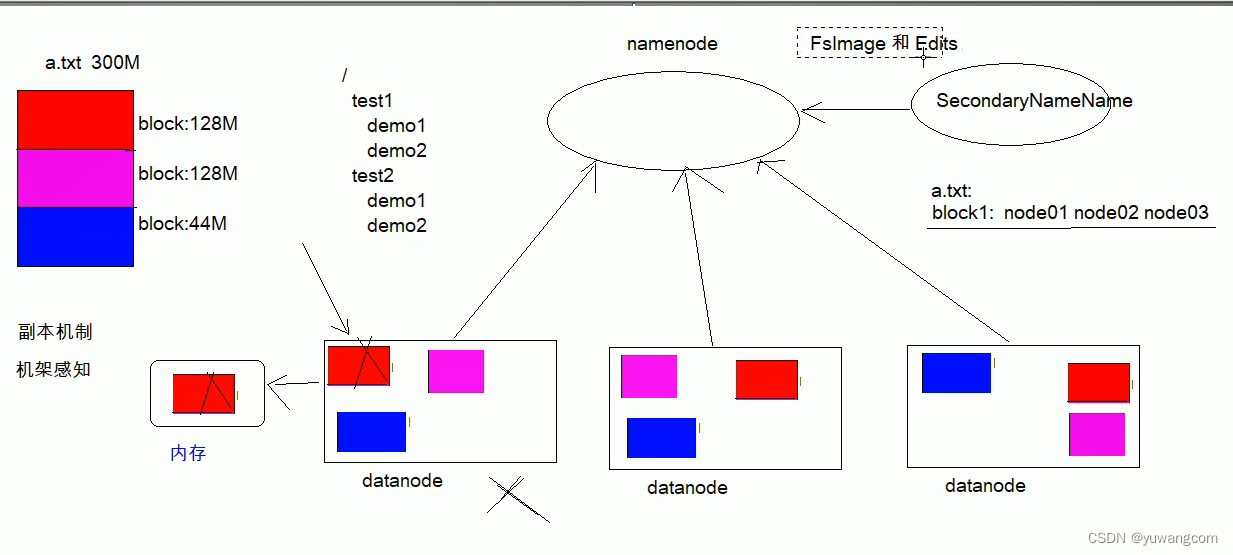
HDFS文件副本和Block块存储
<property>
<name>dfs.block.size</name>
<value>块大小 以字节为单位</value>
</property>
2. 引入块机制的好处
- 一个文件可能大于集群中任意的一个磁盘
- 使用块抽象而不是文件可以简化存储子系统
- 块非常适合用于数据备份进而提供数据容错能力和可用性
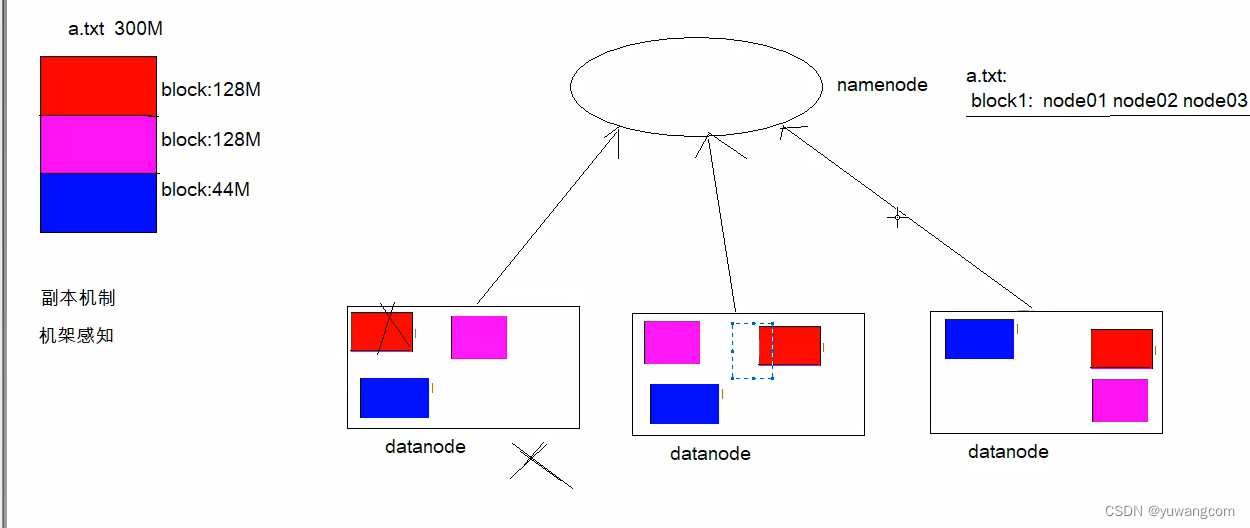
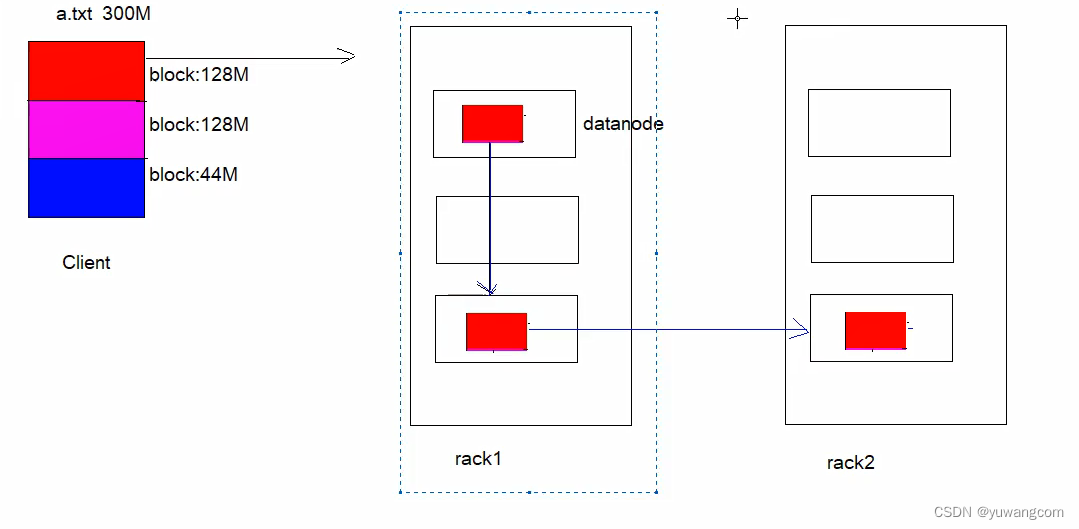
3.机架感知
4.块缓存和访问权限
用户或应用通过在缓存池中增加一个 Cache Directive 来告诉 NameNode 需要缓存哪些文件及存多久. 缓存池(Cache Pool) 是一个拥有管理缓存权限和资源使用的管理性分组.
5.SecondaryNamenode工作机制
当 Hadoop 的集群当中, 只有一个 NameNode 的时候, 所有的元数据信息都保存在了 FsImage 与 Eidts 文件当中, 这两个文件就记录了所有的数据的元数据信息, 元数据信息的保存目录配置在了 hdfs-site.xml 当中
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/servers/hadoop-3.1.1/datas/namenode/namenodedatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/servers/hadoop-3.1.1/datas/dfs/nn/edits</value>
</property>
触发条件:
- 时间因素 1小时
- 文件大小因素:64m
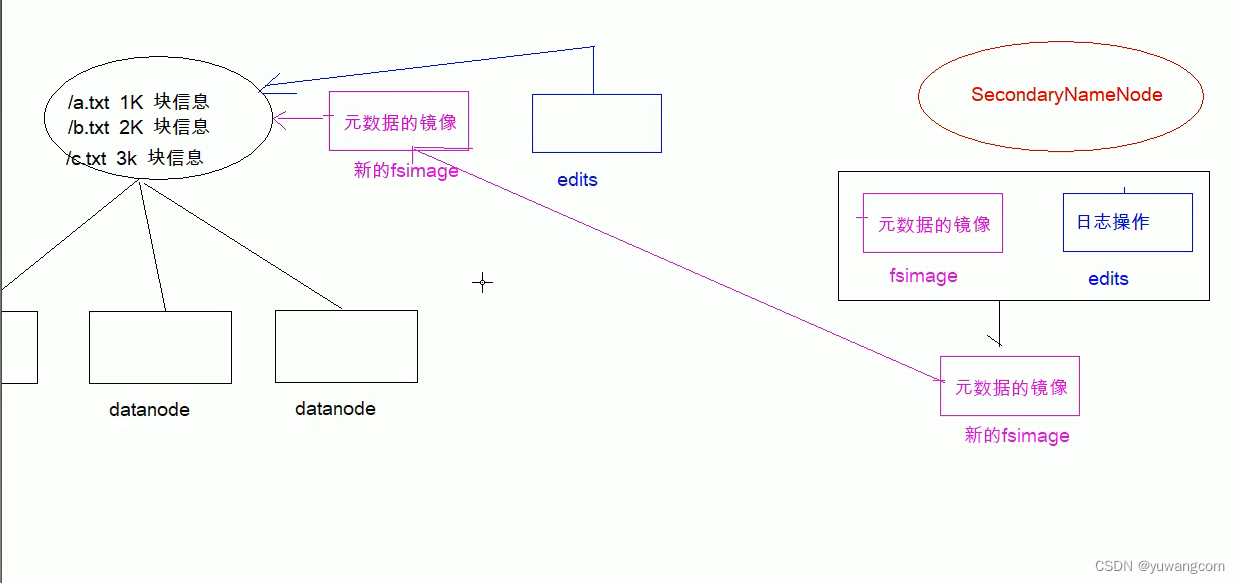
6.FsImage 和 Edits 详解
- edits
- edits 存放了客户端最近一段时间的操作日志
- 客户端对 HDFS 进行写文件时会首先被记录在 edits 文件中
- edits 修改时元数据也会更新
- 每次 HDFS 更新时 edits 先更新后客户端才会看到最新信息
- fsimage
- NameNode 中关于元数据的镜像, 一般称为检查点, fsimage 存放了一份比较完整的元数据信息
- 因为 fsimage 是 NameNode 的完整的镜像, 如果每次都加载到内存生成树状拓扑结构,这是非常耗内存和CPU, 所以一般开3. 始时对 NameNode 的操作都放在 edits 中
- fsimage 内容包含了 NameNode 管理下的所有 DataNode 文件及文件 block 及 block 所在的 DataNode 的元数据信息.
- 随着 edits 内容增大, 就需要在一定时间点和 fsimage 合并
7.配置SecondaryNameNode
SecondaryNameNode 在 conf/masters 中指定
在 masters 指定的机器上, 修改 hdfs-site.xml
<property>
<name>dfs.http.address</name>
<value>host:50070</value>
</property>
#修改 core-site.xml, 这一步不做配置保持默认也可以
<!-- 多久记录一次 HDFS 镜像, 默认 1小时 -->
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
</property>
#<!-- 一次记录多大, 默认 64M -->
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
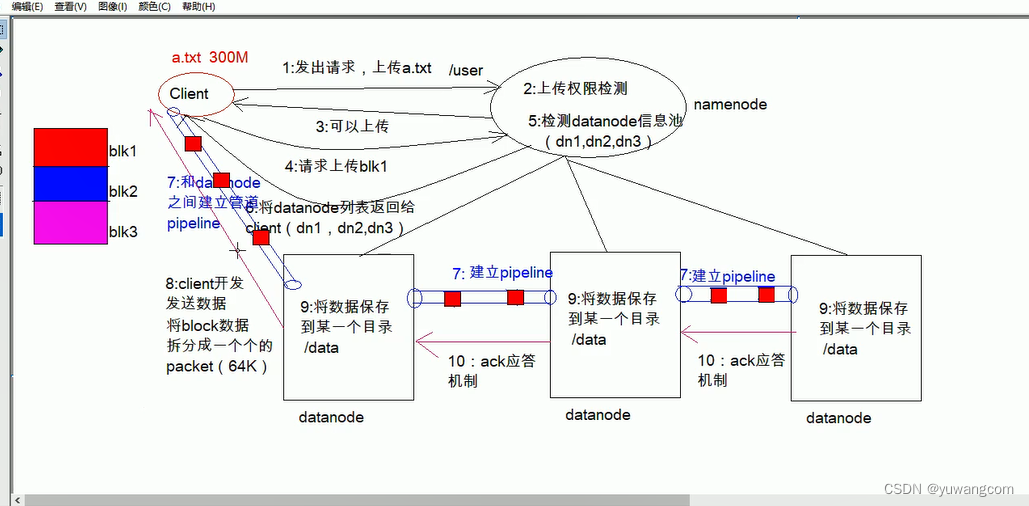
HDFS文件写入过程
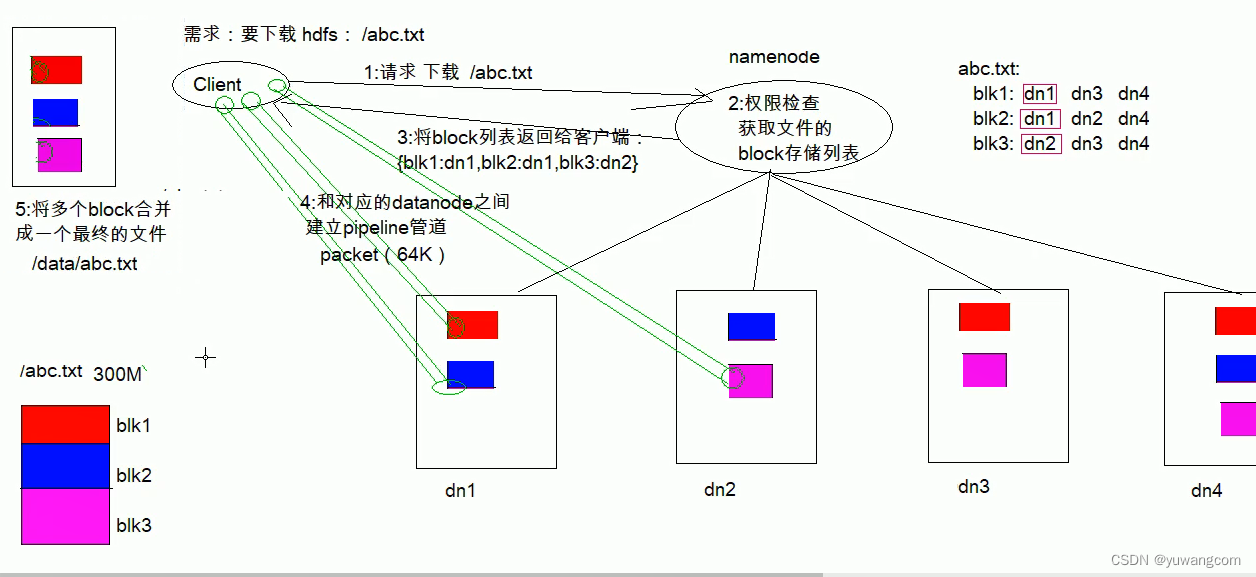
HDFS数据的读取过程















 960
960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









