







文章目录
前言

大规模、多视角的意见总结,具有多样化的评论子集(2310)
0、论文摘要
意见总结有望消化更大的评论集并提供不同角度的总结。然而,现有的大多数解决方案由于缺乏信息选择的设计,缺乏从多个角度概括广泛的评论和提供意见总结。
为此,我们提出了SUBSUMM,一种用于大规模多视角意见摘要的监督摘要框架。
SUBSUMM 由回顾抽样策略集和两阶段训练方案组成。抽样策略考虑了情感导向和对比信息价值,可以选择不同视角和质量水平的评论子集。随后,鼓励总结者依次从次优和最优子集中学习,以便利用大量输入。
AmaSum 和 Rotten Tomatoes 数据集上的实验结果表明,SUBSUMM 擅长从数百条输入评论中生成优点、缺点和结论摘要。
此外,我们的深入分析证明,复习子集的高级选择和两阶段训练方案对于提高摘要性能至关重要。
一、Introduction
1.1目标问题
大量的在线资源对自动信息挖掘技术很有吸引力。意见总结作为一项从与实体相关的一组文件(例如评论、帖子和讨论)中概括观点并以文本形式呈现的任务,受到了相当多的关注。用户意见的总结对于舆情研究、营销分析和决策有很大的优势(Im et al., 2021)。在避免繁琐的逐文档浏览的同时,与单一情绪评级相比,它还提供了更重要的细节(Wang 和 Wan,2021)。
1.2相关的尝试
由于在线评论数量和用户需求的不断增长,意见摘要预计将(1)处理更大的文档集和(2)从不同的角度提供摘要。
一种主流解决方案使用均值函数(Chu and Liu,2019;Brazinskas et al.,2020b;Li et al.,2020)、凸组合(Iso et al.,2021)对句子或文档表示的跨文档关系进行建模、图(Erkan 和 Radev,2004;Ganesan 等人,2010)以及其他层次结构(Isonuma 等人,2021;Amplayo 等人,2021a)。事实证明,这些方法可以通过适度数量的评论(通常在 10 条以内)取得显着的结果(Shapira 和 Levy,2020);然而,当评论数量进一步增加时,它们的表现并不令人满意,因为它们注重融合而不是信息的选择。另一个解决方案将远程语言模型(Beltagy 等人,2020;Zaheer 等人,2020;Mao 等人,2022;Pang 等人,2023)和大型语言模型(法学硕士;OpenAI,2023)的评论串联起来),它将多文档摘要转换为单文档摘要(Brazinskas et al., 2020a;Oved and Levy, 2021;Ke et al., 2022;Brazinskas et al., 2022;Bhaskar et al., 2023)。尽管法学硕士带来了好处,但这些方法很难处理过长的综合评论,也缺少从中进行选择的步骤。布拉津斯卡斯等人。 (2021)首先提出选择较小的输入评论子集,并提供结论、优点和缺点总结,但不同观点的差异化处理并未反映在他们的方法中。受限于数据,针对大规模、多视角的意见总结的作品很少。
1.3本文贡献
为了解决这些问题,我们提出了 SUBSUMM,一种用于大规模、多视角意见摘要的监督摘要框架。 SUBSUMM 包括审查抽样策略集和两阶段训练方案。这通过情感分析和对比信息评估制定评论抽样策略。通过不同的策略,可以选择不同角度和质量水平的评论子集。然后,两阶段训练方法使摘要模型能够依次从次优和最优评论子集中学习,以充分利用模型容量内的输入评论。在训练第二阶段,引入对比损失项以进一步提高摘要器的性能。
通过与 SUBSUMM 结合,在我们的实验中,预训练语言模型(PLM)在 AmaSum 和烂番茄数据集上的零样本设置下优于以前最先进的模型和法学硕士,这证明了该提案的优越性。进一步的分析也证明了SUBSUMM中两个模块的有效性。
总之,我们的贡献如下:
我们提出了一个大规模意见总结框架1,以解决总结大型评论集并通过选择有价值的评论子集从不同角度提供意见的挑战。
• 我们提出
(1)基于情感分析和对比信息评估的回顾抽样策略集,
以及(2)促进海量输入消化和吸收的两阶段培训方案。
• 我们通过对来自不同领域的两个意见总结数据集进行充分的实验和深入分析,证实了所提出的意见总结框架SUBSUMM的有效性
二.相关工作
意见总结
由于获得大型意见语料库的高质量注释的成本很高(Ge et al., 2023),因此大多数意见总结工作都是无监督的,总结的评论数量有限。在抽象方法中,基于 VAE 和基于合成数据集的模型具有优势。基于 VAE 的模型(Chu 和 Liu,2019;Brazinskas 等人,2020b;Li 等人,2020;Iso 等人,
2021 年; Isonuma 等人,2021)通过聚合评论的潜在表示进行总结。 COOP(Iso et al., 2021)考虑输入评论表示的凸组合。这些方法在评论较少的情况下效果很好,但在处理大量评论时,它们的性能会下降。
基于合成数据集的方法(Amplayo 和 Lapata,2020;Brazinskas 等人,2020a;Oved 和 Levy,2021;Wang 和 Wan,2021;Amplayo 等人,2021b;Ke 等人,2022;Brazinskas 等人., 2022)通过从原始数据构建评论-摘要对,将无监督任务转变为监督任务。 PASS(Oved 和 Levy,2021)对输入评论应用系统扰动以获取更多候选者摘要,并训练分类器对候选者进行排名。 CONSISTSUM(Ke et al., 2022)从方面、情感和语义方面衡量评论之间的距离,以创建高度相关的评论-摘要对。 ADASUM (Brazinskas et al., 2022) 首先使用合成数据集微调 PLM,然后以少量方式执行微调。这些方法充分体现了充分利用原文的思想。
受益于意见总结注释数据的增长,有一些关于监督方法的新兴研究。布拉津斯卡斯等人。 (2021)提供了一个大规模的意见总结数据集,支持监督训练。他们将任务制定为共同学习选择信息丰富的评论并总结意见,他们的解决方案 SELSUM 基于强化学习(REINFORCE;Williams,1992)。为了避免强化学习带来的挑战,我们在这项工作中解耦了选择和总结的过程。
对比学习
自动文摘中的对比学习(Cao and Wang,2021;Xu et al.,2021;Sun and Li,2021;Liu and Liu,2021;Liu et al.,2022)也给了我们很多启发。 CLIFF(Cao 和 Wang,2021)使用自动生成的错误摘要创建负样本。 SIMCLS(Liu 和 Liu,2021)通过对比学习训练一个额外的模型来评估和排名候选摘要。 BRIO(Liu et al., 2022)引入对比学习来为模型分配双重角色,从而缓解推理性能下降。在这项工作中,我们探索多文档摘要而不是单文档摘要的对比学习数据化,而PLM则针对信息评估进行了微调。
三.本文方法
我们引入了 SUBSUMM,一个用于大规模、多视角意见总结的监督框架,如图 1 所示。SUBSUMM 由关于情感取向和信息价值的评论抽样策略集组成,如第 2 节中所述。 3.1;以及一个两阶段的训练方案,其中额外执行与候选摘要的对比学习,请参见第 2 节。 3.2.给定实体集和对应的样本集,对于每个样本{R1:N,S},意见摘要的目标是学习一个函数f,该函数f以评论集作为输入,并输出尽可能接近参考的摘要:
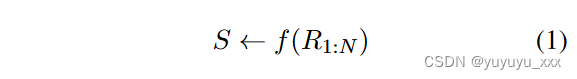
其中R1:N是原始评论集,S是参考意见摘要。本文主要讨论R1:N太大而大多数语言模型无法处理的情况。对于评论集 R1:N ,令 R1:K 为评论子集,其中 K ≪ N。
3.1 审查抽样策略集
情绪分析
我们利用情感分析来粗略地过滤评论。假设具有相似情感取向的评论比具有相反情感取向的评论在内容上发生冲突的可能性更小。另一方面,可以通过调整不同情感的输入评论的比例来控制摘要的情感倾向;这样就形成了多个角度。我们将情感分析制定为文本分类任务。 R1:N 中评论的情感标签计算如下:
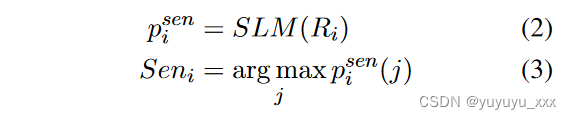
其中 SLM (·) 是具有线性分类头的 PLM,psen i 指评论 Ri 的情感类别的概率分布。将概率最高的类别作为情感标签Seni。我们使用数据集中每个评论的评分作为情感标签,并应用负对数似然损失。情绪分布 psen i 。经过微调后,可以获得所有评论的情感标签。
对比信息估值
信息评估的粒度比情绪分析更细。直观上,一旦选择评论子集进行摘要,生成的内容越接近参考,子集中的信息可能越有价值。
给定参考摘要,输入评论的信息价值与其与参考文献的相似性相关; ROUGE(Lin,2004)是估计这种相似性的合适指标。因此我们拟合评论的 ROUGE 分数
Ri = {r(1) i , …, r(|Ri|) i } 通过对评论与整个评论集之间的相关性进行建模:
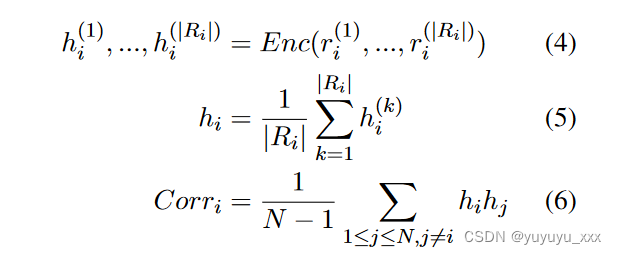
其中 Enc(·) 是一个 Transformer (Vaswani et al., 2017) 编码器,h(k) i 表示 token r(k) i 的最后一个隐藏状态。评论表示 hi 是通过对 Ri 中标记的最后隐藏状态进行平均来计算的。 Corri 是 Ri 和评论集 R1:N 之间的相关性得分。我们参考无监督意见总结中的留一设置,通过 hi 的点积和其他的均值表示来计算 Corri。考虑到原始评论集的数量,直接拟合 ROUGE 分数的分布或采用列表损失是不可行的。因此,我们采用对比边际损失:
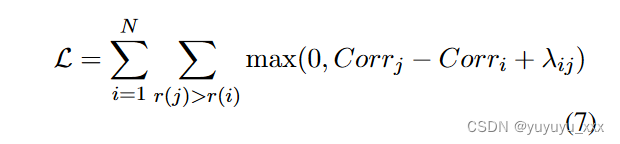
其中,r(i) 表示 Ri 按 ROUGE(Ri, S) 降序排序时的排名,λij = λ(r(j) − r(i)) 是随排名变化的余量,定义如下等人。 (2020);刘和刘(2021);刘等人。 (2022)。成对损失允许模型学习大型评论集的 ROUGE 排名。经过微调,我们可以得到所有评论的估计信息值。
多层次审查抽样策略
在情感分析和对比信息评估的支持下,可以形成多种评论抽样策略,从 R1:N 中选择 R1:K。我们发现用单个最优子集完成任务并不理想,这将在第 2 节中解释。 4.3.为了解决这个问题,我们引入随机因素来制定多个质量水平的抽样策略。采样策略集由以下三种策略组成:
-
随机采样:从原始评论集 R1:N 中随机采样 K 个评论作为子集 R1:K 。
-
情感随机抽样:首先,根据情感标签将所有评论分为正面和负面类型。其次,R1:K中各类型的评论数量由参考文献摘要的类型决定:
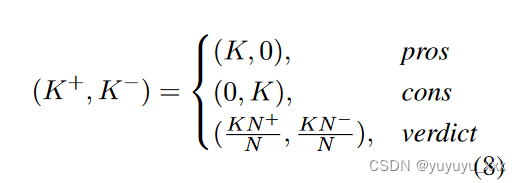
其中 (K+, K−), (N +, N −) 分别代表 R1:K , R1:N 中正面和负面评论的数量; K++K− = K, N ++N − = N 。最后,分别从正面和负面类型中随机抽取 K+、K− 评论作为 R1:K 。 -
情绪信息排名 首先,同样计算(K+,K−)。其次,将评论按估计信息值Corri降序排列,分别分为两种类型。最后,获取 R1:K 的 top-K+ 正面评论和 top-K− 负面评论。
3.2 大规模意见总结的两阶段训练
SUBSUMM 体现了一个两阶段的训练方案,鼓励总结者依次从次优和最优评论子集中学习。在第一阶段,我们选择次优策略,即情感随机采样,在每个训练时期对评论子集 ̇ R1:K 重新采样,并使用标准最大似然估计 (MLE) 训练模型:
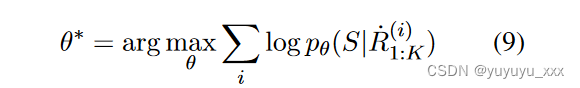
其中θ表示抽象模型的参数,pθ表示参数推导的概率。交叉熵损失在长度为 l 的参考序列上定义为:
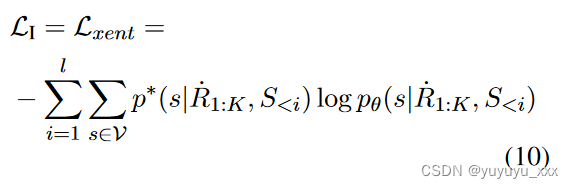
其中 s 可以是词汇表 V 中的任何标记,p* 指的是 one-hot 分布。 S<i 代表预定义的起始标记和参考摘要的前 i−1 个标记。然而,标准 MLE 很容易出现暴露偏差,因为它严重依赖于真实序列(Zhang et al., 2019)。同时,无论采用哪种策略,抽样的评论都只是原始评论集中的一部分,其中的信息可以进一步利用。
在第二阶段,我们从训练期间为候选摘要分配概率质量的实践中得到启发(Liu et al., 2022)。从理论上讲,将概率质量分配给摘要意味着摘要有机会通过反向传播将知识传递给模型。因此,概率质量分配的范围本质上是模型学习的范围,更好的候选摘要应该竞争更多的概率质量。我们计划通过候选人摘要重用原始评论集。
首先,我们稍微修改最优策略(即情感信息排名),因为需要一些扰动才能获得对比学习的各种候选摘要:
情绪信息排名(修改):计算式中的 (K+, K−) 后: 8、以每个评论的估计信息值Corri作为权重,分别从正面和负面类型中抽取K+、K−评论。
接下来,重复执行修改后的最优策略,得到 M 个评论子集,其中 M 个候选摘要 ˆ S1, ˆ S2, …, ˆ SM 由第一阶段的模型生成。原始最优策略产生的评论子集,用 ̈ R1:K 表示,将是训练输入。我们再次使用参考摘要 S 计算 ̈ R1:K 中评论的 ROUGE 分数,以得出排名并应用类似于等式 1 的对比损失项。 7:
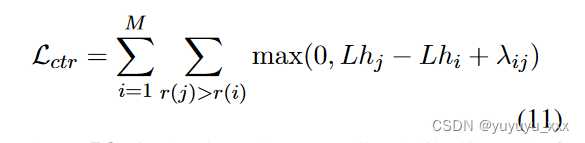
其中 Lhi 是候选摘要 ˆ Si 的长度归一化似然,其定义如下 Liu 等人。 (2022):
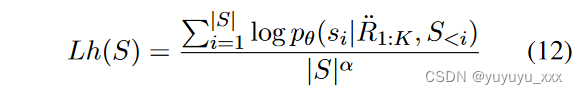
这里 α 是长度惩罚超参数。该术语强制模型将更多的概率质量分配给更好的候选摘要。
最后,为了保持预训练模型的生成能力,我们遵循 Edunov 等人的方法。 (2018) 使用多任务损失:
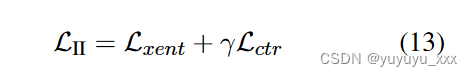
其中 γ 是对比损失项的权重。通过将候选摘要纳入训练,第二阶段提高了原始评论集的利用率并缓解了暴露偏差问题;考虑到添加具有更高质量的评论子集和对比损失项,它充当第一阶段的补充。
在推理过程中,给定评论集 R1:N ,S UBSUMM 使用第 2 节中经过微调的 PLM 来预测每个评论的情感标签和信息价值。 3.1,然后根据情感信息排序策略选择最佳评论子集R1:K,并使用第二阶段的摘要模型对子集进行摘要。
四 实验效果
4.1数据集
我们选择两个具有大量评论集的意见总结数据集作为我们的测试平台。统计数据如附录 A 所示。AmaSum2(Brazinskas 等人,2021)是一个产品评论数据集,其中每个样本都包含由专业评论者撰写的大量评论和参考摘要。与其他数据集不同,AmaSum提供了三个角度的参考摘要,即verdict,相当于一般意见摘要;优点和缺点,总结了最重要的积极和消极细节。如表 6 所示,AMASUM 中的平均评论数为 4.2k,对于大多数总结者来说,综合评论太长而无法总结。我们参考 SELSUM 中的预处理,但将数据集分为三个具有不同目标的分区。烂番茄3(RT;Wang and Ling,2016)是一个大规模的电影评论数据集。对于每部电影,编辑都会构建一句话评论家共识,总结专业评论家的意见,作为参考摘要。我们关注 Amplayo 等人。 (2021b) 预处理数据集;在我们的实验中,RT 中的数据和 AmaSum 的判决分区是同等对待的。
4.2 对比模型
关于基线,我们为两个数据集选择了一系列竞争模型。
在 AmaSum 数据集上,基线包括(1)无监督提取模型 LEXRANK(Erkan 和 Radev,2004)和 EXTSUM(Brazinskas 等人,2021); (2) 无监督抽象模型 MEANSUM (Chu and Liu, 2019) 和 COPYCAT (Brazinskas et al., 2020b); (3) 有监督抽象模型SELSUM、L ONGFORMER (Beltagy et al., 2020) 和 BRIO; (4) 与 LLM 相关的零样本解决方案,包括 GPT-3.5-turbo (CHATGPT) 以及基于 QFSumm (Ahuja et al., 2022) 和 GPT-3 (Brown) 的 QG (Bhaskar et al., 2023)等人,2020)。
在 RT 数据集上,额外的基线是 (1) 无监督提取模型 W2VCENT (Rossiello et al., 2017)、SNCENT (Amplayo and Lapata, 2020) 和 BERTCENT (Amplayo et al., 2021b); (2) 无监督抽象模型 OPINOSIS (Ganesan et al., 2010) 和 DENOISESUM (Amplayo and Lapata, 2020); (3) 弱监督模型 PLANSUM (Amplayo et al., 2021b)。我们将 PLANSUM 归类为弱监督摘要器,因为它使用评论文本以外的附加信息。附录 B 详细介绍了基线。
4.3实施细节
我们使用 RoBERTa-base (Liu et al., 2019) 进行情感分析,使用 BART-base (Lewis et al., 2020) 编码器进行对比信息评估,并使用 BART-base作为我们的摘要器及其变体的支柱。在所有评论抽样策略中,我们为每个子集选择了 K = 10 条评论,这在附录 D 中进行了解释。以下所有实验均在 2 个 Geforce RTX 3090 GPU 上进行。有关超参数和更多详细信息,请参阅附录 C。
4.4评估指标
4.5 实验结果
自动评估
我们使用 ROUGE-1/2/L 作为评估指标并报告 F-1 分数。对于 AmaSum,我们分别评估了优点、缺点和结论。如表 1 和表 2 所示,SUBSUMM 在两个数据集上均显着优于其他方法。具体来说,有两个观察结果:(1)SUBSUMM 擅长生成具有明显情感倾向的摘要,即优点和缺点。我们注意到,AmaSum 中的三个目标受到所有基线的同等对待,表明缺乏对视角之间差异的探索。 SUBSUMM 仅对正面/负面评论进行采样,以进行优缺点总结。如图2所示,赞成和反对的评论样本分布在语义空间的不同区域,而判决的评论均匀地分布在它们之间。它不仅减少了不一致,还为输入添加了有价值的信息,因为正面评论总是指出产品的更多优点,反之亦然。 (2)监督方法得分普遍高于LLM相关方法,而SUBSUMM比同类监督系统有优势。尽管 LLM 在文本生成方面具有很强的多功能性,但在带注释的数据上微调标准 PLM 对于意见总结来说似乎并非易事。与其他监督方法相比,SUBSUMM 在信息评估和训练阶段 II 中都通过对比学习重用了参考摘要,从而综合利用了标注。特别是,LONGFORMER的稀疏注意力机制起到了隐式选择的作用,而SUBSUMM的评论抽样策略考虑了情感倾向和信息价值,更加复杂和任务特定。
人工评价
作为自动评估的补充,我们使用附录 E 中详述的最佳-最差缩放(BWS;Louviere 等人,2015)进行了用户研究。四个评估的摘要是 GOLD(参考)摘要和由 SELSUM、BRIO 生成的摘要,和 SUBSUMM。这三个标准是信息性、连贯性和非冗余性。
我们的模型的实用价值。关于信息量,SUBSUMM 的摘要显示的信息与 GOLD 摘要相当,甚至更多。在连贯性方面,S UBSUMM 以正确的语法和直白的表达给用户带来最好的阅读体验。在非冗余方面,S UBSUMM 没有给出最简洁的摘要,但考虑到前两个标准,冗余仍然可以接受。
我们通过 SUBSUMM 和 CHATGPT 之间的 50 次头对头测试进一步将我们的模型与 LLM 进行比较。测试用例是从两个数据集中随机抽取的(AmaSum 测试集中每个分区的 15 个样本和 RT 测试集中的 5 个样本),并且要求注释者在没有参考摘要的情况下进行成对比较。结果如表 4 所示。看来用户更喜欢 SUBSUMM 生成的摘要。 CHATGPT 的一个明显问题是,当输入过长时,它无法在几次调用内控制输出长度。因此,大多数生成的摘要要么过长,要么在最大长度参数固定的情况下突然被截断。此外,尽管 CHATGPT 能够生成流畅的文本,但它比我们的模型遭受更严重的幻觉,这可能会影响其 ROUGE 分数。表 10 是一些支持案例。
抽样策略比较
如前所述,审查抽样策略集中的三种策略的质量将依次提升。为了确认这一点,我们将训练阶段 I 的摘要器与表 5 上半部分的不同采样策略进行比较。RAND、S ENTI-RAND 和 SENTI-INFO 在训练中应用随机采样、情感随机采样和情感信息排名分别进行推理; SENTI-RAND-INFO 使用情感随机采样进行训练,但根据情感信息排名生成的评论子集进行推断。
通过比较RAND和SENTI-RAND可以看出,借助情感分析,采样的评论子集对于具有情感倾向的摘要显得更有用。从SENTI-RAND到SENTI-INFO没有明显的改进,因此我们添加SENTI-RAND-INFO来查明原因。 SENTI-RAND-INFO 和 SENTIRAND 仅在测试输入上有所不同,而前者以明显优势获胜,这表明 SentimentInformation Ranking 产生了更好的评论子集。 SENTI-RAND-INFO 与 SENTI-INFO 共享相同的测试输入,但会产生更高的 ROUGE 分数,可能是因为随机因子防止了潜在的过度拟合问题。它还暗示使用不同的评论子集可能会提高模型的性能。
深入了解两阶段培训计划
我们通过消融研究调查了两阶段训练计划的收益。表 5 底部块中的变体与 SUBSUMM 共享相同的测试输入。我们的实验证明,第一阶段和第二阶段对模型性能都很重要,而后者发挥的作用更大。我们假设这两个阶段是互补的:第一阶段的标准 MLE 训练充当特定于任务的初始化,第二阶段的多任务学习将更多知识传递给模型,从而减轻暴露偏差问题。此外,我们通过随机采样替换两个训练阶段中的次优和最优策略,探讨了两阶段训练方案如何对摘要质量做出贡献。它会导致可观察到的性能下降,但比直接删除阶段 I 或 II 时的下降程度要轻。可以推断,除了互补的训练目标和额外的训练步骤之外,评论子集的合理选择也有利于模型训练。
在本文中,我们提出了一种用于大规模、多视角意见摘要的监督摘要框架,SUBSUMM。 SUBSUMM 支持基于一组多个质量级别的审查抽样策略的两阶段训练方案。我们的模型超越了 AmaSum 和 RT 上最先进的模型和 LLM 相关系统,体现了其在处理大量评论和展示各种观点方面的优越性。分析实验验证了SUBSUMM的两个组件可以帮助摘要器获得更好的结果。未来,我们计划(1)探索更多评论抽样策略以充分学习方面信息,(2)将所提出的框架与LLM结合起来,并将其推广到其他大规模多输入任务。
五 总结
在本文中,我们提出了一种用于大规模、多视角意见摘要的监督摘要框架,SUBSUMM。 SUBSUMM 支持基于一组多个质量级别的审查抽样策略的两阶段训练方案。我们的模型超越了 AmaSum 和 RT 上最先进的模型和 LLM 相关系统,体现了其在处理大量评论和展示各种观点方面的优越性。分析实验验证了SUBSUMM的两个组件可以帮助摘要器获得更好的结果。
未来,我们计划(1)探索更多评论抽样策略以充分学习方面信息,(2)将所提出的框架与LLM结合起来,并将其推广到其他大规模多输入任务。
局限性
SUBSUMM 也有一些限制。在表 1 的判定分区中,我们模型的 ROUGE-2 F1score 并不超过 SELSUM;我们模型的 ROUGE-L F1 分数略低于 CHATGPT。首先,由于 ROUGE-2 反映了 2-gram 召回率,我们怀疑这是由于 SUBSUMM 中缺乏对方面学习的明确设计,这导致模型比 SELSUM 错过更多的 2-gram 方面项(我们注意到 SELSUM 强调方面学习)。其次,ROUGE-L是根据最长公共子序列计算的,这与生成的流畅性有关。我们发现 SUBSUMM 的摘要中存在一些错误,例如重复和不完整的第一个单词。与具有广泛参数的LLM相比,我们的建议在语言建模方面仍有改进的空间。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









