







提示:本人学识有限,如果错误,请及时指出,会及时纠正问题,谢谢~!
姿态生成之基础网络系列
- 第一章 : Pix2Pix论文及核心代码走读
- 第二章 : Pix2PixHD文论走读
简介
论文:High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
论文链接:https://arxiv.org/abs/1711.11585
代码链接:https://github.com/NVIDIA/pix2pixHD
姿态生成的第二篇博客,也是姿态生成基础架构的介绍,后续一些姿态生成任务基于Pix2PixHD网络架构;Pix2PixHD是基于Pix2Pix (参考博客: Pix2Pix论文及核心代码走读) 上面做的优化,主要解决(2017前)cGAN生成器的图片分辨率不够的问题,本篇博客主要介绍Pix2PixHD包括: 结果展示,Pix2PixHD介绍,基于pix2pix的五个优化点, 评价指标;
结果展示
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
Pix2PixHD 介绍
图像到图像的翻译是GAN的一个重要应用,表示基于输入图像生成指定的输出图像的过程,比如有监督的pix2pix (参考博客: Pix2Pix论文及核心代码走读) ,无监督的CycleGAN等。而基于语义分割图生成对应图像可以看做是图像到图像的翻译中的一个特例,如Figure1(a)所示,其中左下角是语义分割图,模型基于这张图生成(a)这张看起来和实际图像差别不大的合成图。这个研究方向主要有2个发展趋势:
- 生成的图像要尽可能接近真实图像
- 生成图像的分辨率越来越大,也就是越来越往高清大图发展
Pix2PixHD(CVPR2017)在这两个方面都有不错的贡献。Pix2pixHD是在pix2pix算法基础上做了优化,pix2pix合成的图像的分辨率在256 × 256左右,作者曾经尝试直接用pix2pix算法生成高分辨率图像,但是发现训练过程不稳定,效果也不好,因此才不断优化得到pix2pixHD。
Pix2PixHD (英伟达开源cGANs) 可以较好的生成2048x1024 分辨率的图像。 算法可以用于将语义标签贴图转换为逼真的图像或者从人脸标签贴图合成肖像。Pix2PixHD的训练依然是有监督的,也就是需要pair对的数据。pix2pixHD核心贡献:高分辨率图像的生成, 图片的语义编辑。

五个优化点
整体来看,基于pix2pix网络, Pix2PixHD在生成高质量的高清大图方面做了5部分优化
- 生成器从U-Net升级为多级生成器(coarse-to-fine generator)
- 判别器从patch GAN升级为多尺度判别器(multi-scale discriminator)
- 优化目标上增加了基于判别器特征的匹配损失 和内容损失
- 增加实例级别的信息
- 语义编辑: 生成图片的多样性和可编辑性
生成器的优化
基于Pix2Pix的生成器(G)优化,一个生成器变为2个生成器分别为G1和G2, G1为全局生成器,G2为局部增强生成器;G={G1,G2};

Pix2PixHD的多级生成器 如Figure2所示,主要包含G1和G2两部分,二者在结构上是类似的。G1表示全局生成网络 (global generator network),输入和输出大小是1024 × 512,G2表示局部增强生成器(local enhancer network,输入和输出大小是2048 × 1024。整体上可以看做是在一个常规的生成器(G2) 中嵌入了另一个生成器(G1),G1最后输出的特征和G2中间输出的特征做特征融合作为G2后半部分的输入。引入G1主要目的是为了学到的全局结构特征。如果想要生成图片分辨率为4094X2048,生成器的组合G={G1, G2, G3};
Coarse-to-Fine的生成器
-
基础结构
-
G1(全局生成器)
- 有更大的感受野,保证图片生成的全局一致性
- 三部分
- a convolution front-end G 1 ( F ) G_1^{(F)} G1(F)
- a set of residual blocks G 1 ( R ) G_1^{(R)} G1(R)
- a transposed convolutional back-end G 1 ( B ) G_1^{(B)} G1(B)
- 输入语义图,大小为1024X512,顺序通过上述的3部分,输出生成图片,像素大小为 1024X512
-
G2(局部增强生成器)
- 有较小的感受野,保证图片细节方面的合成
- 三部分
- a convolution front-end G 2 ( F ) G_2^{(F)} G2(F)
- a set of residual blocks G 2 ( R ) G_2^{(R)} G2(R)
- a transposed convolutional back-end G 2 ( B ) G_2^{(B)} G2(B)
- 输入语义图,大小为2048X1024, 先输入 G 2 ( F ) G_2^{(F)} G2(F),输出的特征图和全局输出的特征图做 element-wise sum,最终输入 G 2 ( R ) G_2^{(R)} G2(R) 和 G 2 ( B ) G_2^{(B)} G2(B), 最终输出生成图片,像素大小为 2048X1024
-
-
训练方式
- 先训练分辨率较小的G1生成器, 在一起训练G1和G2生成器
- 好处: 对于图片合成任务,充分的考虑了图片全局和局部信息
-
推理流程:
- 图片先经过一个生成器 G2 的卷积层, 对图片进行2倍下采样
- 使用另一个生成器 G1 生成低分辨率的图,将得到的结果和刚刚下采样得到的图进行element-wise的相加
- 输出到 G2 的后续网络生成高分辨率的图片
-
优点
- 低分辨率的生成器会学习到全局的连续性 (越粗糙的尺度感受野越大,越重视全局一致性),高分辨率的生成器会学习到局部的精细特征,因此生成的图片会兼顾局部特征和全局特征的真实性。如果仅使用高分辨率的图生成的话,精细的局部特征可能比较真实, 但是全局的特征就不那么真实。
判别器的优化
要在高分辨率下区分真实的与合成的图像,要求判别器有很大的感受野,这需要更深的网络或者更大的卷积核才能实现,而这两种选择都会增加网络容量从而判别器网络出现两个问题: 1. 更容易产生过拟合问题,2. 训练所需的存储空间也会增大。
Pix2PixHD的多尺度判别器设计;
- 为解决上述判别器的问题, 作者构建3个生成器 D = {D1,D2, D3 } 来处理不同的分辨率比如2014 × 1024, 1024 × 512,512 × 256;三个判别器具有相同的网络结构,只不过处理的输入尺寸不一样和每一个判别器需要单独训练。这三个判别器的设计希望
- 低分辨率的判别器具有更大的感受野,可以保证生成的图片全局一致性
- 高分辨率的判别器具有较小的感受野,促进图像细节方面的合成
- 更加容易训练 Coarse-to-fine 的生成器
- 已于扩展,把低分辨率的模型改为高分辨模型,只需要额外的添加高分辨率的判别器,而不需要从头训练
- 多个判别式优化公式如下:

损失函数
采用3个损失函数
-
GAN loss:和pix2pix一样,使用PatchGAN。
-
Feature matching loss:将生成的样本和Ground truth分别送入判别器提取特征,然后对特征做Element-wise loss
-
感知损失函数:将生成的样本和Ground truth分别送入VGG16提取特征,然后对特征做Element-wise loss
-
Feature matching loss
- 增加了基于判别器特征的匹配损失函数, 这种损失稳定了训练,因为生成器必须在多个尺度上生成自然的图片。
- 具体方式:
- 从判别器的多个层中提取特征,并学习从真实图像和合成图像中匹配这些中间表示。
- 例如: 判别器
D
k
(
i
)
D_k^{(i)}
Dk(i)表示从判别器
D
k
D_k
Dk 抽取的 第
i
t
h
i_{th}
ith 层特征。匹配损失函数为:
L
F
M
(
G
,
D
k
)
L_{FM}(G, D_{k})
LFM(G,Dk) ,公式如下;
T
T
T 代表所有的层,
N
i
N_{i}
Ni代表每一层的所有Feature Map
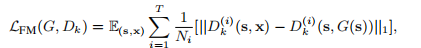
- 判别器的loss为:
λ
\lambda
λ 控制着重要的GAN Loss 和 特征匹配函数的权重比; 对于
L
F
M
L_{FM}
LFM函数中的
D
k
D_k
Dk, 它起到抽取特征的作用,不会最大化
L
F
M
L_{FM}
LFM的loss
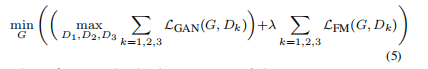
-
感知损失函数(VGG Loss)
- 早期都使用了图像像素空间的L2 loss,但是L2 loss与人眼感知的图像质量并不匹配,恢复出来的图像往往细节表现不好;
- L2 loss逐步被人眼感知loss所取代。人眼感知loss也被称为perceptual loss(感知损失),它与MSE采用图像像素进行求差的不同之处在于所计算的空间不再是图像空间。
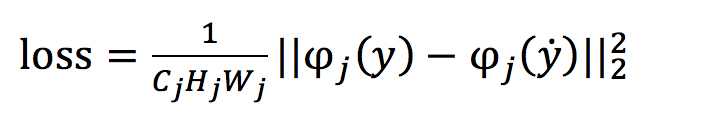
- 通过比较待生成的图片经过CNN的feature值与目标图片经过CNN的feature值,使得待生成的图片与目标图片在语义上更加相似(相对于Pixel级别的损失函数)
- 本作者加上感知损失,主要提高图片生成的效果,但是不是必须的(结果如下);

-
Loss 设计初衷
- 使用Feature matching loss和Content loss计算特征的loss,而不是计算生成样本和Ground truth的MSE,主要在于MSE会造成生成的图像过度平滑,缺乏细节。
- Feature matching loss和Content loss只保证内容一致,细节则由GAN去学习。
增加实例信息

增加实例级别的信息
- 语义分割图和实例分割图的最大差别在于后者区分相同类别的实例,比如一张图中的2个人,在语义分割图中会用同一种颜色来表示这2个人,而在实例分割图中会用2种不同的颜色来表示这2个人。
- 在pix2pixHD的生成器和判别器中同样利用了实例级别的信息,如Figure4所示,(a) 是语义分割图,(b) 是实例边缘图,基于 (a) 和 (b) 就可以区别不同实例。
实现层面
- 原本生成器的输入只是语义分割图 (a),而现在变成将语义分割图 (a) 和实例边缘图 (b) 在通道维度上concat后才作为生成器的输入;同理,原本判别器的输入只是语义分割图和真实图像或生成图像在通道维度上concat后的结果,而现在变成语义分割图、实例边缘图和真实图像或生成图像在通道维度上concat后的结果。
语义编辑
不同于pix2pix实现生成多样性的方法(使用Dropout),这里采用了一个非常巧妙的办法,即学习一个条件(Condition)作为条件GAN的输入,不同的输入条件就得到了不同的输出,从而实现了多样化的输出,而且还是可编辑的。具体做法如下:

- 流程
- 首先训练一个编码器
- 利用编码器提取原始图片的特征,然后根据Labels信息进行Average pooling,得到特征(上图的Features)。这个Features的每一类像素的值都代表了这类标签的信息
- 如果输入图像有足够的多,那么Features的每一类像素的值就代表了这类物体的先验分布。 对所有输入的训练图像通过编码器提取特征,然后进行K-means聚类,得到K个聚类中心,以K个聚类中心代表不同的颜色,纹理等信息
- 实际生成图像时,除了输入语义标签信息,还要从K个聚类中心随机选择一个,即选择一个颜色/纹理风格
- 这个方法总的来说非常巧妙,通过学习数据的隐变量达到控制图像颜色纹理风格信息。
- 应用

- 实例级别的修改
- 用户可以将修改后的语义分割图输入模型得到合成图像。比如可以基于一张实际拍摄的图像先得到其语义分割图,然后可以手动修改这张语义分割图,比如将其中的人去掉,或者将其中的树变成房子,最后我再将修改后的语义分割图作为生成器的输入得到一张合成图像。比如Figure1(b)就是将语义分割图中的树换成房子后得到的合成图像。
- 合成图像多样化
- 基于同一张输入图像能够得到更加多样的合成图像是目前图像合成领域的研究热点。比如Figure1(c)就是基于(a)中的语义分割图得到的另一张合成图像,和(a)图在车颜色、道路方面都不大一样。
- 实例级别的修改
- 更多效果

评判标准
- 主观评价
- Amazon Mechanical Turk (MTurk) platform
- 客观评价
- 基于算法得到的合成图像做语义分割得到标签图,可以计算该标签图的指标,假如和基于真实图像做语义分割得到的标签图计算的指标接近,那就在一定程度上说明合成图的质量较高,Table1就是这样的实验结果对比。
- 本作者用的分割算法为PSPNet;

总结
作者主要的贡献在于:
- 提出了生成高分辨率图像的多尺度网络结构,包括生成器,判别器
- 提出了Feature loss和VGG loss提升图像的分辨率 - 通过学习隐变量达到控制图像颜色,纹理风格信息
- 通过Boundary map提升重叠物体的清晰度
这部分主要讲了图片的合成和高分辨率,下一篇讲视频的合成
文献
- https://arxiv.org/abs/1711.11585
- https://zhuanlan.zhihu.com/p/56808180
- https://cloud.tencent.com/developer/article/1459535















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









