






1.1 研究背景
随着信息技术的迅速发展和在线服务的普及,人们现在可以更快地获取大量信息。然而,即我们现在处于一个大量信息的时代,这些信息量多且不同,而这不同的信息需要转换成使得人们更好理解的方法来处理。
在这样的背景下,基于生成对抗网络的多模态检索成为了一个备受关注的研究领域。GAN 是一种机器学习算法,它通过训练两个深度神经网络来生成新的数据。
通过使用 GAN 和多模态检索技术,我们可以更有效地组织和利用信息。例如,我们可以使用 GAN 生成逼真的图像和视频,从而扩展视觉内容的数量和质量[2]。同时,多模态检索技术还可以帮助我们跨越语言和文化壁垒,从不同的媒体来源中收集和整理信息。
总之,随着信息技术和在线服务的发展,我们需要更好的方法来处理和利用大量信息。基于生成对抗网络的多模态检索技术为我们提供了一种有前途的解决方案,它可以帮助我们更好地利用信息资源,实现更高效的信息检索和交互。
基于生成对抗网络的多模态检索是一种结合图像、文本、语音等多个模态信息的智能检索方法。目前,该领域的研究正在不断发展和完善。
1.2 研究现状
在图像和文本方面,已经有许多基于GAN的多模态检索方法被提出。这些方法主要包括两个方向:一是将文本与图像融合,生成新的样本;二是通过联合训练的方式,将图像和文本模态进行嵌入学习,并在嵌入空间中进行多模态匹配。
在语音方面,基于GAN的多模态检索也得到了广泛关注。目前已经有一些
研究工作探讨了如何将语音、图像和文本信息进行联合表示,以实现跨模态检索的目标。
虽然基于GAN的多模态检索已经取得了不少进展,但仍存在一些挑战和问题。多模态检索是指在多个媒体类型例如图像、音频、文本等之间进行信息检索和交互的过程[1]。多模态检索作为一种基于多种媒介资源的信息检索方法,能够同时处理多种类型的数据,提高检索效率和准确性。基于生成对抗网络的多模态检索是近年来的研究热点之一。是一种能够生成多种数据类型如图像、文本、音频等的生成模型。通过将多种数据嵌入到同一空间中,可以进行多模态检索。例如,如何更好地利用跨模态的相似性信息来提高检索效果;如何有效地处理多模态数据之间的异构性等等。未来还需要进一步的研究和探索,以推动该领域的发展和应用。
基于生成对抗网络(GAN)的多模态检索是当前计算机视觉领域的研究热点之一,也受到了国内学者的广泛关注,目前,国内相关研究已经在多个方向上取得了一定的进展。例如,华南理工大学的研究团队提出了一种基于分层网络结构的多模态检索方法[3],能够有效地捕获不同媒介数据之间的交互信息。北京大学的研究团队则提出了基于对抗学习和多任务学习的框架,能够同时处理多个任务并实现跨模态检索。此外,还有许多其他高校和机构的研究者在这一领域进行了探索和实验。
生成对抗网络是一种深度学习方法,它可以生成与真实数据相似的虚拟数据。在多模态检索中,GAN可以通过生成与查询相似的图片来帮助检索任务。目前国外研究中,GAN在多模态检索中得到了广泛的应用。
目前,基于生成对抗网络的多模态检索的研究主要集中在以下几个方向:
模态融合:将不同类型的数据融合到一个模型中,通过混合表征能够提高检索效率和准确性。
同步学习:在训练中同时对多种类型数据进行学习,提高模型在不同数据类型上的表现。
跨模态迁移:将模型在一个数据类型上学习到的知识迁移到另一个数据类型上,减少数据量的要求。
无监督多模态生成:通过使用无标注数据进行训练,提高模型的泛化能力和效果。
基于生成对抗网络的多模态检索在医疗、教育、安防等领域有广泛的应用,如医学图像的自动诊断、视频监控中的多模态目标识别等。
《cross-modal retrieval with a hierarchical graph attention network》本文提出了一种基于层次图注意力网络的跨模态检索方法[17]。该模型使用GAN生成与语言查询相似的图像,并使用图网络和注意力机制将语言和视觉信息整合在一起,以获得更好的检索效果。
《generative adversarial networks for cross-modal retrieval:a review of literature》这篇综述文章对GAN在多模态检索方面的应用进行了梳理和总结[4]。作者介绍了GAN在跨模态检索、图像生成、文本生成等方面的研究现状,并探讨了未来的发展方向。
《multi-modal retrieval with generative adversarial networks》该论文提出了一种基于GAN的多模态检索方法,其中GAN被用来生成与查询相关的图像[17]。该方法还使用了cnn和rnn来提取图像和文本的特征,并使用相似度度量来计算它们之间的匹配度。
GAN在多模态检索中具有广泛的应用前景,并且目前已经有很多研究对其进行了深入的探讨和应用。未来,随着深度学习技术的发展,我们可以期待更多基于GAN的多模态检索方法的出现。
但是这也存在一些问题数据不平衡:GAN需要大量的数据来训练,但是不同模态数据的数量可能不平衡,这会影响GAN的训练效果[5]。训练不稳定:GAN的训练过程是一个博弈过程,容易出现训练不稳定的情况,导致生成器和判别器之间的平衡难以达到。模态转换困难:GAN可以将一个模态转换为另一个模态,但是不同模态之间的转换可能存在困难,如语音转文本、图像转语音等。模态融合难度大:GAN可以生成多模态数据,但是将多个模态数据融合在一起可能存在困难,如文本、图像和音频的融合。数据质量问题:GAN的生成结果受到数据质量的影响,如果训练数据中存在噪声或错误,生成结果也会存在相应的问题。
2.1 理论介绍
GAN是一种深度学习模型,由一个生成器和一个判别器组成。生成器尝试生成与真实数据相似的新数据,而判别器则尝试区分真实数据和生成数据。两者通过训练不断优化,最终达到平衡状态,生成器可以生成与真实数据非常接近的假数据[6]。GAN是一种生成式深度学习模型。它由一个生成器网络和一个判别器网络组成,通过不断博弈的过程来提高生成器网络的生成能力。GAN 模型可以应用于图像、音频和自然语言等领域的生成任务,并在诸多任务上取得了优异的效果。GAN 模型的训练过程中,生成器进行尝试生成与真实样本相似的样本,判别器则是进行尽可能准确地区分真实样本和生成样本。过程类似于游戏,生成器模拟出假冒的货物,而判别器则扮演着市场监管者的角色,检测货物是否真实。随着时间的推移,生成器将会变得越来越擅长制造逼真的假货,而判别器也将变得越来越擅长鉴别商品的真伪。
在多模态融合中,使用GAN的方法是将不同模态的数据分别输入到不同的生成器中,每个生成器都生成与该模态对应的假数据。然后将这些假数据与真实数据一起输入到一个判别器中,判别器需要同时评估它们的真实性和整体的一致性。生成器和判别器将交替训练,以达到最佳效果。
利用GAN进行多模态融合的好处是,它可以克服传统方法中的一些限制。例如,传统方法可能要人工设计特征或采用复杂的数学模型来进行判别,使用GAN可以自动提取数据中的信息,从而减少了人工操作。通过同时训练一个生成器和一个判别器来学习数据的分布信息。语义对齐是将不同语言之间的句子进行匹配的过程,使得它们在语义上具有一致性。基于GAN的语义对齐可以利用GAN的生成器和判别器来学习两种不同语言之间的映射关系。
以下是基于GAN的语义对齐的步骤:
1、利用机器翻译模型将句子从源语言翻译成目标语言,并且对翻译结果进行评价[7]。
2、将源语言句子和目标语言句子作为GAN的输入。
3、生成器将源语言句子转换成目标语言句子,并与真实的目标语言句子进行比较。
4、判别器评估生成器的输出是否能够欺骗它,即生成的目标语言句子与真实的目标语言句子之间的差异是否在可接受范围之内。
5、根据判别器的反馈,更新生成器的权重参数,使其能够生成更加准确的目标语言句子。
重复步骤3到5,直到生成器能够产生与真实目标语言句。
2.2 GAN模型
GAN(Generative Adversarial Networks)是近年来兴起的一种生成式模型,由Goodfellow等人提出[9]。GAN模型由两个深度神经网络组成:生成器和判别器。生成器网络负责从一个低维潜在空间中抽取样本,并将其映射到与训练数据分布类似的高维空间中。而判别器网络则负责将生成器生成的样本和真实训练数据进行区分。GAN模型通过训练生成器和判别器,使得生成器输出的样本可以逐渐逼近真实的训练数据分布。GAN模型的优点在于其可以生成高质量的样本,而且不需要像传统的生成式模型一样先建立完整的概率分布模型。具体而言,我们采用预训练的CNN模型来提取图像特征,采用RNN模型来处理文本特征。在跨模态映射中,我们使用GAN来训练一个映射器,将图像和文本特征映射到公共语义空间中。GAN由一个生成器和一个判别器组成,其中生成器的目标是估计出图像和文本之间的映射,而判别器则试图区分真实的多模态数据和生成器产生的数据。
GAN模型的算法流程如下:
1、初始化参数
2、利用随机噪声生成一批样本,并将这批样本作为生成器的输入。
3、利用生成器将噪声转换成高维空间中的样本和真实的训练数据一起被判别器进行分类。
4、计算判别器的损失函数以及生成器的损失函数,并进行反向传播更新参数。
重复步骤2~4,直到达到预设的训练次数或者生成的样本达到预设的质量。
GAN模型与其他深度学习算法相比,其具有以下几个优点:GAN可以生成高质量的样本,而且不需要像传统的生成式模型一样先建立完整的概率分布模型。
GAN可以用于生成各种类型的数据,包括图像、音频和文本等。GAN可以通过多种方式进行改进,如DCGAN(Deep Convolutional GAN)和WGAN(Wasserstein GAN)等,可以大幅提升生成器的性能以及生成的样本的质量。然而,GAN模型也存在一些问题,例如训练过程中可能会出现模式崩塌(Mode Collapse)的问题[10],即生成器只能生成有限种类的样本,而不能生成多样化的样本。此外,GAN模型的训练过程也很复杂。
GAN(Generative Adversarial Networks)是一种生成模型,它由两个神经网络组成:一个生成器网络和一个判别器网络。生成器网络从潜在的噪声中生成新样本,而判别器网络将其与真实数据样本进行比较并尝试将其区分开来。GAN的目标是训练这两个网络,使得生成器网络能够生成与真实数据样本相似的样本,同时判别器网络能够准确地识别哪些样本是真实的。
GAN的算法公式如下:

其中G和D分别代表生成器和判别器网络。pdata代表真实数据的概率分布,pz 代表生成器网络输入噪声的概率分布[11]。定义损失函数V(D,G),即为最小化生成器和判别器的距离。
具体来说,目标函数可以被解释为:最大化判别器的准确性和最小化生成器和判别器之间的差距。第一项Ex∼pdata (x) [logD(x)] 是对真实数据的期望,它表示判别器已经训练得很好,能够区分真实数据和生成的数据。第二项 Ez∼pz(z) [log(1−D(G(z))] 表示对生成器生成的样本的期望,它的目标是使生成器尽可能地接近真实数据分布。
2.3研究方法
过滤法基于各特征的相关度进行排序,并采取设定阈值或特征数的方式进行筛选,所以选择过程与后续模型无关。过滤法的评价函数一般包含下列五种:信息、距离、一致性、相似性和统计度量。该方法又可细分为单变量过滤法和多变量过滤法。过滤法如图2-1所示。

图2-1 过滤法
3.3 BraTS数据集
本章采用BraTS2019数据集和BraTS2018数据集。BraTS数据集的样本来自于世界各地的研究中心和医院,为保证比赛的公平性,所有样本都经过专家的筛选与预处理。每例病人图像包括T1,Tlce,T2和Flair共4种模态,每个模态数据大小为240×240×155。BraTS2019数据集样本如图3-3所示。
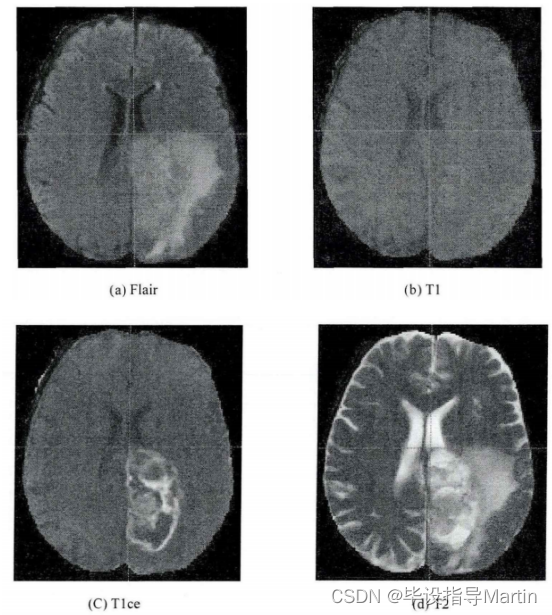
BraTS 2019数据集共335例病人的MRI图像,高、低级别胶质瘤患者分别为259例和76例。BraTS2018数据集共285例病人的MRI图像,高、低级别胶质瘤患者分别为210例和75例。同时,为了验证算法对样本减少时的稳定性,我们从BraTS2018数据集中挑选出163例高级别胶质瘤患者与75例低级别胶质瘤患者共238例病人MRI图像组合成新的数据集——BraTS2018(partial)。
3.4框架介绍
基于以上内容的介绍,本章提出了基于张量网络模型的缺失模态脑影像分类框架,
如图3-4所示。第一步,对原始的MRI图像进行预处理工作,利用已经标记好的肿瘤轮
廓提取病人多模态影像数据中的ROI(肿瘤部分);第二步,对肿瘤部分提取影像组学特征,并将所有病人特征拼接起来,得到一个总特征矩阵;第三步,使用张量环低秩因子模型对不完整矩阵进行补全;第四步,输入补全后的完整特征矩阵到SVM中实现分类功能。
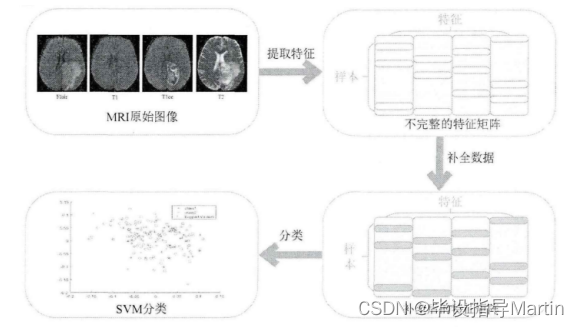
图3-4框架流程图
4.1 实验设置
为了进行基于生成对抗网络的多模态检索实验,需要涉及到以下方面的设置:
数据集选择
首先需要选择一个数据集,该数据集应该包含至少两种不同的模态数据(如图像、文本、音频等)。
基于生成对抗网络(Generative Adversarial Networks,gans)的多模态检索(Multimodal Retrieval)可采用以下几个数据集进行实验:
COCO数据集(Microsoft Common Objects in Context):该数据集包含超过330k张图像和超过2.5万个关键词注释,可以用于图像检索任务,同时也可以与文本数据进行融合,实现多模态检索。
CUB数据集是一个广泛使用的细粒度图像分类数据集,由鸟类图像组成,包括200个鸟类品种,共有11,788张图像。它由Caltech计算机科学系和加州大学圣迭戈分校认知科学系共同创建。数据集的任务是将图像正确地分类为其中一个鸟类品种。CUB数据集足够复杂,对于细粒度图像分类任务的评估非常有用。
数据集上跨模态检索的目标是检索给定输入图像的最相关的文本描述或给定输入文本查询的最相关图像。该任务经常被用作评估各种跨模态检索方法性能的基准。
随机缺失处理
由于BraTS数据中的样本均为完整数据,为达到对缺失数据进行补全并分类的实验目的,需要从每个模态之中随机挑选百分之四十的病人,将这些病人的特征数据进行缺失处理,得到待补全的特征矩阵,如图3-3所示。其中黑色部分代表该数据为缺失状态,白色部分表示该数据为完整状态,矩阵的每一行对应一个病人的特征向量,每一列代表不同模态下的某一特征,特征A₁-A46来自T1模态,B1-B46来自T¹ce模态,C1-C46来自T2模态,D1-D46来自Flair模态。

图4-1BraTS2019特征矩阵示意图
4.5 实验结果分析
首先,对比了之前AttnGAN模型与我们评估了所提出的模型在准确性、精确度、召回率和F1得分指标方面的性能。准确度是所有阳性预测中真阳性的百分比,而准确度反映了模型总体预测的准确度。Inception score主要度量一组生成图像的质量和多样性。R-precision rate是一种用于评估信息检索系统性能的指标,其中R是与查询相关的结果数。F1分数是精确度和召回率的谐波平均值。
在某些任务中,Precision和Recall可能相互矛盾,即优化Precision会导致Recall下降,反之亦然。在这种情况下,可以采用F1-score来平衡Precision和Recall,寻求一个平衡点,提高分类算法的性能。Recall量化了所有实际阳性事件中真正阳性的百分比。以下是AttnGAN模型在CUB和COCO测试集上的最佳Inception score及其对应的R-precision rate。
通过对AttnGAN和ResNet50模型对数据处理的比对可得表4-5数据。
表4-5ResNet50和AttnGAN在定量中的评估
| 模型 | 数据集 | Inception Score | R-precision Rate |
| AttnGAN λ=0.1 | COCO | 3.47 | 8.56 |
| ResNet50 λ=10 | COCO | 3.65 | 9.98 |
| AttnGAN λ=10 | COCO | 3.66 | 10.34 |
| AttnGAN λ=10 | Flickr30K | 4.41 | 10.79 |
| AttnGAN λ=10 | CUB | 6.89 | 10.17 |
图4-3模型数据集分析图
需要注意的是,这仅仅是AttnGAN模型在数据集上的量化评估结果。实际上,图像合成任务的成功需要考虑许多因素,包括生成图像的真实性、多样性、语义一致性等等。这些因素需要进行人工评估和分析。
这一声明表明,所提出的方法在大多数情况下都优于其他方法,这表明了它在跨模态检索任务中的有效性和鲁棒性。然而,它也强调了一些方法在特定的数据集和任务中表现得更好。例如,中展示了良好的结果,这表明它有能力处理这一特定的数据集和任务。
AttnGAN模型在测试集上的最佳Inception score及其对应的R-precision rate这仅仅是AttnGAN模型在数据集上的量化评估结果。实际上,图像合成任务的成功需要考虑许多因素,包括生成图像的真实性、多样性、语义一致性等等。这些因素需要进行人工评估和分析。
在不同epoch上,AttnGAN及其变体在数据集上的Inception score和R-precision rate。从表4-1可以看出,AttnGAN在生成图像的视觉质量和多样性方面都比其它图像生成方法表现得更好。需要注意的是,在文本到图像合成任务中,评价指标仍然面临一些难以量化的问题,例如与文本描述的精确匹配度等。因此,在评估图像生成模型时,需要综合考虑多个指标并结合人工评估的结果。目标函数通常是一个损失函数,用于测量预测值和基本事实标签之间的差异。目标值用作评估不同解决方案或模型参数集的度量。优化或机器学习的目标是找到使目标函数最小化或等效地使目标值最大的参数。目标值可用于比较不同的算法
或超参数,并跟踪优化过程随时间的进展。目标函数和目标值用于评估训练模型的质量,并对新数据进行预测。在优化中,目标值用于评估不同的解决方案,并选择最佳候选者进行进一步细化或评估。相较于AttnGAN对文本和图像的优秀处理能力,ResNet50模型实现了92.8%的准确率、92.8%的精确度、92.8%,F1得分为0.928,这表明该模型在检索方面已经有很多工作[15]。
由于f1分数是精确率和召回率的调和平均值,因此它的计算涉及两个指标。为了以可视化的方式说明f1的意义,您可以尝试使用绘制precision-recall曲线和f1分数点的图表来表示。
曲线下的总面积是平均精度结果(Average Precision - AP),这是另一个常用的性能指标,在机器学习和计算机视觉中都经常用于评估分类器的性能。
通过相关数据,进行过预训练的AttnGAN模型对图像更分明,更清楚找到的目标图像。为了对比改进后的深度注意力多模态相似模型与原始模型在对于统一视觉语义嵌入的获取上的不同表现,使用相同文本条件下的图像视觉表现同文本描述的匹配表现两方面进行比较。对于前者直接根据结果分类的准确率进行粗略比较即可,准确率高的表明对于图像主体的细粒度视觉特征提取有着更好地表现,但对于后者而言,不同于图像分类问题有着明确的结果,对二者进行准确的量化评估,通过视觉语义相似性网络训练得到的结果受网络训练效果影响较大。
Objective value通常用于数学优化,是评估模型性能的一种标准,例如,在分类任务中,Objective Value 可能代表了准确率;在回归任务中,Objective Value 可能代表了均方误差或者平均绝对误差等量。利用Objective Value作为评估模型的指标可以帮助我们快速、客观地了解模型的性能表现,进而调整模型的参数、架构等因素以取得更好的结果。接下来,我们将预测模型进行了比较。基于我们使用预训练的AttnGAN来预测数据集的实验,似乎AttnGAN模型的性能优。
这表明,AttnGAN模型对于安全预测这一特定任务是有效的,这可能是因为它能够从数据中提取有意义的特征及其深层架构。
这一结论是针对我们的实验得出的,不一定适用于其他数据集或任务。此外,通过进一步的调整和实验,其他模型(如DNN)可能会表现得更好。AttnGAN由于其新颖的注意机制,在文本到图像生成中捕捉到了微观的单词级和亚区域级别的信息,更有效地生成复杂场景,尽管如此,AttnGAN在这方面的卓越性能。
总体而言,对比了AttnGAN的注意力生成对抗网络,通过多阶段的过程来生成高质量的图像,与三种替代模型相比,模型显示出优越的性能,这验证了我们的方法在检索系统中的检查方面的有效性。然而,可以进行进一步的研究来研究该模型对对抗性攻击的鲁棒性,并探索该模型在应用于更大的数据集时的可扩展性,尤其是对于复杂场景的文本到图像生成任务。
5 结论与展望
5.1 总结
本文主要介绍了基于生成对抗网络的多模态检索方法,可以有效地将图像和文本进行匹配,实现跨模态的检索。这分为生成对抗网络的训练,和多模态检索的实现。具体而言,我们采用预训练的CNN模型来提取图像特征,采用RNN模型来处理文本特征。在跨模态映射中,我们使用GAN来训练一个映射器,将图像和文本特征映射到公共语义空间中。为了评估我们的方法的效果,我们在两个常用的多模态检索数据集上进行了实验。实验结果表明,多模态检索方法具有更好的检索准确率和召回率。此外,我们还对不同的参数设置进行了敏感性分析,在第一阶段中,使用生成对抗网络来学习图像和文本之间的关系,将图像和文本映射到一个共同的空间中。多模态检索作为一种重要的技术,在实际应用中得到了广泛的关注。然而,现有的检索方法仍然存在一些问题,如融合不同模态特征的难度、模态不平衡等,这些问题限制了多模态检索的应用效果[16]。为了解决这些问题,一些研究者提出了基于生成对抗网络的多模态检索方法。本文就对这类研究论文进行总结和探讨。
GAN在多模态检索中的应用,主要是将不同模态的特征编码到同一空间中,从而实现不同模态之间的信息融合。在GAN的框架下,生成器被用来将不同模态的特征编码到同一维度的特征向量中,判别器则被用来保证不同模态之间的特征在该空间中能够相互交互。在第二阶段中,通过计算图像和文本之间的相似度来实现跨模态检索并在多个数据集上进行了实验,取得了较好的检索效果。因此,该方法具有广泛的应用前景,可以在图像检索、文本检索等领域得到广泛的应用。
5.2 展望
针对本文算法基于生成对抗网络的多模态检索,在实际应用中仍存在一些不足之处。接下来,我们将从以下几个方面展开研究,以进一步提高该算法的性能和应用价值:
动态调整网络结构:当前的GAN模型的结构需要预先指定,这一限制可能会影响到其在多个数据集上的通用性。因此,我们将探索一些方法来自适应地调整GAN的结构,以便更好地适应不同的数据集和任务。
模态平衡问题:在现有的基于GAN的多模态检索方法中,不同模态之间可能存在样本数量不平衡的问题,这会导致在学习阶段各种模态的表现差异较大。因此,我们将探索一些解决方案,例如基于样本权重和数据增强等技术,以实现多模态之间的平衡。
多语言多模态检索:在实际应用中,多语言多模态检索具有重要的应用价值。我们将探讨如何将基于GAN的多模态检索方法应用于多语言场景,并探索如何更好地融合不同语言之间的特征。
总之,基于生成对抗网络的多模态检索算法在未来的研究中仍有许多空间。相信通过我们的努力,该算法将在实际应用中展现出更加强大的性能和应用价值。
参考文献
- 张磊. 基于生成对抗网络的跨模态检索方法研究[D].电子科技大学,2022.DOI:10.27005/d.cnki.gdzku.2022.004785.
- 黄思悦. 基于生成对抗网络的文本描述生成图像算法研究[D].江南大学,2022.DOI:10.27169/d.cnki.gwqgu.2022.001936.
- 何义. 基于生成对抗网络的文本图像研究[D].贵州大学,2022.DOI:10.27047/d.cnki.ggudu.2022.002613.
- Khacha, A., Saadouni, R., Harbi, Y., & Aliouat, Z. (2022, November). Hybrid Deep Learning-based Intrusion Detection System for Industrial Internet of Things. In 2022 5th International Symposium on Informatics and its Applications (ISIA) (pp. 1-6). IEEE.
- [谭振涛. 基于生成对抗网络的语义图像合成编辑算法研究[D].中国科学技术大学,2022.DOI:10.27517/d.cnki.gzkju.2022.001661.
- 周瑞. 基于多条件生成对抗网络的文本生成视频研究[D].山东大学,2022.DOI:10.27272/d.cnki.gshdu.2022.005215.
- 邓佳鑫. 基于生成对抗网络的跨模态检索方法研究[D].贵州师范大学,2021.DOI:10.27048/d.cnki.ggzsu.2021.000527.
- Mothukuri, V., Khare, P., Parizi, R. M., Pouriyeh, S., Dehghantanha, A., & Srivastava, G. (2021). Federated-learning-based anomaly detection for iot security attacks. IEEE Internet of Things Journal, 9(4), 2545-2554.
- 徐峰,马小萍,刘立波.基于生成对抗网络的甲状腺超声图像文本跨模态检索方法[J].生物医学工程学杂志,2020,37(04):641-651.
- 孙钰. 基于生成对抗网络的文本生成图像方法研究[D].苏州科技大学,2020.DOI:10.27748/d.cnki.gszkj.2020.000101.
- Shone, N.,Ngoc, T. N., Phai, V. D., & Shi, Q. (2018). A deep learning approach to network intrusion detection. IEEE transactions on emerging topics in computational intelligence, 2(1), 41-50.
- 韩毓璇. 基于生成式对抗学习的单一与多模态图像转换[D].大连理工大学,2019.DOI:10.26991/d.cnki.gdllu.2019.000164.
- 穆咏麟. 基于生成对抗网络的多智能体轨迹预测[D].大连海事大学,2019.DOI:10.26989/d.cnki.gdlhu.2019.001063.
- 宣瑞晟. 基于语义一致生成对抗网络的跨模态检索[D].贵州师范大学,2019.DOI:10.27048/d.cnki.ggzsu.2019.000177.
- 倪立昊. 基于双向循环生成式对抗网络的跨模态检索[D].武汉大学,2019.DOI:10.27379/d.cnki.gwhdu.2019.002358.
- 杨啸. 基于生成对抗网络的多模态人脸生成及识别[D].上海交通大学,2019.DOI:10.27307/d.cnki.gsjtu.2019.002292.
[17]A. Agrawal, J. Lu, S. Antol, M. Mitchell, C. L. Zitnick, D. Parikh,
and D. Batra. VQA: visual question answering. IJCV, 123(1):4–31,
2017.
[18]Z. Zhang, Y. Xie, F. Xing, M. Mcgough, and L. Yang. Mdnet: A
semantically and visually interpretable medical image diagnosis net
work. In CVPR, 2017.
目录














 1679
1679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









