







正则表达式是一种匹配文本的模式。.NET框架提供了允许这种匹配的正则表达式引擎,模式由一个或多个字符、运算符和结构组成。
C#中正则表达式有以下几种:
一、 字符转义
正则表达式中的反斜杠“\”指示以下值之一:
- 后接字符为特殊字符,例如,\b 是指示正则表达式匹配应从单词边界开始的定位点,\t表示制表符,而 \x020 表示空间。
未转义语言构造的字符应按字面意思进行解释,例如,大括号 ({) 开始定义限定符,而反斜杠后接大括号 ({)
表示正则表达式引擎应匹配大括号。 同样,单个反斜杠标记转义的语言构造的开始,而两个反斜杠 (\) 表示正则表达式引擎应匹配反斜杠。正则表达式中的反斜杠字符(\)指示其后跟的字符是特殊字符,或应按原义解释该字符。
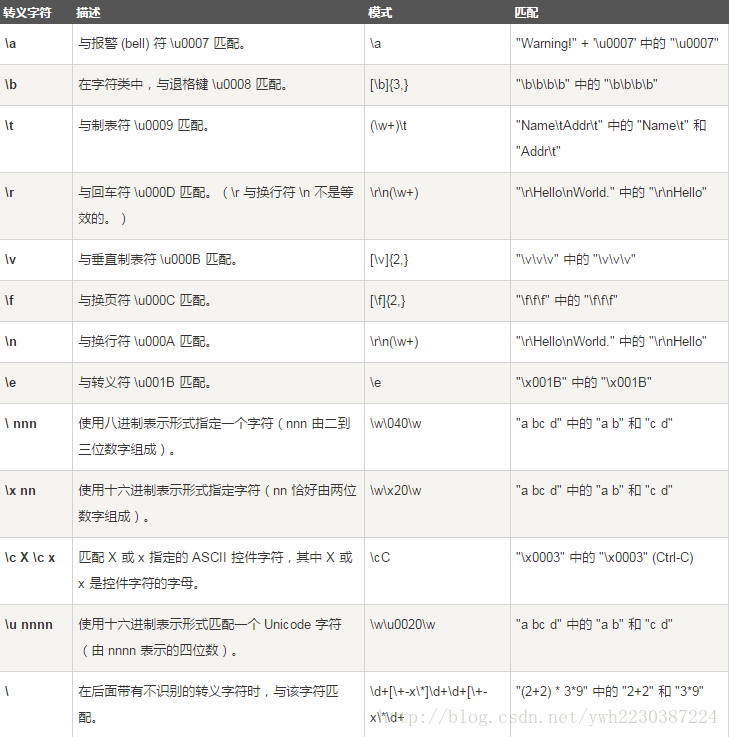
下表列出了转义字符:
正则表达式 \G(.+)[\t|\u007c](.+)\r?\n 可以解释为下表中所示内容:
| 模式 | 描述 |
|---|---|
| \G | 从上次匹配结束处开始匹配 |
| (.+) | 一次或多次匹配任何字符。 这是第一个捕获组。 |
| [\t\u007c] | 匹配制表符 (\t) 或垂直条 ( |
| (.+) | 一次或多次匹配任何字符。 这是第二个捕获组。 |
| \r? \n | 匹配零或一个出现回车符后接新行的次数。 |
二、 字符类
一个字符类定义一组字符,其中的任一字符均可出现在输入字符串中以便成功匹配。
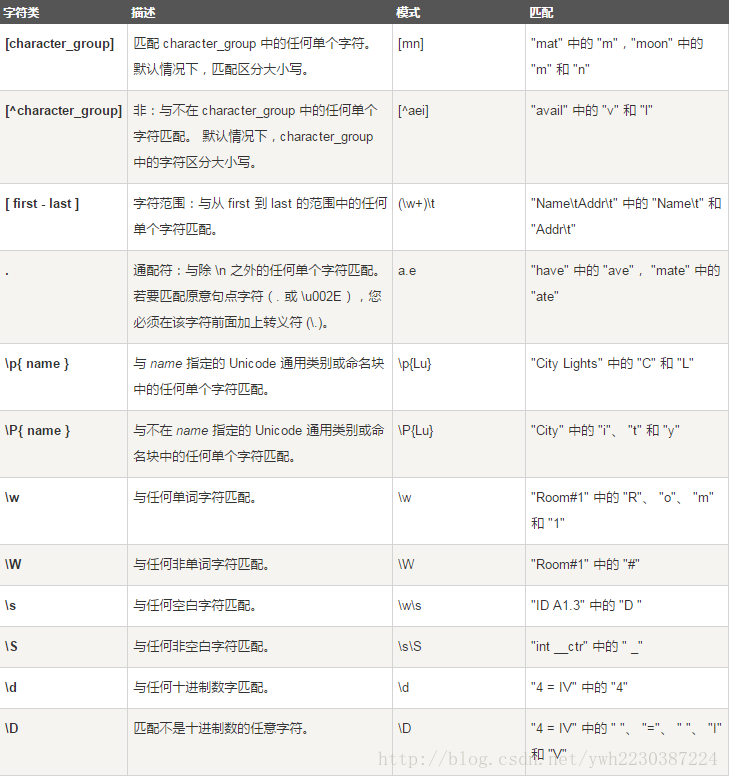
下表列出了字符类:
正字符组:[]
负字符组:[^]
任意字符:.
Unicode类别或Unicode块:\p{}
负Unicode类别或Unicode块:\P{}
单词字符:\w
w 与任何单词字符匹配。 单词字符是下表中列出的任何 Unicode 类别的成员。

空白字符:\s

非空白字符:\S
\S匹配任何非空白字符,它等效于[^\f\n\r\t\v\x85\p{Z}],正则表达式模式与等效于\s的正则表达式模式相反

十进制数字字符:\d
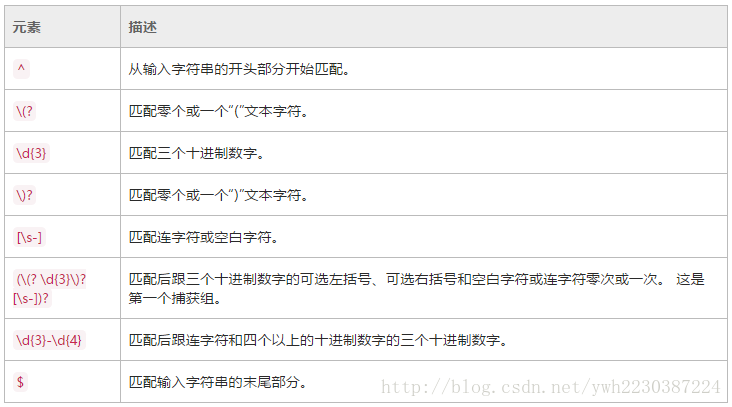
正则表达式模式^(\(?\d{3}\)?[\s-])?\d{3}-\d{4}$ 的定义如下表所示。它测试输入字符串是否表示美国和加拿大的有效电话号码
三、 定位点
定位点或原子零宽度断言会使匹配成功或失败,具体取决于字符串中的当前位置,但它们不会使引擎在字符串中前进或使用字符。
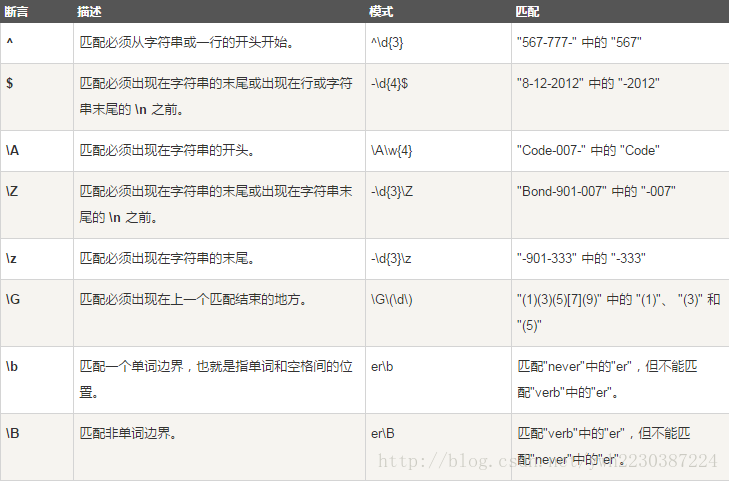
下表列出了定位点:
四、 分组构造
分组构造描述了正则表达式的子表达式,通常用于捕获输入字符串的子字符串。可以使用分组构造来完成下列任务:
- 匹配输入字符串中重复的字表达式。
- 将限定符应用与拥有多个正则表达式语言元素的字表达式。
- 包括有RegX.Replace和Match.Result方法返回的字符串的字表达式。
从Match.Groups属性中检索各个字表达式,并分别从匹配的文本作为一个整体处理它们。
下表列出了受.NET Framework正则表达式引擎支持的分组构造,并指出它们是捕获还是非捕获。
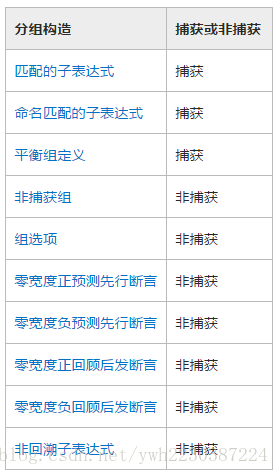
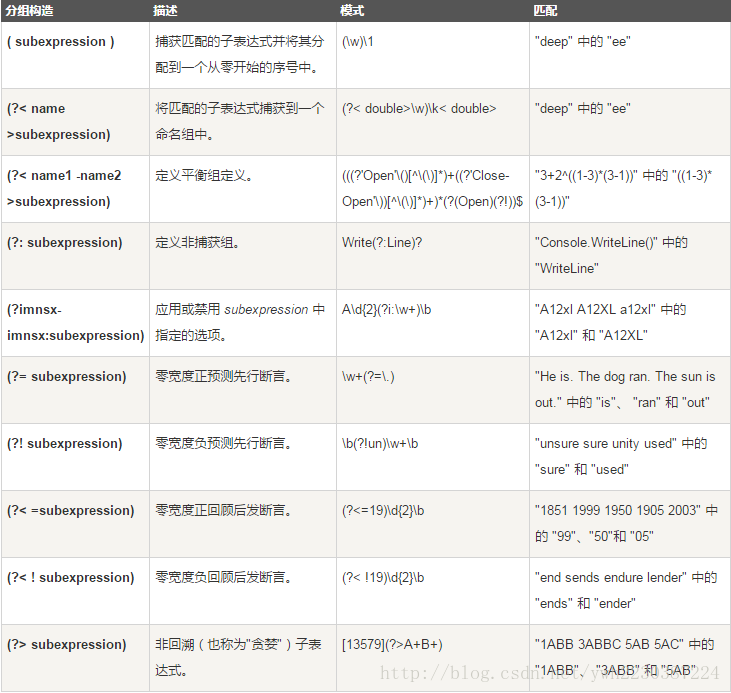
下表给出了分组构造:
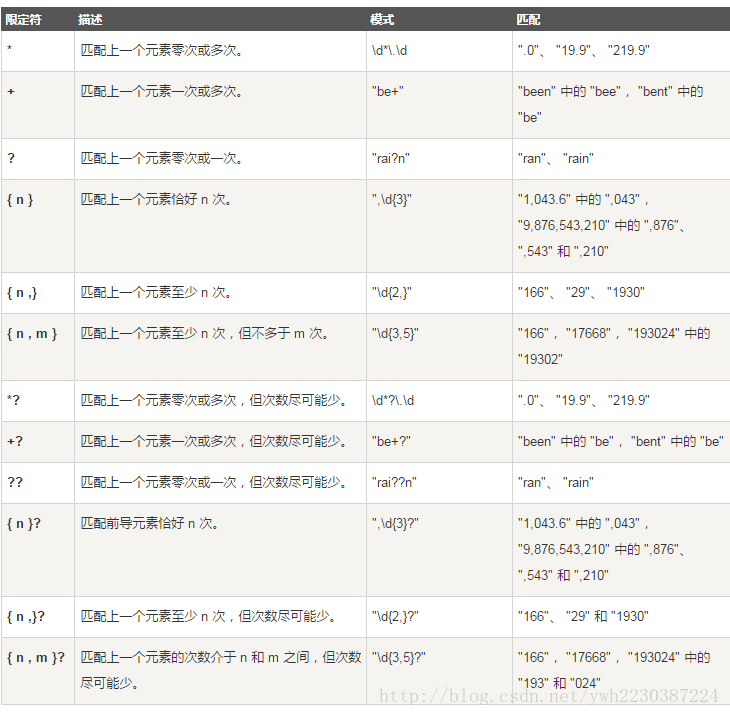
五、 限定符
限定符指定在输入字符串中必须存在上一个元素(可以是字符、组或字符类)的多少个实例才能出现匹配项,限定符包括下表中列出的语言元素:
六、 反向引用构造
反向引用允许在同一正则表达式中随后标识以前匹配的字表达式。下表列出了反向引用构造:

七、 备用构造
备用构造用于修改正则表达式以启用ether、or匹配。下表列出了备用构造:

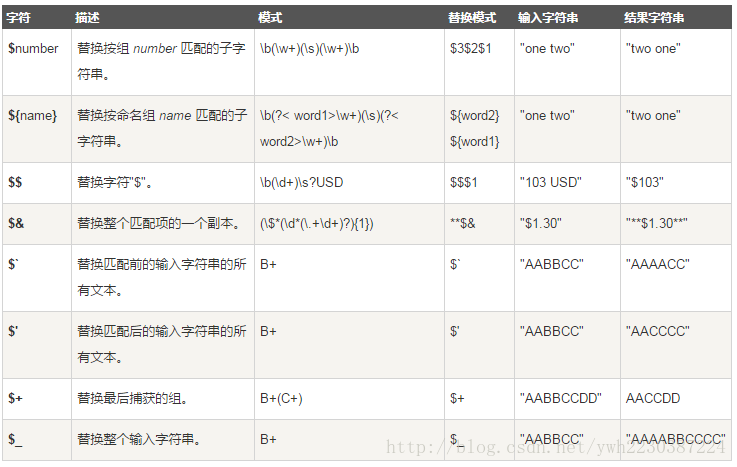
八、 替换
替换时替换模式中使用的正则表达式:
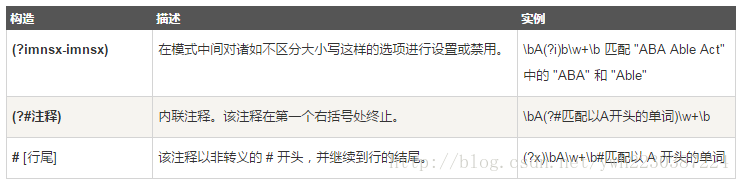
九、 杂项构造
下表中列出了杂项构造:















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









