









 本文详细介绍了Faster R-CNN的目标检测原理,从R-CNN到Faster R-CNN的改进过程,并提供了基于Keras的实现步骤,包括特征提取网络(如VGG16)和RPN网络的构建。适合初学者理解目标检测技术并实践代码。
本文详细介绍了Faster R-CNN的目标检测原理,从R-CNN到Faster R-CNN的改进过程,并提供了基于Keras的实现步骤,包括特征提取网络(如VGG16)和RPN网络的构建。适合初学者理解目标检测技术并实践代码。
保姆级 Keras 实现 Faster R-CNN 一
目标检测因引入深度学习算法后而大火, 而 R-CNN, Fast R-CNN, Faster R-CNN 更是经典之作, 所以想要学习 目标检测 的话, 这三个经典总是绕不过的. 很多同学论文读起来能看懂, 也知道讲的是什么个意思, 但是就是不知道怎么把模型跑起来, 一下手脑子一片白. 下面就为大家分享一下用 Keras 复现的代码和讲解, 希望能帮到想学习的小白或新手. 但是前提是你要懂得
- 逻辑回归(就是分类的意思)
- 线性回归(预测连续值, PM2.5, 波士顿房价之类的)
- 卷积神经网络对图像进行分类, 比如在 MNIST 数据集上的分类, AlexNet, VGG 之类的
- Keras 自定义 Loss
- Keras 自定义层
如果上面的这些都不懂的话, 你真是一个小白, 可以先学一些基础之后回来
一开始我本来想从 R-CNN 写到 Faster R-CNN 的, 但是一想, 我们用的时候还是用 Faster R-CNN 来跑, 没有必要浪费时间去跑一个永不使用的模型, 知道其发展和改进思路就可以了, 所以下面只复现 Faster R-CNN. 而且是从零开始, 当然也可能会讲一些 R-CNN 到 Faster R-CNN 的改进与变化
一. 数据标注
为什么从数据标注开始? 我觉得这是一个困扰新手的问题, 新手学习的时候往往都是用的现成的数据集来做, 用别人的代码跑一下就完了. 但是要把你的想法实现, 数据就是你自己的数据了. 很多教程偏偏不讲这个, 你说气不气人
目标检测 = 分类 + 定位, 所以我们标注的时候, 既要标注类别, 还要标注位置, 标注软件我推荐使用 Labelme, 为什么是它呢? 因为我用的就是这个, 在我的 语义分割 系列文章中一开始就讲了 Labelme 的使用与标注方法, 这里就不详细说明了, 可以参考 语义分割之 数据标注 和 语义分割之 json 文件分析. 语义分割一般使用多边形来标注, 这里定位只需要矩形框, 所以标注的时候选矩形(Rectangle) 就可以了, 类别输入和语义分割一样. 标注时矩形框刚好把目标框住为宜
还是附上图会友好一点


上面是一个类别的情况, 如果是多个类别, 标签就写相应的类别(比如 dog)就可以. 到此, 数据就准备好了
二. 目标检测原理
在文章开始讲了你要懂图像分类, 接下来就要讲为什么了
一开始我们并不知道怎么实现目标检测, 但假设你有一台超级计算机或者量子计算机, 速度快到没朋友, 再假设你有一个可以对图像进行分类的网络, 这个网络有个特点, 就是目标刚好和图像一样大, 换种说法就是能包住目标的最小矩形和输入图像一样大时分类的置信度(网络输出的分数)最高. 好, 有这两个条件之后, 天下武功, 唯快不破, 我们就可以用最暴力的方式来做目标检测——穷举法. 如下图

我们分别用从 小到大(为了满足不同大小的目标)的矩形依次 从左到右, 从上到下(为了满足不同位置)在图像上滑过, 把矩形经过的图像抠出来, 输入到分类网络中, 网络会输出一个相应类别的分数, 最高分数对应的矩形就是最终要检测的目标位置, 比如上面的绿色框. 所以这样一看来, 目标检测是不是很简单? 原理是不是有点太 Low 了, 没有高大上的感觉. 但是就这么一个 Low 的方法要实现起来还不太容易
理想很丰满, 现实很骨感. 用上面的方法做目标检测你遇到的第一个问题是 你的电脑永远都不够快, 计算量之巨让你做不到实时检测. 假设图像是 800×800 像素, 滑动矩形的尺寸从 8×8 到 800×800, 那循环次数大约(不考虑滑动矩形限制在图像中)是 8004 = 4096 亿次, 假设分类网络的前向计算时间是 0.2 秒, 跑一张图可能要几百年
为了解决我们没有理想计算机的问题, 那我们改变一下策略, 不要无意义的在图像上滑动, 而是想办法找出一些可能是目标的区域, 再将这些区域作为输入. 怎么找这些区域呢? 对, 你可能想到了 Selective Search 方法, 这个方法大大减少了可能是目标区域的数量(相对穷举法), 具体的原理你可以参考一下其他文章. 用白话讲就是看一下相邻的像素是不是可能属于一个目标来分割区域, 这个不是重点. 这样一张图能找出大约上千个区域, 很多地方都喜欢说 2000 个, 那就算 2000 个好了. 那相比于 4096 亿是不是少了太多倍了. 一张图计算时间缩短到了 40 秒, 加上 Selective Search 大概要 2 秒, 整个检测时间大概需要 42 秒. 这样虽然没能做到实时检测, 但是至少是有进步的
虽然输入的图像减少了, 但也产生了另一个新问题, 就是 Selective Search 选出来的框未必就刚好和目标一样大且重合, 所以在 R-CNN 中用一个线性回归器来修正位置, 这个放到后面讲, 这个重合度有一个专用术语叫 IoU (Intersection over Union), 后面会讲怎么计算这个 IoU 和 它的作用
第二个问题是现实的分类网络并不能区分目标是否刚好和输入图像一样大, 目标比滑动矩形稍微大一点或者小一点输出的分数有可能比刚好一样大的分数还要高. 这样就导致了一个问题, 在目标周围滑过的尺寸或位置差异比较小的矩形, 你没有办法用分数去判断哪个矩形最合适. 所以就有了 非极大值抑制 方法
三. R-CNN 到 Faster R-CNN
R-CNN 就用了上面讲的三个技术来做目标检测, 总结一下就是 Selective Search, 非极大值抑制 和 线性回归, 当然你还会讲一个 SVM, 这个是一个分类方法, 在这里不算是解决前面提到的速度和位置定位的问题
1. R-CNN 为什么慢
在 R-CNN 中, 网络前向计算的时间远大于 Selective Search 的时间, 我们来分析一下为什么会这样
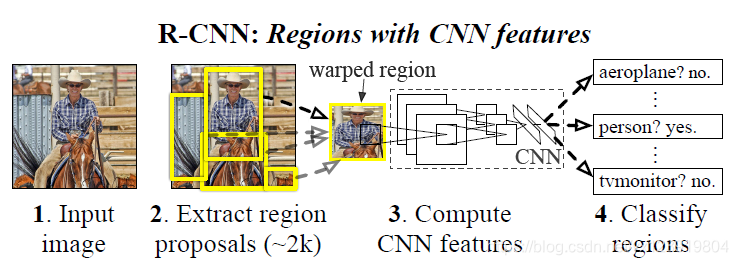
上图是R-CNN的一个大概流程, 你肯定看过其他很多文章都讲了无数遍了, R-CNN 之所以慢, 是因为提取出来的候选区域(推荐区域)每一个都要经过 CNN 网络提取特征, 有 2000 个候选区域就要计算 2000 次, 所以大分部时间都浪费在这里
2. Fast R-CNN 为什么比 R-CNN 快
R-CNN 慢在了候选区域每一个都要单独计算, Fast-RCNN 比较巧的地方是先将要检测的图计算一次卷积特征, 再利用 Selective Search 选出来的区域在卷积特征图上去找对应的矩形把特征图抠出来. 这个抠出来的特征图和用 Selective Search 选出来的图经过卷积计算不就是一回事吗? 就这样把 2000 次计算变成了 1 次. 为什么 Selective Search 选出来的图能在一次性计算得到的特征图中找到对应区域呢? 卷积不改变图像尺寸, Pooling 成倍减小图像尺寸, 所以只要将 Selective Search 区域坐标按相同倍数缩小就对上了
3. Faster R-CNN 为什么比 Fast R-CNN 快
但是, 永远都会有但是, Fast R-CNN 前向计算的时间是减少了, Selective Search 却成为了瓶颈, 而且只能在 CPU 中计算, 不能和网络合为一体. 武侠小说都讲究这个, 要与什么合为一体. 那能不能把区域生成的功能放到网络中一起呢? 这个是肯定的, 要不然我就不写了. 这里就有一个叫 Region Proposal Network (RPN) 的网络了(后面的代码部分也会讲), 它实现了区域生成的功能, 而且共享了主干网络的卷积特征, 计算时间远远小于 Selective Search, 论文中讲大概是 10mS. 所以总结, Faster R-CNN = RPN + Fast R-CNN
四. Faster R-CNN Keras 实现
前面说了这么多废话, 不讲又不完整, 现在终于到了你心心念念的 Faster R-CNN 了, 下面是论文上的图
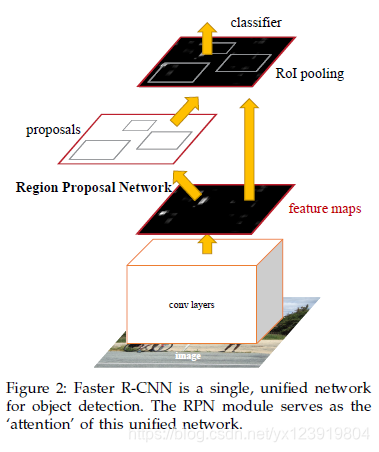
我们就按上图(Figure 2)中的架构从下到上一步一步用代码完成各个功能, 你就说这篇文章是不是良心之作, 下面各种内功心法都有了. 欲练此功, 不必自宫

开始之前我们先做一些准备工作, 代码我都是在 Jupyter Notebook 中完成的
可能会用到的库
# !/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import os.path as osp
import copy
import time
import random
import json
import math
import cv2 as cv
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import xml.etree.ElementTree as et
from random import shuffle
from tensorflow import keras
from keras import backend as K
from tensorflow.keras.models import load_model
日志路径
log_path = osp.join(os.getcwd(), "train_log")
if not osp.exists(log_path):
os.mkdir(log_path)
后面会用到的一些配置信息, 用到你自己的数据集的时候按需修改
# 配置参数
AUGMENT_NUM = 4 # 图像强数量, 这里进行了左右, 上下, 左右上下一起翻转, 加上原图所以是 4, 如果不增强则为 1
FEATURE_STRIDE = 16 # 特征图相对于原始输入图像的缩小的倍数, 如果用 VGG16 作为特征提取网络就是 16
SHORT_SIZE = 300 # 图像缩放最短边度长(论文是600, 300 是为了训练速度快一点)
ANCHOR_SIZE = (64, 128, 256) # anchor_box 3 种边长(论文是 128, 256, 512, 配合最短边为 600, 最短边为 300 时缩小一倍)
ANCHOR_RATIO = (0.5, 1.0, 2.0) # anchor_box 3 种边长比例
ANCHOR_NUM = len(ANCHOR_SIZE) * len(ANCHOR_RATIO) # 每一个特征图上的点对应的 anchor_box 的数量
TRAIN_NUM = 256 # 每一张图中参加训练的 anchor_box 的数量
# 类别列表, back_ground 放到最开始, 其他类别不分先后
CATEGORIES = ("back_ground",
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor")
DATA_PATH = "data_set" # 这样写表示相对路径, 也可以写成绝对路径, 你喜欢就好
1. 特征提取网络
有些地方也叫主干网络, 反正都是一个意思, 不用纠结. 这个可以用 VGG16 之类的, 也可以用其他的你喜欢的卷积网络, 能提取特征就可以, 我这里就以 VGG16 为例
为了方便表示, 我们先定义一个函数, 将卷积和池化层结合在一起, 让代码更直观一点, 里面的参数你可以自己调整
# 卷积和池化层合并层
def conv_pool(input = None, filters = 1, kernel_size = (3, 3),
dilation_rate = (1, 1), padding = "same", activation = "relu",
conv_layers = 1, pool_enable = True, normalize = False, init = None,
name = None):
if None == init:
init = keras.initializers.RandomNormal(mean = 0.0, stddev = 0.05,
seed = random.randint(0, 1024))
x = input
for i in range(max(conv_layers, 1)):
layer_name = None if None == name else name + "_" + str(i + 1)
if normalize:
x = keras.layers.Conv2D(filters = filters,
kernel_size = kernel_size,
dilation_rate = dilation_rate,
kernel_initializer = init,
padding = padding,
name = layer_name)(x)
x = keras.layers.BatchNormalization()(x)
x = keras.layers.Activation(activation)(x)
else:
x = keras.layers.Conv2D(filters = filters,
kernel_size = kernel_size,
dilation_rate = dilation_rate,
kernel_initializer = init,
padding = padding,
activation = activation,
name = layer_name)(x)
y = keras.layers.MaxPool2D(pool_size = (2, 2), strides = (2, 2))(x) if pool_enable else x
return y
有了上面的 conv_pool 函数, 定义网络会更简洁. 注意最后一个不需要 Pooling
# VGG16 卷积部分
def vgg16_conv(input_layer):
x1 = conv_pool(input_layer, 64, conv_layers = 2, name = "vgg16_x1")
x2 = conv_pool(x1, 128, conv_layers = 2, name = "vgg16_x2")
x3 = conv_pool(x2, 256, conv_layers = 3, name = "vgg16_x3")
x4 = conv_pool(x3, 512, conv_layers = 3, name = "vgg16_x4")
x5 = conv_pool(x4, 512, conv_layers = 3, pool_enable = False, name = "vgg16_x5")
return x5
上面的 vgg16_conv 看起来是不是很简单了, 但是只实现了卷积部分, 因为后面的全连接层我们不需要, Figure 2 中的 conv layers 就这样完成了, 是不是也没有那么难
2. RPN 网络
再上一图
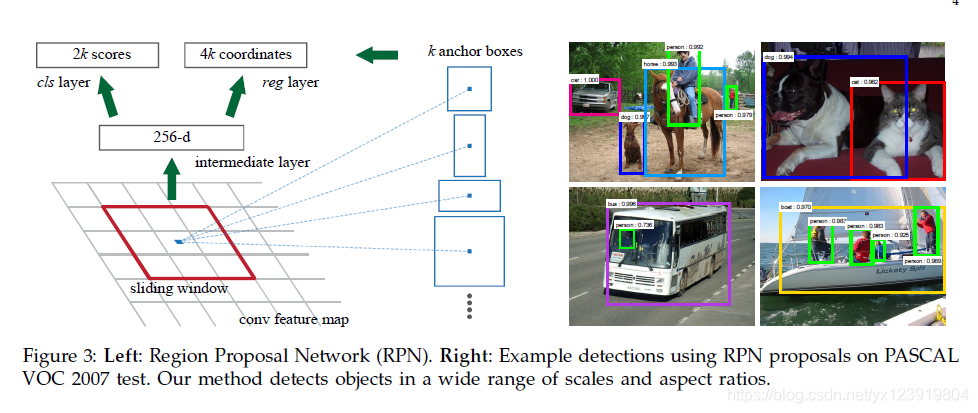
这个图相信你也是看了无数次了, 左边就是 RPN, 那个 3×3 红框表示在特征提取网络输出的结果上再来一次 3×3 卷积, 并不改变特征图的大小, 接着分道扬镳走两条路, 一条是分类(下图中红色), 一条是回归(下图中紫色)
接下来我们看上面的流程定义 RPN 网络
# RPN 网络
# feature: vgg16_conv 输出
def rpn(feature, anchors = ANCHOR_NUM):
# 这里的 filters = 512, 对应 Figure 3 中的 256-d
x = keras.layers.Conv2D(filters = 512, kernel_size = (3, 3),
padding = "same",
activation = "relu",
name = "rpn_conv")(feature)
# 未完, 下面会继续
上面的 keras.layers.Conv2D(filters = 512… 就是 Figure 3 中那个红框 3×3 卷积过程. 再下来就是分两条路 k 个 anchor 怎么操作了, 其实不一定要是 9, 如果你检测目标尺度变化不大, 也许 k 取 3 也可以的, 看你怎么设计. 为了避免误导, 我还是以 9 来讲, 先明确两个概念
- anchor: Figure 3 中那个 3×3 红框卷积后的 特征图 上的一个 点
- anchor box: 特征图上的点映射到 原图 上的一个 框
anchor box 有三种比例, 高比宽分别是 1 : 1, 1 : 2, 2 : 1. 这三种比例又分别有 3 种尺寸, 分别是 128×128, 256×256, 512×512, 组合起来就是 9 种. 为什么要这样设计呢? 是因为我们检测的目标有尺度上的变化, 高矮胖瘦也不一样. 用这样的框去"框"目标, 都比较一下, 哪种合适用哪种. 这里你也许还有一个疑问, 既然比例是 1 : 2 或者 2 : 1, 为什么尺寸还是 128×128, 256×256, 512×512 呢? 这样只是为了叙述方便, 真实的尺寸是保持面积不变, 边长按比例计算. 煮个栗子, 高宽比是 1 : 2 (矮胖的矩形), 尺寸取 256×256, 设短边为 x, 面积 s = 2 * x2 = 65536. 解得 x = 181.02. 那短边(高)为 181, 长边(宽)为 362, 就是 181×362
论文中取的 anchor box 的三种尺寸其实和缩放的最短边长度(600, 就是开始讲的配置参数的 SHORT_SIZE) 是有关系的, 最大的 anchor box 的边长和 SHORT_SIZE 差不多大, 意思就是当目标和输入图像差不多大的时候, 有一个 anchor box 差不多和目标一般大. 但是 128 的尺寸对于太小目标的检测可能会漏检
用上面讲的 9 种矩形去原图上框, 抠出来的图就是要进行筛选的候选区域或者建议区域. 其实我们不用到原图上去抠, 真正抠的是 Feature Map, 因为参与后面的分类与回归的是卷积后的特征图, 映射回原图的尺寸只是为了计算目标类别和 IoU, 而且一个 anchor 就对应了一个 anchor box 的计算特征, 不需要原图去计算了
经过 3×3 卷积后的特征图有 512 个通道, 每一个点对应 9 个 anchor, RPN 的作用是判断这些 anchor(点) 是背景还是目标, 有两种可能性, 因为这里还没有判断具体的目标类别, 只是判断是否为目标. 还要对这些 anchor box(框) 进行修正, 有 4 个修正参数, 分别是平移量 ( Δ x , Δ y ) (Δx, Δy) (Δx,Δy), 缩放系数 ( Δ w , Δ h ) (Δw, Δh) (Δw,Δh)
- ( Δ x , Δ y ) (Δx, Δy) (Δx,Δy): 表示 anchor box 离 Ground Truth 还有多远, 即 x x x 和 y y y 方向分别要移动多少才能和 Ground Truth 中心对齐
- ( Δ w , Δ h ) (Δw, Δh) (Δw,Δh): 表示 anchor 要变化到 Ground Truth 那样大, w w w 和 h h h 要缩小或者放大的倍数
每个 anchor box 需要上面这 4 个参数是因为 anchor box 不会正好框到目标, 也不会和目标一般大, 所以需要进行调整
有了上面的的知识后, 我们继续完善 RPN 网络. 分类接的是全连接层, anchor box 的回归是一个线性模型, 所以我们需要把 Feature Map 转换一下, 以适应分类和回归. 怎么转换, 用一个 1×1 的卷积核对 Figure 3 中的 Feature Map 进行卷积操作. 有同学可能会问, 1×1 去卷积不是多此一举吗, 有什么意思呢? 这个可能是你没有明白卷积的意义. 卷积后的通道数就是卷积核的个数, 用 1×1 去卷积的作用可以改变特征图的通道数, 相当于多个通道的一个线性组合(Linear Combination), 也相当于降维, 还相当于一个全连接. 论文中分类变成 2 × 9 = 18 个通道, 用的是 softmax 激活, 回归变成 4 × 9 = 36 个通道
分类每两个通道的一个点组成一个 one-hot 向量, (0, 1) 或者 (1, 0), 表示 1 个 anchor 对应的分类结果. 回归是有 36 通道的 Tensor, 每四个通道的一个点组成的 4 维向量分别表示 1 个 anchor 对应的 Δ x , Δ y , Δ w , Δ h Δx, Δy, Δw, Δh Δx,Δy,Δw,Δh. Tensor 要是不明白的话, 可以暂时理解为矩阵, 不过矩阵没有通道一说 . 不明白的话, 看下图
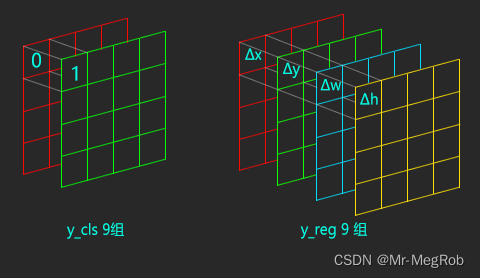
这里我们搞简单一点, 因为分类只是二分类, 所以用 sigmoid 激活就足够了, 18 个通道就变成了 9 个. 我们还要再搞简单一点, 先只实现分类的功能, 把回归部分去掉, 等分类整明白之后再来搞回归部分, 所以 RPN 网络定义如下
# RPN 网络
# feature: vgg16_conv 输出
def rpn(feature, anchors = ANCHOR_NUM):
# 这里的 filters = 512, 对应 Figure 3 中的 256-d
x = keras.layers.Conv2D(filters = 512, kernel_size = (3, 3),
padding = "same",
activation = "relu",
name = "rpn_conv")(feature)
# 下面是增加分类
y_cls = keras.layers.Conv2D(anchors * 1, kernel_size = (1, 1),
activation = "sigmoid",
kernel_initializer = "uniform",
name = "rpn_cls")(x)
return y_cls
那怎么把这上面两部分组合成一个 Model 呢? Keras 实现起来非常简单
# 组合成 rpn 模型
# 输入层, shape = (None, None, 3) 表示可接受任意大小的 3 通道图像输入
# 如果把 None 换成具体的数字, 那就只能输入指定大小的图像了
x = keras.layers.Input(shape = (None, None, 3), name = "input")
feature = vgg16_conv(x)
rpn_cls = rpn(feature)
rpn_model = keras.Model(x, rpn_cls, name = "rpn_model")
rpn_model.summary()
summary
Model: "rpn_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input (InputLayer) [(None, None, None, 3)] 0
_________________________________________________________________
vgg16_x1_1 (Conv2D) (None, None, None, 64) 1792
_________________________________________________________________
vgg16_x1_2 (Conv2D) (None, None, None, 64) 36928
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, None, None, 64) 0
_________________________________________________________________
vgg16_x2_1 (Conv2D) (None, None, None, 128) 73856
_________________________________________________________________
vgg16_x2_2 (Conv2D) (None, None, None, 128) 147584
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, None, None, 128) 0
_________________________________________________________________
vgg16_x3_1 (Conv2D) (None, None, None, 256) 295168
_________________________________________________________________
vgg16_x3_2 (Conv2D) (None, None, None, 256) 590080
_________________________________________________________________
vgg16_x3_3 (Conv2D) (None, None, None, 256) 590080
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, None, None, 256) 0
_________________________________________________________________
vgg16_x4_1 (Conv2D) (None, None, None, 512) 1180160
_________________________________________________________________
vgg16_x4_2 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
vgg16_x4_3 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, None, None, 512) 0
_________________________________________________________________
vgg16_x5_1 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
vgg16_x5_2 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
vgg16_x5_3 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
rpn_conv (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
rpn_cls_conv (Conv2D) (None, None, None, 9) 4617
=================================================================
Total params: 17,079,113
Trainable params: 17,079,113
Non-trainable params: 0
_________________________________________________________________
到这里 RPN 网络分类前向计算就完成了
五. 代码下载
示例代码可下载 Jupyter Notebook 示例代码


















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











