







 本文详细介绍了Faster-RCNN目标检测算法的原理和实现过程,包括预测部分的主干网络(Resnet)、Proposal建议框的获取与解码,以及训练部分的建议框网络和ROI网络的训练。Faster-RCNN是基于深度学习的两阶段目标检测方法,具有较高的检测精度,但速度相对较慢。
本文详细介绍了Faster-RCNN目标检测算法的原理和实现过程,包括预测部分的主干网络(Resnet)、Proposal建议框的获取与解码,以及训练部分的建议框网络和ROI网络的训练。Faster-RCNN是基于深度学习的两阶段目标检测方法,具有较高的检测精度,但速度相对较慢。
Faster-RCNN
什么是FasterRCNN目标检测算法
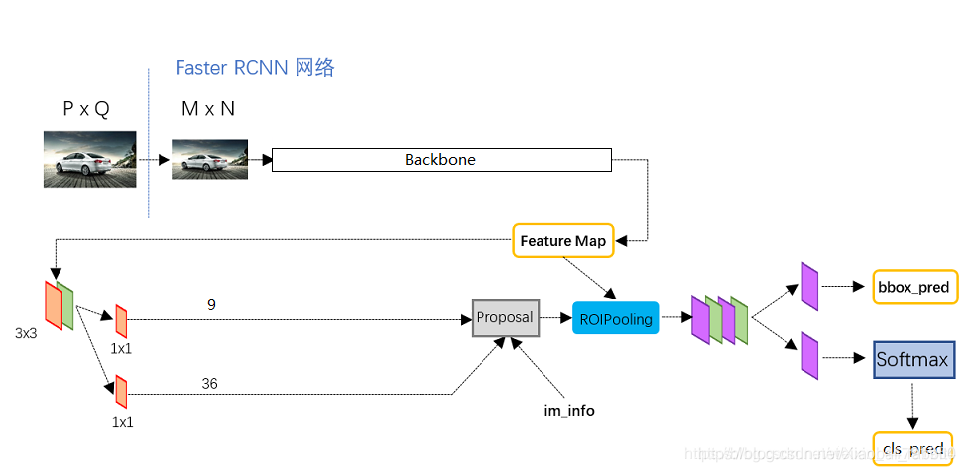
Faster-RCNN是一个非常有效的目标检测算法,虽然是一个比较早的论文, 但它至今仍是许多目标检测算法的基础。
Faster-RCNN作为一种two-stage的算法,与one-stage的算法相比,two-stage的算法更加复杂且速度较慢,但是检测精度会更高。
事实上也确实是这样,Faster-RCNN的检测效果非常不错,但是检测速度与训练速度有待提高。
Faster-RCNN实现思路
1、预测部分
1.1、主干网络介绍
Faster-RCNN可以采用多种的主干特征提取网络,常用的有VGG,Resnet,Xception等等,本文采用的是Resnet网络。
FasterRcnn对输入进来的图片尺寸没有固定,但是一般会把输入进来的图片短边固定成600,如输入一张1200x1800的图片,会把图片不失真的resize到600x900上。
ResNet50有两个基本的块,分别名为Conv Block和Identity Block,其中Conv Block输入和输出的维度是不一样的,所以不能连续串联,它的作用是改变网络的维度;Identity Block输入维度和输出维度相同,可以串联,用于加深网络的。
Conv Block的结构如下:

Identity Block的结构如下:

这两个都是残差网络结构。
Faster-RCNN的主干特征提取网络部分只包含了长宽压缩了四次的内容,第五次压缩后的内容在ROI中使用。即Faster-RCNN在主干特征提取网络所用的网络层如图所示。
以输入的图片为600x600为例,shape变化如下:

最后一层的输出就是公用特征层。
1.2、代码实现
def identity_block(input_tensor, kernel_size, filters, stage, block):
filters1, filters2, filters3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = Conv2D(filters1, (1, 1), name=conv_name_base + '2a')(input_tensor)
x = BatchNormalization(name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
x = Conv2D(filters2, kernel_size,padding='same', name=conv_name_base + '2b')(x)
x = BatchNormalization(name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
x = Conv2D(filters3, (1, 1), name=conv_name_base + '2c')(x)
x = BatchNormalization(name=bn_name_base + '2c')(x)
x = layers.add([x, input_tensor])
x = Activation('relu')(x)
return x
def conv_block(input_tensor, kernel_size, filters, stage, block, strides=(2, 2)):
filters1, filters2, filters3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = Conv2D(filters1, (1, 1), strides=strides,
name=conv_name_base + '2a')(input_tensor)
x = BatchNormalization(name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
x = Conv2D(filters2, kernel_size, padding='same',
name=conv_name_base + '2b')(x)
x = BatchNormalization(name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
x = Conv2D(filters3, (1, 1), name=conv_name_base + '2c')(x)
x = BatchNormalization(name=bn_name_base + '2c')(x)
shortcut = Conv2D(filters3, (1, 1), strides=strides,
name=conv_name_base + '1')(input_tensor)
shortcut = BatchNormalization(name=bn_name_base + '1')(shortcut)
x = layers.add([x, shortcut])
x = Activation('relu')(x)
return x
def ResNet50(inputs):
img_input = inputs
x = ZeroPadding2D((3, 3))(img_input)
x = Conv2D(64, (7, 7), strides=(2, 2), name='conv1')(x)
x = BatchNormalization(name='bn_conv1')(x)
x = Activation('relu')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x)
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1))
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')
x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f')
return x
2、获得Proposal建议框
2.1、Proposal网络介绍

获得的公用特征层在图像中就是Feature Map,其有两个应用,一个是和ROIPooling结合使用、另一个是进行一次3x3的卷积后,进行一个9通道的1x1卷积,还有一个36通道的1x1卷积。
在Faster-RCNN中,num_priors也就是先验框的数量就是9,所以两个1x1卷积的结果实际上也就是:
9 x 4的卷积 用于预测 公用特征层上 每一个网格点上 每一个先验框的变化情况。(为什么说是变化情况呢,这是因为Faster-RCNN的预测结果需要结合先验框获得预测框,预测结果就是先验框的变化情况。)
9 x 1的卷积 用于预测 公用特征层上 每一个网格点上 每一个预测框内部是否包含了物体。
当我们输入的图片的shape是600x600x3的时候,公用特征层的shape就是38x38x1024,相当于把输入进来的图像分割成38x38的网格,然后每个网格存在9个先验框,这些先验框有不同的大小,在图像上密密麻麻。
9 x 4的卷积的结果会对这些先验框进行调整,获得一个新的框。
9 x 1的卷积会判断上述获得的新框是否包含物体。
到这里我们可以获得了一些有用的框,这些框会利用9 x 1的卷积判断是否存在物体。
到此位置还只是粗略的一个框的获取,也就是一个建议框。然后我们会在建议框里面继续找东西。
2.1.1、Proposal代码实现
def get_rpn(base_layers, num_anchors):
x = Conv2D(512, (3, 3), padding='same', activation='relu', kernel_initializer='normal', name='rpn_conv1')(base_layers)
x_class = Conv2D(num_anchors, (1, 1), activation='sigmoid', kernel_initializer='uniform', name='rpn_out_class')(x)
x_regr = Conv2D(num_anchors * 4, (1, 1), activation='linear', kernel_initializer='zero', name='rpn_out_regress')(x)
x_class & 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









