









保姆级 Keras 实现 Faster R-CNN 七
上一篇文章 我们完成了只有分类功能的 RPN 网络预测, 相信到这里你已经掌握了 RPN 的 anchor 原理了. 接下来就是把 anchor box 的回归修正功能加进 RPN 网络了
一. 修改 RPN 模型结构
在 保姆级 Keras 实现 Faster R-CNN 一 中定义的 rpn 网络需要修改如下
# RPN 网络
# feature: vgg16_conv 输出
def rpn(feature, anchors = ANCHOR_NUM):
# 这里的 filters = 512, 对应 Figure 3 中的 256-d
x = keras.layers.Conv2D(filters = 512, kernel_size = (3, 3),
padding = "same",
activation = "relu",
name = "rpn_conv")(feature)
# 原有的分类部分
rpn_cls = keras.layers.Conv2D(anchors * 1, kernel_size = (1, 1),
activation = "sigmoid",
kernel_initializer = "uniform",
name = "rpn_cls")(x)
# 增加的回归部分
rpn_reg = keras.layers.Conv2D(anchors * 4, kernel_size = (1, 1),
activation = "linear",
kernel_initializer = "zero",
name = "rpn_reg")(x)
return rpn_cls, rpn_reg
上面的代码增加了回归的卷积层, 最后输出也多了一个 y_reg, 网络变成了有两个输出, rpn 修改了之后, rpn_model 也要做相应的修改
# 组合成 rpn 模型
# 输入层, shape = (None, None, 3) 表示可接受任意大小的 3 通道图像输入
# 如果把 None 换成具体的数字, 那就只能输入指定大小的图像了
x = keras.layers.Input(shape = (None, None, 3), name = "input")
feature = vgg16_conv(x)
# 两个输出
rpn_cls, rpn_reg = rpn(feature)
rpn_model = keras.Model(x, [rpn_cls, rpn_reg], name = "rpn_model")
rpn_model.summary()
Model: "rpn_model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input (InputLayer) [(None, None, None, 0
__________________________________________________________________________________________________
vgg16_x1_1 (Conv2D) (None, None, None, 6 1792 input[0][0]
__________________________________________________________________________________________________
vgg16_x1_2 (Conv2D) (None, None, None, 6 36928 vgg16_x1_1[0][0]
__________________________________________________________________________________________________
max_pooling2d (MaxPooling2D) (None, None, None, 6 0 vgg16_x1_2[0][0]
__________________________________________________________________________________________________
vgg16_x2_1 (Conv2D) (None, None, None, 1 73856 max_pooling2d[0][0]
__________________________________________________________________________________________________
vgg16_x2_2 (Conv2D) (None, None, None, 1 147584 vgg16_x2_1[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, None, None, 1 0 vgg16_x2_2[0][0]
__________________________________________________________________________________________________
vgg16_x3_1 (Conv2D) (None, None, None, 2 295168 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
vgg16_x3_2 (Conv2D) (None, None, None, 2 590080 vgg16_x3_1[0][0]
__________________________________________________________________________________________________
vgg16_x3_3 (Conv2D) (None, None, None, 2 590080 vgg16_x3_2[0][0]
__________________________________________________________________________________________________
max_pooling2d_2 (MaxPooling2D) (None, None, None, 2 0 vgg16_x3_3[0][0]
__________________________________________________________________________________________________
vgg16_x4_1 (Conv2D) (None, None, None, 5 1180160 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
vgg16_x4_2 (Conv2D) (None, None, None, 5 2359808 vgg16_x4_1[0][0]
__________________________________________________________________________________________________
vgg16_x4_3 (Conv2D) (None, None, None, 5 2359808 vgg16_x4_2[0][0]
__________________________________________________________________________________________________
max_pooling2d_3 (MaxPooling2D) (None, None, None, 5 0 vgg16_x4_3[0][0]
__________________________________________________________________________________________________
vgg16_x5_1 (Conv2D) (None, None, None, 5 2359808 max_pooling2d_3[0][0]
__________________________________________________________________________________________________
vgg16_x5_2 (Conv2D) (None, None, None, 5 2359808 vgg16_x5_1[0][0]
__________________________________________________________________________________________________
vgg16_x5_3 (Conv2D) (None, None, None, 5 2359808 vgg16_x5_2[0][0]
__________________________________________________________________________________________________
rpn_conv (Conv2D) (None, None, None, 5 2359808 vgg16_x5_3[0][0]
__________________________________________________________________________________________________
rpn_cls (Conv2D) (None, None, None, 9 4617 rpn_conv[0][0]
__________________________________________________________________________________________________
rpn_reg (Conv2D) (None, None, None, 3 18468 rpn_conv[0][0]
==================================================================================================
Total params: 17,097,581
Trainable params: 17,097,581
Non-trainable params: 0
__________________________________________________________________________________________________
rpn_model = keras.Model(x, [rpn_cls, rpn_reg], name = “rpn_model”) 这一行中的输出有两个, 用列表的形式表示. 这可能是你第一次遇到多输出的情况, 也是 Keras 多输出的语法
二. RPN 回归标签生成
在 get_ground_truth 函数中, 我们完成了分类标签生成功能, 还差回归修正的标签, 4 个修正量
(
Δ
x
,
Δ
y
)
,
(
Δ
w
,
Δ
h
)
(Δx, Δy), (Δw, Δh)
(Δx,Δy),(Δw,Δh) 是归一化的量, 也可以理解成相对值. 没有设置成绝坐标值的原因是适应位置和尺度变化

如上图, 左边和右边是同一个图像不同尺寸的状态, 理论上修正的 相对值 是相同的, 比如向右移动 anchor box 宽度的 1/5, 再将 anchor box 高度放大 1.1 倍. 那两张图像的修正量是相同的. 如果是绝对坐标的话, 右边的
x
x
x 修正值就会比左边大, 造成网络学习修正参数时不容易收敛
在 保姆级 Keras 实现 Faster R-CNN 三 中已经有判断 anchor box 是正样本还是负样本, 如果是正样本就要给它一个修正值的标签. 其他的样本就随它去吧. 这 4 个修正值怎么计算呢?
- ( Δ x , Δ y ) (Δx, Δy) (Δx,Δy): 表示 anchor box 离 Ground Truth 还有多远, 即 x x x 和 y y y 方向分别要移动多少才能和 Ground Truth 中心对齐
- ( Δ w , Δ h ) (Δw, Δh) (Δw,Δh): 表示 anchor 要变化到 Ground Truth 那样大, w w w 和 h h h 要缩小或者放大的倍数
按论文上的公式有:
Δ
x
∗
=
(
x
∗
−
x
a
)
/
w
a
Δ
y
∗
=
(
y
∗
−
y
a
)
/
h
a
Δ
w
∗
=
l
n
(
w
∗
/
w
a
)
Δ
h
∗
=
l
n
(
h
∗
/
h
a
)
\begin{aligned} Δx^* &= (x^* - x_a) / w_a \\ Δy^* &= (y^* - y_a) / h_a \\ Δw^* &= ln(w^* / w_a) \\ Δh^* &= ln(h^* / h_a) \end{aligned}
Δx∗Δy∗Δw∗Δh∗=(x∗−xa)/wa=(y∗−ya)/ha=ln(w∗/wa)=ln(h∗/ha)
x
∗
x^*
x∗: Ground Truth 中心横坐标
y
∗
y^*
y∗: Ground Truth 中心纵坐标
w
∗
w^*
w∗: Ground Truth 宽
h
∗
h^*
h∗: Ground Truth 高
x
a
x_a
xa: anchor box 中心横坐标
y
a
y_a
ya: anchor box 中心纵坐标
w
a
w_a
wa: anchor box 宽
h
a
h_a
ha: anchor box 高
Δ x ∗ , Δ y ∗ , Δ w ∗ , Δ h ∗ Δx^*, Δy^*, Δw^*, Δh^* Δx∗,Δy∗,Δw∗,Δh∗ 就是回归修正量的 g r o u n d ground ground t r u t h truth truth
( x ∗ − x a ) / w a (x^* - x_a) / w_a (x∗−xa)/wa 和 ( y ∗ − y a ) / h a (y^* - y_a) / h_a (y∗−ya)/ha 除以 w a w_a wa 和 h a h_a ha 的目的就是归一化, 可以将标签值控制在 [-1, 1] 区间
l n ( w ∗ / w a ) ln(w^* / w_a) ln(w∗/wa) 和 l n ( h ∗ / h a ) ln(h^* / h_a) ln(h∗/ha) 取对数的原因是 anchor box 和 ground truth 比较接近时可看成是线性模型来处理. 两个一样大的时候修正量正好为 0, 从 l n ( x ) ln(x) ln(x) 的函数图像就可以看出来
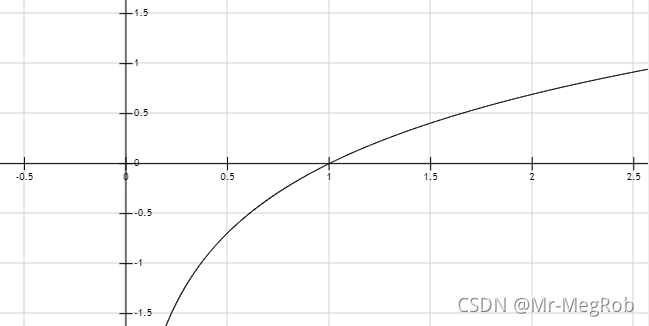
同样也可以将标签值控制在 [-1, 1] 区间. 将标签值限制在 [-1, 1] 对训练收敛是很有帮助的
Δ x , Δ y , Δ w , Δ h Δx, Δy, Δw, Δh Δx,Δy,Δw,Δh 本身就是回归修正量的 预测值, 就是 RPN 的输出了. 所以不需要再做什么变换, 只有反推建议框时才需要做逆运算. 后面会讲
有了上面的公式之后, 我们就用函数来做标签了
# 生成 rpn anchor box 修正量标签
# 只有类别为目标的 anchor box 才参数修正
# anchors: 由 create_train_anchors 函数生成的 anchor_box
# cls_labels: get_rpn_cls_label 生成的类别标签列表
# gt_boxes: get_rpn_cls_label 返回的对应的 ground_truth
# 返回每一个 anchor box 修正量 Δx, Δy, Δw, Δh
REG_NO_TRAIN = 8.0 # 用于不参加训练判断的常量, 标签的值范围是 [0, 1]
def get_rpn_reg_label(anchors, cls_labels, gt_boxes):
reg_lables = [REG_NO_TRAIN] * len(cls_labels) * 4 # 初始化为 REG_NO_TRAIN, 方便后面判断
for i, a in enumerate(anchors):
if cls_labels[i] != POS_VAL:
continue
w_a = a[2] - a[0] # anchor_box 宽
h_a = a[3] - a[1] # anchor_box 高
a_center_x = (a[0] + a[2]) * 0.5
a_center_y = (a[1] + a[3]) * 0.5
gt = gt_boxes[i]
w_g = gt[2] - gt[0] # gt 宽
h_g = gt[3] - gt[1] # gt 高
g_center_x = (gt[0] + gt[2]) * 0.5
g_center_y = (gt[1] + gt[3]) * 0.5
reg_lables[(i << 2) + 0] = (g_center_x - a_center_x) / w_a
reg_lables[(i << 2) + 1] = (g_center_y - a_center_y) / h_a
reg_lables[(i << 2) + 2] = math.log(float(w_g) / w_a)
reg_lables[(i << 2) + 3] = math.log(float(h_g) / h_a)
return reg_lables
上面的代码中直接用到了 gt_boxes, 这是 get_rpn_cls_label 函数返回的. 在打类别标签的时候既然就已经知道了 anchor box 所对应的 ground truth, 所以保存起来让 get_rpn_reg_label 直接使用就可以了, 灰常方便. 除了正标签, 其他的回归修正值都初始化为 REG_NO_TRAIN, 方便损失函数判断. 下面还是用飞机那张图来测试, 红色是 anchor box, 绿色是 ground_truth
# 测试 get_rpn_reg_label 函数
rpn_reg_label = get_rpn_reg_label(anchors, rpn_cls_label, gt_boxes)
label = []
for reg in rpn_reg_label:
if REG_NO_TRAIN != reg:
label.append(reg)
if len(label) == 4:
print(label)
label = []

[-0.09375, 0.0625, -0.09844007281325252, -0.0317486983145803]
[0.125, 0.0, -0.09844007281325252, -0.06453852113757118]
[-0.125, 0.0, -0.09844007281325252, -0.06453852113757118]
[-0.0390625, -0.0234375, -0.1158318155251217, -0.048009219186360606]
[-0.0078125, 0.0625, -0.0813456394539524, -0.13353139262452263]
[-0.015625, -0.078125, -0.09844007281325252, -0.16989903679539747]
[-0.03125, -0.09375, -0.13353139262452263, -0.16989903679539747]
输出值都能对上
三. 修改数据增强函数
现在有了生成回归标签的功能了, 那之前的数据增强函数也要把这部分加进去, 修改如下
# 数据增强函数, 包括左右, 上下, 左右上翻转
# data_pair: data_set_path 返回的数据元素
# train_num: 一次参数训练的 anchor 的数量
# 返回增强后的图像和标签
def data_augment(data_pair, train_num):
augmented = [] # 返回增强后的数据
img_src = cv.imread(data_pair[0])
img_new, scale = new_size_image(img_src, SHORT_SIZE)
feature_size = (img_new.shape[0] // FEATURE_STRIDE, img_new.shape[1] // FEATURE_STRIDE)
anchors = create_train_anchors(feature_size, base_anchors, FEATURE_STRIDE)
# 原始图像与标签------------------------------------------------------
ground_truth = get_ground_truth(data_pair[1], data_pair[2], CATEGORIES)
# ground_truth 要做相应的缩放
for gt in ground_truth:
gt[0][0] = round(gt[0][0] * scale)
gt[0][1] = round(gt[0][1] * scale)
gt[0][2] = round(gt[0][2] * scale)
gt[0][3] = round(gt[0][3] * scale)
rpn_cls_label, gt_boxes = get_rpn_cls_label(img_new.shape, anchors,
ground_truth, train_num = train_num)
# 增加的回归标签
rpn_reg_label = get_rpn_reg_label(anchors, rpn_cls_label, gt_boxes)
# 返回 gt_boxes 修改为 rpn_reg_label
augmented.append([img_new, rpn_cls_label, rpn_reg_label])
# 原始图像与标签------------------------------------------------------
# 左右翻转与标签------------------------------------------------------
# 复制一份,后面的操作在备份上操作
gt_copy = copy.deepcopy(ground_truth)
x_flip = cv.flip(img_new, 1) # 左右翻转图像
for gt in gt_copy: # 左右翻转标签
gt[0][0] = x_flip.shape[1] - 1 - gt[0][0]
gt[0][2] = x_flip.shape[1] - 1 - gt[0][2]
gt[0][0], gt[0][2] = gt[0][2], gt[0][0]
rpn_cls_label, gt_boxes = get_rpn_cls_label(x_flip.shape, anchors,
gt_copy, train_num = train_num)
# 增加的回归标签
rpn_reg_label = get_rpn_reg_label(anchors, rpn_cls_label, gt_boxes)
# 返回 gt_boxes 修改为 rpn_reg_label
augmented.append([x_flip, rpn_cls_label, rpn_reg_label])
# 左右翻转与标签------------------------------------------------------
# 上下翻转与标签------------------------------------------------------
# 复制一份,后面的操作在备份上操作
gt_copy = copy.deepcopy(ground_truth)
y_flip = cv.flip(img_new, 0) # 左右翻转图像
for gt in gt_copy: # 上下翻转标签
gt[0][1] = y_flip.shape[0] - 1 - gt[0][1]
gt[0][3] = y_flip.shape[0] - 1 - gt[0][3]
gt[0][1], gt[0][3] = gt[0][3], gt[0][1]
rpn_cls_label, gt_boxes = get_rpn_cls_label(y_flip.shape, anchors,
gt_copy, train_num = train_num)
# 增加的回归标签
rpn_reg_label = get_rpn_reg_label(anchors, rpn_cls_label, gt_boxes)
# 返回 gt_boxes 修改为 rpn_reg_label
augmented.append([y_flip, rpn_cls_label, rpn_reg_label])
# 上下翻转与标签------------------------------------------------------
# 左右上下翻转与标签--------------------------------------------------
# 复制一份,后面的操作在备份上操作
gt_copy = copy.deepcopy(ground_truth)
xy_flip = cv.flip(img_new, -1) # 左右翻转图像
for gt in gt_copy: # 左右上下翻转标签
gt[0][0] = xy_flip.shape[1] - 1 - gt[0][0]
gt[0][1] = xy_flip.shape[0] - 1 - gt[0][1]
gt[0][2] = xy_flip.shape[1] - 1 - gt[0][2]
gt[0][3] = xy_flip.shape[0] - 1 - gt[0][3]
gt[0][0], gt[0][2] = gt[0][2], gt[0][0]
gt[0][1], gt[0][3] = gt[0][3], gt[0][1]
rpn_cls_label, gt_boxes = get_rpn_cls_label(xy_flip.shape, anchors,
gt_copy, train_num = train_num)
# 增加的回归标签
rpn_reg_label = get_rpn_reg_label(anchors, rpn_cls_label, gt_boxes)
# 这里原来返回 gt_boxes, 现在修改为 rpn_reg_label
augmented.append([xy_flip, rpn_cls_label, rpn_reg_label])
# 左右上下翻转与标签--------------------------------------------------
return augmented
以上代码修改的部分有注释, 就不多解释了, 因为修改了返回值, 所以测试的函数也要做相应的修改. 只是注释掉原来和 gt_boxes 相关的部分
# 测试 data_augment
titles = ["original", "x_filip", "y_flip", "xy_flip"]
plt.figure("augmented", figsize = (12, 8))
print(train_set[idx])
augmented = data_augment(train_set[idx], train_num = 32)
for i, data in enumerate(augmented):
img_copy = data[0].copy()
feature_size = (img_copy.shape[0] // FEATURE_STRIDE, img_copy.shape[1] // FEATURE_STRIDE)
anchors = create_train_anchors(feature_size, base_anchors, FEATURE_STRIDE)
for j, a in enumerate(anchors):
if POS_VAL == data[1][j]:
# 这里原来显示 gt 的部分也要注释掉, 因为 data_augment 不再返回 gt_boxes
# gt = data[2][j]
# 测试 get_rpn_cls_label 带出来的 gt 是否正确
# cv.rectangle(img_copy, (gt[0], gt[1]), (gt[2], gt[3]), (255, 55, 55), 2)
cv.rectangle(img_copy, (a[0], a[1]), (a[2], a[3]), (0, 255, 0), 2)
elif NEG_VAL == data[1][j]:
cv.rectangle(img_copy, (a[0], a[1]), (a[2], a[3]), (0, 0, random.randint(128, 256)), 1)
plt.subplot(2, 2, i + 1)
plt.title(titles[i], color = 'gray')
plt.imshow(img_copy[..., : : -1]) # 这里的通道要反过来显示才正常
plt.show()

四. 修改读入训练数据 Generator
同理, 读入训练数据 Generator 也要修改
# 网络输入数据 generator
# data_set: 训练或测试数据列表
# categories: 类别列表
# train_num: 参加训练的 anchor 的数量
# batch_size: 一次输入训练的图像数量
# augment_fun: 数据增强函数
# train_mode: True: 训练模式, False: 测试模式
# shuffle_enable: 打乱标记
# 返回图像和标签
def input_reader(data_set, categories, batch_size = 1, train_num = TRAIN_NUM,
augment_fun = None, train_mode = True, shuffle_enable = True):
assert(isinstance(data_set, tuple) or isinstance(data_set, list))
stop_now = False
data_nums = len(data_set)
index_list = [x for x in range(data_nums)] # 用这个列表序号来打乱 data_set 排序
x = [] # 返回图像
rpn_cls = [] # 返回分类标签
rpn_reg = [] # 增加部分, 返回回归标签
max_rows = 0 # 记录一个 batch 中图像的最大行数
max_cols = 0 # 记录一个 batch 中图像的最大列数
while False == stop_now:
if train_mode and shuffle_enable:
shuffle(index_list)
for i in index_list:
is_with_label = 3 == len(data_set[i]) # 如果 3 == data_set[i], 表示带标签输入, 否则只有图像
data_list = [] # 图像与标签 list
if is_with_label:
if augment_fun and train_mode:
data_list.extend(augment_fun(data_set[i], train_num))
else:
# 这里的代码和 augment_fun 中的开始部分一样, 就不解释了
img_src = cv.imread(data_set[i][0])
img_new, scale = new_size_image(img_src, SHORT_SIZE)
feature_size = (img_new.shape[0] // FEATURE_STRIDE, img_new.shape[1] // FEATURE_STRIDE)
anchors = create_train_anchors(feature_size, base_anchors, FEATURE_STRIDE)
ground_truth = get_ground_truth(data_set[i][1], data_set[i][2], CATEGORIES)
for gt in ground_truth:
gt[0][0] = round(gt[0][0] * scale)
gt[0][1] = round(gt[0][1] * scale)
gt[0][2] = round(gt[0][2] * scale)
gt[0][3] = round(gt[0][3] * scale)
rpn_cls_label, gt_boxes = get_rpn_cls_label(img_new.shape, anchors,
ground_truth, train_num = train_num)
rpn_reg_label = get_rpn_reg_label(anchors, rpn_cls_label, gt_boxes)
data_list.append([img_new, rpn_cls_label, rpn_reg_label])
else:
train_mode = False
img_src = cv.imread(data_set[i])
img_new, scale = new_size_image(img_src, SHORT_SIZE)
data_list.append([img_new, [], []]) # 为了保持和时候相同的形状
for data in data_list:
x.append(data[0])
rpn_cls.append(data[1])
rpn_reg.append(data[2])
max_rows = max(max_rows, x[-1].shape[0])
max_cols = max(max_cols, x[-1].shape[1])
if len(x) >= batch_size:
# 一个 batch 中图像的尺寸不一样是不能一起训练的, 所以要将其统一到相同的尺寸
# 行数小于最大行数在图像下方填充 0, 列数小于最大列数在图像右方填充 0
# 图像填充的同时标签也要填充
new_shape = (max_rows // FEATURE_STRIDE, max_cols // FEATURE_STRIDE)
for j, img in enumerate(x):
# 原图对应的特征图尺寸
old_shape = (img.shape[0] // FEATURE_STRIDE, img.shape[1] // FEATURE_STRIDE)
# 这里 = 号前要用 x[j] 不能用 img, 因为要改变 x[j], img 只是一个副本
x[j] = cv.copyMakeBorder(img,
0, max_rows - img.shape[0], 0, max_cols - img.shape[1],
cv.BORDER_CONSTANT, (0, 0, 0))
if is_with_label:
# 行方向填充数据
if new_shape[0] - old_shape[0] > 0:
pad_num = (new_shape[0] - old_shape[0]) * old_shape[1] * ANCHOR_NUM
y_pad = [NEUTRAL] * pad_num
rpn_cls[j].extend(y_pad)
# 增加的回归标签, 回归标签也要进行填充
y_pad = [REG_NO_TRAIN] * pad_num * 4
rpn_reg[j].extend(y_pad)
# 列方向填充
# 行方向时直接加在末尾, 而列方向是不连续的, 所以一行一行加在末尾
if new_shape[1] - old_shape[1] > 0:
pad_pos = old_shape[1] * ANCHOR_NUM
pad_num = (new_shape[1] - old_shape[1]) * ANCHOR_NUM
y_pad = [NEUTRAL] * pad_num
for r in range(new_shape[0]):
# 这里不能用 insert 函数, insert 会把 y_pad 整体当成一个元素
rpn_cls[j][pad_pos: pad_pos] = y_pad
pad_pos += (pad_num + old_shape[1] * ANCHOR_NUM)
# 增加的回归标签
pad_pos = old_shape[1] * ANCHOR_NUM * 4
pad_num = (new_shape[1] - old_shape[1]) * ANCHOR_NUM * 4
y_pad = [REG_NO_TRAIN] * pad_num
for r in range(new_shape[0]):
# 这里不能用 insert 函数, insert 会把 y_pad 整体当成一个元素
rpn_reg[j][pad_pos: pad_pos] = y_pad
pad_pos += (pad_num + old_shape[1] * ANCHOR_NUM * 4)
# 返回数据
x = np.array(x).astype(np.float32) / 255.0
rpn_cls = np.array(rpn_cls).astype(np.float32)
if is_with_label:
rpn_cls = rpn_cls.reshape((-1, new_shape[0], new_shape[1], ANCHOR_NUM))
# 增加的回归标签
rpn_reg = np.array(rpn_reg)
if is_with_label:
rpn_reg = rpn_reg.reshape((-1, new_shape[0], new_shape[1], ANCHOR_NUM * 4))
yield x, (rpn_cls, rpn_reg) # 增加的回归标签
x = []
rpn_cls = []
rpn_reg = [] # 增加的回归标签
max_rows = 0
max_cols = 0
if False == train_mode:
stop_now = True
改完之后测试是否正确
# 测试 input_reader
# 这里设置成 32 方向显示, 要不然密密麻麻的框
show_reader = input_reader(train_set, CATEGORIES, batch_size = 8, train_num = 32, augment_fun = data_augment)
因为 Generator 的返回有增加回归标签, 所以下面测试 next 也要修改, 要接收回归标签
# 测试 input_reader
# 返回值增加回归标签
x, (y_cls, y_reg) = next(show_reader)
batch_size = x.shape[0]
print("train image shape: ", x.shape)
print("label shape: ", y_cls.shape, y_reg.shape) # 显示两个标签 shape
SHOW_COLUMNS = 4
SHOW_ROWS = max(1, batch_size // SHOW_COLUMNS) + 1
plt.figure("batch_images", figsize = (12, SHOW_ROWS * 3))
for i in range(batch_size):
feature_size = (x[0].shape[0] // FEATURE_STRIDE, x[0].shape[1] // FEATURE_STRIDE)
anchors = create_train_anchors(feature_size, base_anchors, FEATURE_STRIDE)
if 0 == i:
print("\nanchrors in single image: ", len(anchors))
positives = 0
# 以下的 y 需要改成 y_cls
idxs = tf.where(K.not_equal(y_cls[i], NEUTRAL))
for idx in idxs:
idx = (i, int(idx[0]), int(idx[1]), int(idx[2]))
rgb = (0, 255, 0) if POS_VAL == y_cls[idx] else (0, 0, 255)
positives = positives + 1 if POS_VAL == y_cls[idx] else positives
idx = int(idx[1] * feature_size[1] * ANCHOR_NUM + idx[2] * ANCHOR_NUM + idx[3])
a = anchors[idx]
cv.rectangle(x[i], (a[0], a[1]), (a[2], a[3]), rgb, 2)
plt.subplot(SHOW_ROWS, SHOW_COLUMNS, i + 1)
plt.title("positive = " + str(positives), color = 'gray')
plt.imshow(x[i][..., : : -1])
plt.show()
train image shape: (8, 356, 450, 3)
label shape: (8, 22, 28, 9) (8, 22, 28, 36)
anchrors in single image: 5544

五. RPN Loss Function
分类的损失函数在 保姆级 Keras 实现 Faster R-CNN 五 中已经完成了. RPN 网络有两个输出, 一个是分类, 另一个是回归, 所以需要有两个损失函数. 先把论文中的公式抄下来
L
(
{
p
i
,
t
i
}
)
=
1
N
c
l
s
∑
i
L
c
l
s
(
p
i
,
p
i
∗
)
+
λ
1
N
r
e
g
∑
i
p
i
∗
L
r
e
g
(
t
i
,
t
i
∗
)
L(\left \{{p_i, t_i}\right \}) = \frac{1}{N_{cls}}\sum_{i}^{}L_{cls}(p_i, p^*_i)+\lambda\frac{1}{N_{reg}}\sum_{i}^{}p^*_iL_{reg}(t_i, t^*_i)
L({pi,ti})=Ncls1i∑Lcls(pi,pi∗)+λNreg1i∑pi∗Lreg(ti,ti∗)
上面公式就是总的损失函数,
N
N
N 表示 mini-batch 的数量.
t
i
,
t
i
∗
t_i, t^*_i
ti,ti∗ 分别是
(
Δ
x
,
Δ
y
,
Δ
w
,
Δ
h
)
,
(
Δ
x
∗
,
Δ
y
∗
,
Δ
w
∗
,
Δ
h
∗
)
(Δx, Δy, Δw, Δh), (Δx^*, Δy^*, Δw^*, Δh^*)
(Δx,Δy,Δw,Δh),(Δx∗,Δy∗,Δw∗,Δh∗)
前半部分是二分类损失函数, 已经完成, 所以不用多讲. + + + 号后面部分是回归的损失, 有三个地方要注意
- λ \lambda λ 用来平衡两个损失的, 不至于一个损失向一边倒, 或者说哪个更重要. 作者取 λ = 10 \lambda=10 λ=10. 但是这个值貌似不重要, 对结果影响不大
- 在回归损失部分中间夹了个 p i ∗ p^*_i pi∗, 这个是分类的标签, 意思是如果是正样本, 那 p i ∗ = 1 p^*_i = 1 pi∗=1, 不会影响计算结果, 如果是负样本 p i ∗ = 0 p^*_i = 0 pi∗=0, 导致 + + + 号后面的回归损失为 0. 说白一点就是负样本不参与回归训练
-
L
r
e
g
(
t
i
,
t
i
∗
)
L_{reg}(t_i, t^*_i)
Lreg(ti,ti∗) 用的是
s
m
o
o
t
h
L
1
smooth\,L_1
smoothL1 损失, 这样做的目的是让损失函数不要对离 Ground Truth 太远(异常) 的 anchor box 太过于敏感, 太近又不要太反应迟钝. 按作者的话讲就是更 Robust, 我还是把它的公式写一下吧
S m o o t h L 1 = { 0.5 x 2 ∣ x ∣ ≤ 1 ∣ x ∣ − 0.5 o t h e r w i s e Smooth \,L1 = \left\{\begin{matrix} 0.5x^2\quad \,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,|x| \leq 1 \\|x|-0.5\quad otherwise \end{matrix}\right. SmoothL1={0.5x2∣x∣≤1∣x∣−0.5otherwise
现在可以用代码实现损失函数了
# RPN_网络回归损失失函数
def rpn_reg_loss(y_true, y_pred):
# 这里的 mask 同分类损失函数中的 mask 的作用
# 标签的值范围是 [0, 1], 所以可以用 y_true < REG_NO_TRAIN 来判断
mask = tf.cast(y_true < REG_NO_TRAIN, dtype = tf.float32)
offset = mask * K.abs(y_true - y_pred)
less_than_1 = tf.cast(offset <= 1.0, dtype = tf.float32)
loss = K.sum(less_than_1 * 0.5 * offset ** 2 +
(1 - less_than_1) * (offset - 0.5)) / (1e-6 + K.sum(mask))
return loss
rpn_reg_loss 函数中的 mask 的作用就相当于回归损失部分中间夹的那个
p
i
∗
p^*_i
pi∗ 的作用
同样也需要一个评价函数来看一下回归的精度
# 回归精度评价函数
def rpn_reg_acc(y_true, y_pred):
mask = tf.cast(y_true < REG_NO_TRAIN, dtype = tf.float32)
offset = mask * K.abs(y_true - y_pred)
ofst_true = mask * K.abs(y_true)
acc = 1 - K.sum(offset) / (1e-6 + K.sum(ofst_true))
return acc
评价函数中, 当预测值和标签值一样时, offset 元素全为 0, 这时, acc = 1
六. 模型编译
修改了输出个数, 并增加了损失函数, 编译也要修改才行
# 编译模型
rpn_model.compile(optimizer = keras.optimizers.Adam(learning_rate = 0.0001),
loss = [rpn_cls_loss, rpn_reg_loss],
loss_weights = [1.0, 10.0],
metrics = { "rpn_cls": rpn_cls_acc, "rpn_reg": rpn_reg_acc})
现在, loss 变成了一个列表, loss_weights 中的值就是 L o s s F u n c t i o n Loss Function LossFunction 中的分类损失和回归损失所占的比重 λ \lambda λ, metrics 中用一个字典来指明分类和损失所使用的评价函数
七. 训练
训练的话, 还是和原来相同
# 训练模型
project_name = "faster_rcnn"
epochs = 64
batch_size = 8
augment = AUGMENT_NUM # 一张图像增强后的图像数量, 这里是 4
train_reader = input_reader(train_set, CATEGORIES, batch_size = batch_size, augment_fun = data_augment)
valid_reader = input_reader(valid_set, CATEGORIES, batch_size = batch_size, augment_fun = data_augment)
history = rpn_model.fit(train_reader,
steps_per_epoch = len(train_set) * augment // batch_size,
epochs = epochs,
verbose = 1,
validation_data = valid_reader,
validation_steps = max(1, len(valid_set) * augment // batch_size),
max_queue_size = 8,
workers = 1)
Train for 2004 steps, validate for 250 steps
Epoch 1/64
80/2004[==>...........................] - ETA: 18:36 - loss: 2.1885 - rpn_cls_loss: 1.4361 -
rpn_reg_loss: 0.0752 - rpn_cls_rpn_cls_acc: 0.9072 - rpn_reg_rpn_reg_acc: -0.8390
可以看出, 总的 Loss = rpn_cls_loss + rpn_reg_loss × 10
上面的代码和步骤逻辑上没有毛病, 但是这样训练的话 Loss 下降得很慢, 还有比较大的概率 Loss 会卡住不下降, 这时 rpn_cls_rpn_cls_acc 维持在 0.95 左右, rpn_reg_rpn_reg_acc 保持在 0 附近, 就和胡猜乱猜差不多. 下一篇 讲如何破这两个问题
八. 代码下载
示例代码可下载 Jupyter Notebook 示例代码
上一篇: 保姆级 Keras 实现 Faster R-CNN 六
下一篇: 保姆级 Keras 实现 Faster R-CNN 八















 8609
8609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











