







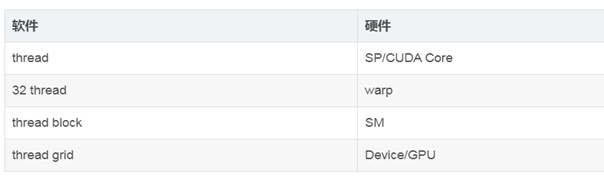
软硬件的对应关系
1. sp
是GPU的最小的硬件单元,对应的是CUDA core,软件上对应的是一个thread。
2. sm
是一个独立的CPU core,GPU的并行性由sm决定,一个sm包含的是:
CUDA cores
Shared Memory/L1Cache
Register File
Load/Store Units
Special Function Units
Warp Scheduler
每个sm中设计的是数以百计的线程并行执行
每个GPU都包含很多的sm,所以每个GPU支持很多的线程并发执行。
大量的thead会被分配到不同的sm,但时同一个block中的thread必然在一个sm中执行。
其实啊,并不是所有的线程都在同一时刻进行执行,因为NVIDIA会把32个threads组成一个warp,warp才是调动和运行的基本单元,warp中所有的线程sp才会执行相同的指令,一个warp占用一个SM,多个warp会轮流的进入sm。目前的sm包含的是32个thread。所以一个GPU上最多有sm*warp个 resident thread。
CUDA的并发性
硬件上:
cuda将问题分解成线程块的网格,每块包含多个线程,块可以按顺序尽心执行,不过再每个时间节点上,只有一部分的快处于执行中,GPU一次执行的是N个SM,如果一个快进入了这个N个sm中,就必须从开始到结束一直进行下去,网格中的块是可以分配到任意的空闲的sm上的,采用的是“轮询调度”,确保分配到每个sm的块数相同,大部分的内核程序而言,分块的数量最好是GPU总物理sm数量的8倍或者更多倍。
GPU-sm-warp-core/sp(一个GPU执行的是多个sm。一个sm执行的是多个warp,一个warp对应的是32个thread。)
软件上:
最小的逻辑单位是thread,最小的执行单位是warp,一个warp包含的是32个sp 。所以最好按照这个数目组织thread。否则硬件上有些sp是不工作的,在软件上,grid-block-(一个快里面的线程又是32个组成一个束)-thread。所以并行计算的时候尽量是32的倍数,不然假设是1,那么就会有1个在执行,31个处于静默状态。
warp:GPU执行程序时的调度单位,目前cuda的warp的大小为32,同在一个warp的线程,以不同数据资源执行相同的指令,这就是所谓 **SIMT。
**
notice,把所有的概念重新理一遍
-
线程:thread
一般由GPU的一个核进行处理
线程块 -
线程块
多个线程组成
block是并行执行的,没有执行顺序
线程块的数量最大不超过65535
每个快里面包含的线程数可以看到,tesla p4 是1024 -
线程网格
一个网格是有很多的块组成的 -
线程束
是包含32个线程的集合,线程束的每个线程都是在不同的数据集上执行相同的指令。
硬件来看: -
sp: 最基本的
最基本的处理单元,GPU并行计算就是很多的sp并行的处理 -
sm
多个sp加上一些其他的单元,也叫做GPU大核,资源的有限限制了并行能力。
软件来看 -
thread
一个cuda的并行程序可以有多个thread并行执行 -
block
数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过share memory通信 -
grid 多个blocks会被在构成grid
10.warp :GPU执行程序的调度单位,目前的cuda测warp的大小是32,同在一个warp的线程,不同的数据资源执行相同的的指令,就是simt
提出问题 -
既然block限制的是65535,一个block限制的是1024个thread。一个GPU全局内存里面是多个block组成的gird,那么为什么还要分成那么多的块和线程呢?
答:其实一个gpu程序执行的过程是调用多个sm执行的,sm的数量也是有限制的,每个sm中有很多的线程,每32个线程才会组成一个warp并发的执行,所以,一个kernal启动的时候,这些线程就会分配到多个sm中执行,其实一块GPU上residentthread最多有SM*warp个。
同一个block里面的thread必然在同一个sm中执行。
分条 / 分块
CUDA提供的简单二维网格模型。对于很多问题,这样的模型就足够了。如果在一个块内,你的工作是线性分布的,那么你可以很好地将其他分解成CUDA块。由于在一个SM内,最多可以分配16个块,而在一个GPU内有16个(有些是32个)SM,所以问题分成256个甚至更多的块都可以。实际上,我们更倾向于把一个块内的元素总数限制为128、256、或者512,这样有助于在一个典型的数据集内划分出更多数量的块。
参考文献
https://blog.csdn.net/s_sunnyy/article/details/58605805
https://www.jianshu.com/p/983e9a516522
https://www.jianshu.com/p/983e9a516522
https://blog.csdn.net/s_sunnyy/article/details/58605805















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









