







1,GRU cell 结构
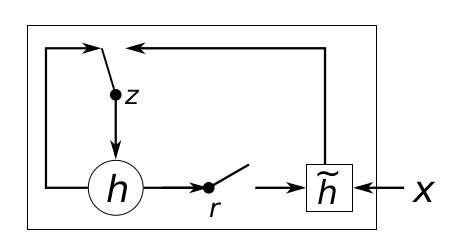
上图中z表示更新门,r重置门,h表示隐藏层状态,X表示输入, ̃h 表示加入到当前状态的候选值
更新门z的计算如下:
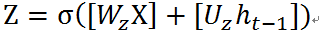
计算出来的Z值在0到1之间,表示前一个时刻的状态信息传递到当前状态的尺度,或者说是比率。这个比率值由前一个时刻t-1的状态和当前的输入X共同决定。前一个时刻的状态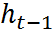
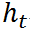
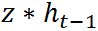
那既然之前的状态的信息量不会都传递到当前状态,那么总有丢失的信息,那丢失的比率就应该是 (1-Z)。举个例子:
输入为X=[1 2 3 1] (未考虑batch的情况),是一个矢量,特征维度是4。它可以是音频的一帧数据;或者是一帧图像中一行像素点的个数;或者是一个汉字经过embedding 后的代表该字的特征向量
前一个时刻t的状态
Z=[0.1 0.2 0.1 0.3 0.5 0.0] (Z的维度一定等于hidden_size)
那么前一个状态
既然有遗忘过去状态中信息,那么就应该有新的信息添加到当前状态中,GRU和LSTM不同的一点是 新的信息是加在前一个状态中信息被遗忘的位置,也就是用新的信息替代被遗忘的信息,假设当前状态
每一个神经元单元都有激活函数,可以是sigmoid,tanh,relu。下面GRU代码中选择的激活函数是tanh,输入值X和前一个时刻的状态值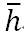
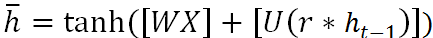
这里就涉及到重置门r
重置门的计算公式如下:
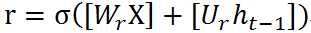
r的含义表示 前一个时刻的状态信息有多少参与到生成新的状态
最后包含历史状态信息
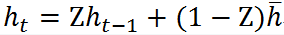
总结:当前状态
2,此代码来源于tensorflow rnn_cell中Class GRUCell(RNNCell)
#-*- coding: utf-8 -*-
from __future__ import absolute_import
from __future__ import division
from tensorflow.python.ops.math_ops import tanh
from tensorflow.python.ops.math_ops import sigmoid
from tensorflow.python.ops import variable_scope as vs
from tensorflow.python.platform import tf_logging as logging
import tensorflow as tf
from tensorflow.python.ops import array_ops
from tensorflow.python.ops import init_ops
from tensorflow.python.ops import math_ops
from tensorflow.python.util import nest
class GRUCell():
def __init__(self, num_units, input_size=None, activation=tanh):
if input_size is not None:
logging.warn("%s: The input_size parameter is deprecated.", self)
self._num_units = num_units
self._activation = activation
@property
def state_size(self):
return self._num_units
@property
def output_size(self):
return self._num_units
def __call__(self, inputs, state, scope=None):
with vs.variable_scope(scope or type(self).__name__): # "GRUCell"
with vs.variable_scope("Gates"): # Reset gate and update gate.
#计算reset gate 和update gate
#对应着公式(1)和(4)
r, u = array_ops.split(1, 2, _linear([inputs, state],2 * self._num_units, True, 1.0))
r, u = sigmoid(r), sigmoid(u)
#对应着公式(3)
with vs.variable_scope("Candidate"):
c = self._activation(_linear([inputs, r * state],self._num_units, True))
#对应着公式(5)
new_h = u * state + (1 - u) * c
return new_h,new_h
def _linear(args, output_size, bias, bias_start=0.0, scope=None):
if args is None or (nest.is_sequence(args) and not args):
raise ValueError("`args` must be specified")
if not nest.is_sequence(args):
args = [args]
# Calculate the total size of arguments on dimension 1.
total_arg_size = 0
shapes = [a.get_shape().as_list() for a in args]
for shape in shapes:
if len(shape) != 2:
raise ValueError("Linear is expecting 2D arguments: %s" % str(shapes))
if not shape[1]:
raise ValueError("Linear expects shape[1] of arguments: %s" % str(shaPes))
else:
total_arg_size += shape[1]
dtype = [a.dtype for a in args][0]
# Now the computation.
with vs.variable_scope(scope or "Linear"):
#用一个大权重矩阵matrix 合并了公式(1)(3)(4)(5)中的W和U,实际上效果是一样的
matrix = vs.get_variable("Matrix", [total_arg_size, output_size], dtype=dtype)
if len(args) == 1:
res = math_ops.matmul(args[0], matrix)
else:
#array_ops.concat(1,args),将inputs和state按列连接起来,其实是增加了inputs的特征维度,将前一个状态中的信息放在当前状态中,也就增加了inputs的信息量,比如inputs=[[1,2,3],[4,5,6]],state=[[7,8,9,10],[11,12,13,14]], array_ops.concat(1,[inputs,state])=[[1,2,3,7,8,9,10],[4,5,6,11,12,13,14]],输入的特征维度从3增加到了7
# matmul(x,w)
res = math_ops.matmul(array_ops.concat(1, args), matrix)
if not bias:
return res
bias_term = vs.get_variable("Bias", [output_size],dtype=dtype,initializer=init_ops.constant_initializer( bias_start, dtype=dtype))
# matmul(x,w)+b
return res + bias_term
if __name__ == "__main__":
# size of inputs =[batch_size input_size]
#input_size 可以认为是一帧音频数据的特征维度(特征是多少维的),或者一个汉字矢量表示时的特征维度
#inputs=tf.constant([[1.,2.,3.,4.],[5.,6.,7.,8.]])
inputs=tf.constant([[1.,2.,3.,4.]])
#state 隐藏层的状态值,初始时,全部为0,其size为[batch_size hidden_size]
#state=tf.constant([[3.,2.,2.,2.,0.,2.],[2.,2.,2.,0.,2.,2.]])
state=tf.constant([[0.,0.,0.,0.,0.]])
hidden_size= 5
print 'reset value is: '
r=_linear([inputs,state],hidden_size,True,1.0)
with vs.variable_scope("updata_gate"):
u=_linear([inputs,state],hidden_size,True,1.0)
# print 'reset gate is :'
r_s=sigmoid(r)
u_s=sigmoid(u)
with vs.variable_scope("Candidate"):
c=_linear([inputs,r_s*state],hidden_size,True)
_c=tanh(c)
new_h=u_s*state+(1-u)*_c
#实例化一个对象,hidden_size的大小一定要和size(state)[1]相等
#single_cell=GRUCell(hidden_size)
#直接调用对象方法,因为类中有__call__函数
#_,new_state=single_cell(inputs,state)
sess=tf.Session()
sess.run(tf.initialize_all_variables())
#print sess.run(out)
print sess.run(r)
print 'reset gate is :'
print sess.run(r_s)
print 'update gate is:'
print sess.run(u_s)
print '状态中间值:'
print sess.run(c)
print '激活值'
print sess.run(_c)
print '新的状态:'
print sess.run(new_h)
print sess.run(inputs)
代码分析:
32行,用到了_linear()函数,其实就是个线性变换函数,乘加运算。主要做 W*X+b的运算















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









