







Tensorflow之word2vec
一. 简介及用途
- Word Embeddings:自然语言处理系统通常将词汇作为单一的离散符号,将会导致数据稀疏问题,为此用词汇的向量来为训练统计模型提供更多的数据。
Word2Vec使用到的词向量是DistributedRepresentation,其基本想法是通过训练将某种语言中的每一个词映射为一个固定长度的向量(这里的短是相对于one-hot representation的长而言的)
向量空间模型 (VSMs)将词汇表达(嵌套)于一个连续的向量空间中,语义近似的词汇被映射为相邻的数据点。向量空间模型在自然语言处理领域中有着漫长且丰富的历史,不过几乎所有利用这一模型的方法都依赖于分布式假设,其核心思想为出现于上下文情景中的词汇都有相类似的语义。采用这一假设的研究方法大致分为以下两类:基于技术的方法 (e.g. 潜在语义分析), 和 预测方法 (e.g. 神经概率化语言模型).
简而言之:基于计数的方法计算某词汇与其邻近词汇在一个大型语料库中共同出现的频率及其他统计量,然后将这些统计量映射到一个小型且稠密的向量中。预测方法则试图直接从某词汇的邻近词汇对其进行预测,在此过程中利用已经学习到的小型且稠密的嵌套向量。 - Word2vec是一种可以进行高效率词嵌套学习的预测模型。其两种变体分别为:连续词袋模型(CBOW)及Skip-Gram模型。从算法角度看,这两种方法非常相似,其区别为CBOW根据源词上下文词汇(’the cat sits on the’)来预测目标词汇(例如,‘mat’),而Skip-Gram模型做法相反,它通过目标词汇来预测源词汇。
Skip-Gram模型采取CBOW的逆过程的动机在于:CBOW算法对于很多分布式信息进行了平滑处理(例如将一整段上下文信息视为一个单一观察量)。很多情况下,对于小型的数据集,这一处理是有帮助的。相形之下,Skip-Gram模型将每个“上下文-目标词汇”的组合视为一个新观察量,这种做法在大型数据集中会更为有效。
二. 基本结构与原理
- 神经概率语言模型
神经概率语言模型使用到了神经网络。下图就是这个神经网络的结构示意图,它包括四个层:输入层、投影层、隐藏层和输出层。其中W,U分别为投影层与隐藏层以及隐藏层和输出层之间的权值矩阵,p,q分别是隐藏层和输出层上的偏置向量。
- 神经概率语言模型
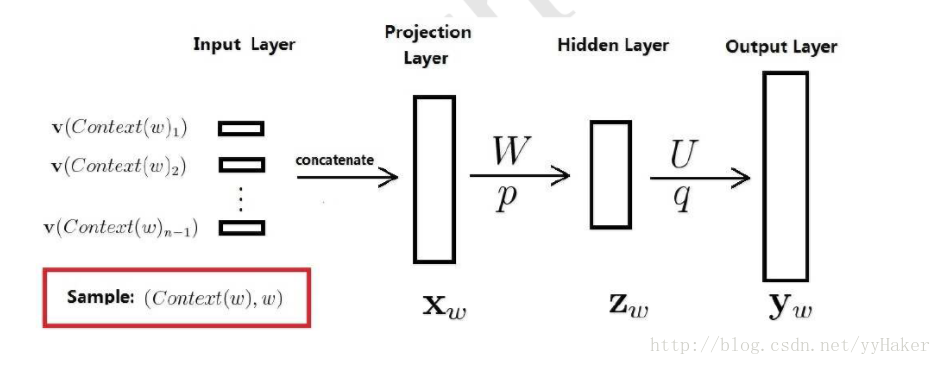
训练学习的过程:


优点: 1.1 词语之间的相似性可以通过词向量体现
1.2 基于词向量的模型自带平滑化功能
2 . 基于Negative Sampling模型
2.1 与Hierarchical Softmax 相比,NEG不再使用复杂的Huffman树,而是利用相对简单的随机负采样,能大幅度提高性能,可作为Hierarchical Softmax的替代。
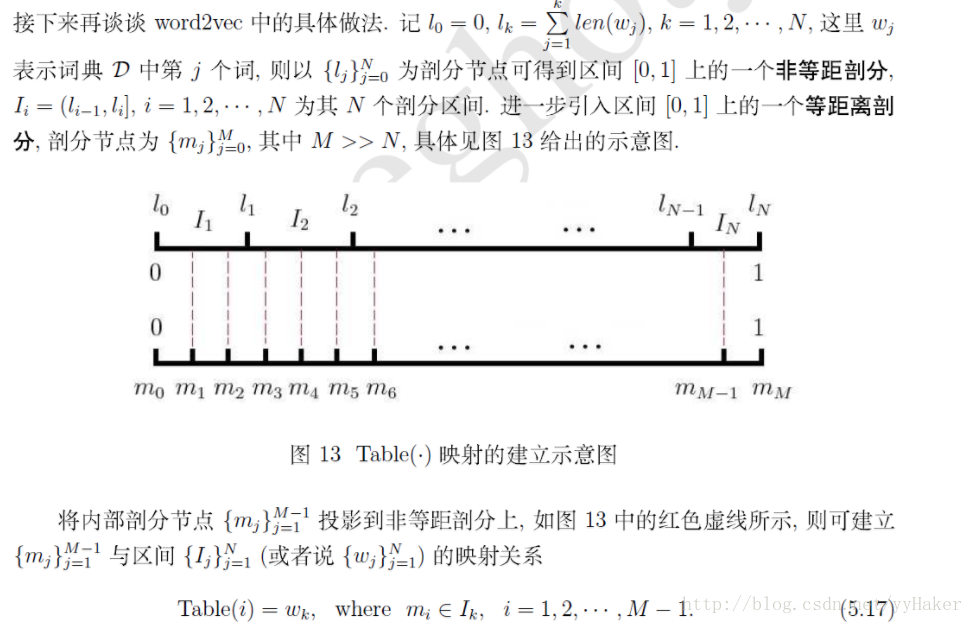
2.2 负采样算法(Negative Sampling)
对于一个给定的词w,如何生成NEG(w)呢?
词典D中的词在语料C中出现的次数有高有低,对于那些高频词,被选为负样本的概率就应该比较大,反之对于那些低频词,其被选中的概率就比较小,本质上是一个带权采样的问题。
下面用一段通俗的描述来理解带权采样:


2.3 CBOW模型
2.3.1 在CBOW模型中,已知词w的上下文Context(w),需要预测w,因此对于给定的Context(w),词w就是一个正样本,其他词就是一个负样本。采样方法见负采样。
2.3.1 计算



2.4 Skip-gram 模型

但是值得一提的是word2vev源代码中基于Negative Sampling 的Skip-gram模型并不是基于上述目标函数来编程,判断依据很简单,如果基于上述目标来编程,对于每一个样本(w,Context(w)),需要针对Context(w)中的每一个词进行负采样,而word2vec源码中只是针对w进行了|Context(w)|次负采样。

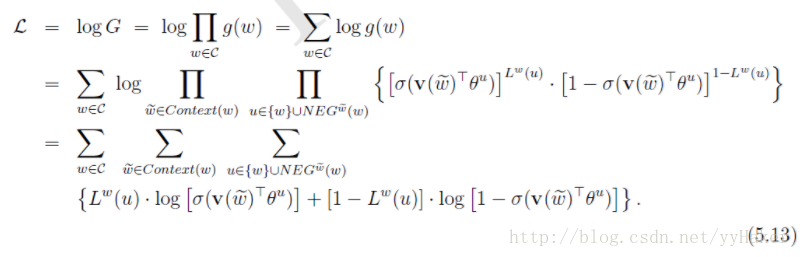

三. 实例参考
1. skip-gram模型的一个例子
代码见:mygithub
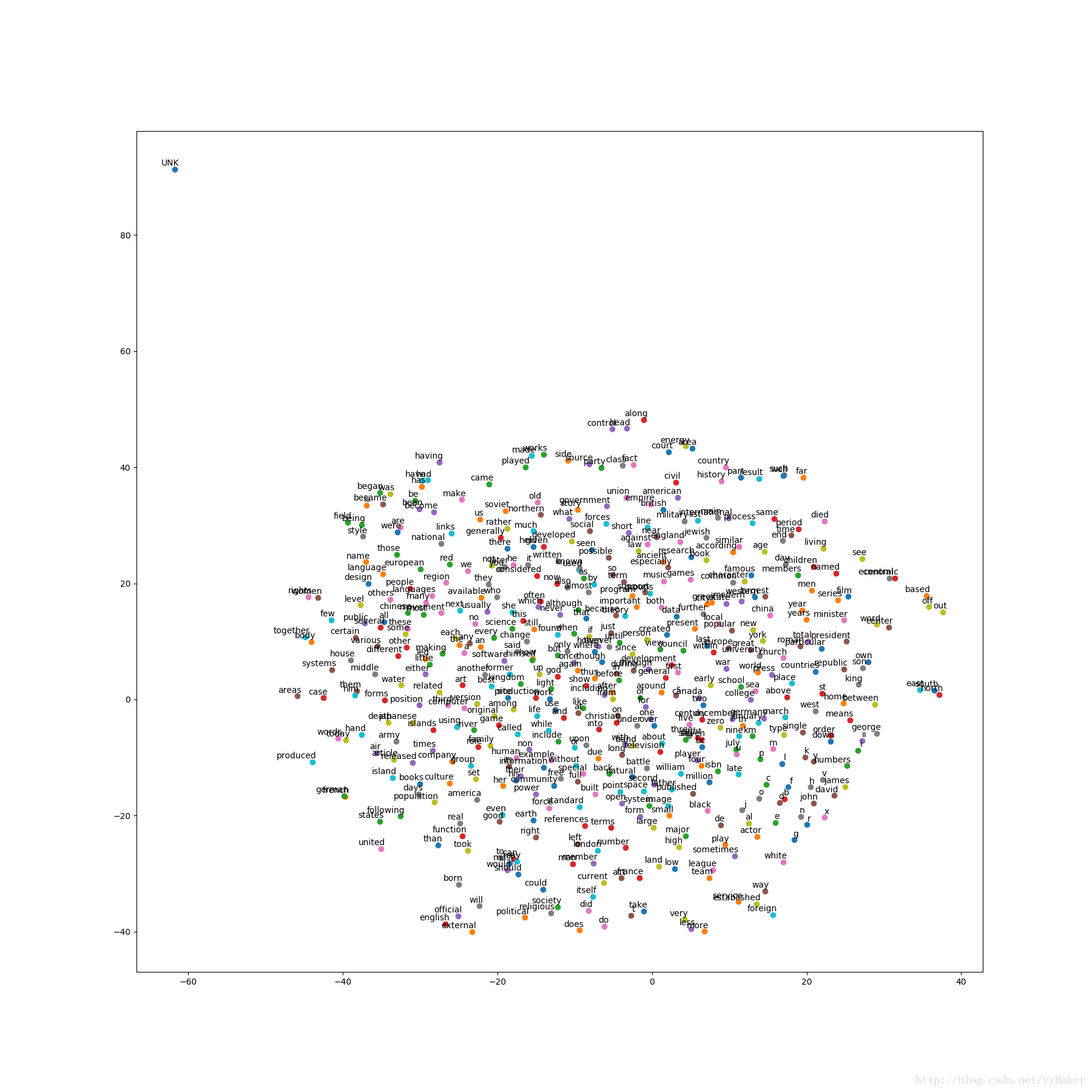
2. 可视化结果
四.展望
参考资料:














 1189
1189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









