







概念
集成学习(多分类器系统、基于委员会的学习)通过构建并结合多个学习器完成学习任务。
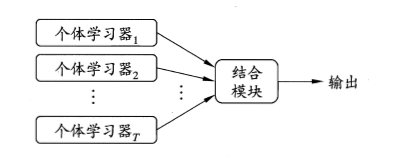
图1:先产生一组个体学习器,再利用某种策略将他们结合起来。
分类1(根据个体学习器是否为同种类型)
- 同质集成:集成中只包含同种类型的个体学习器(决策树集成中全是决策树,神经网络集成中全是神经网络),这样的个体学习器可以称为“基学习器”,有时还被称为弱学习器,对应的算法成为“基学习算法”
- 异质集成:集成里包含不同类型的个体学习器(同时包含决策树和神经网络),这样的个体学习器不能成为“基学习器”,可以成为“组件学习器”,或者直接就叫个体学习器。
分类2(根据串行/并行)
- boosting
个体学习器之间存在强依赖关系,必须串行生成的序列化方法 - bagging(如随机森林)
个体学习器之间不存在强依赖关系,可以同时生成并行化算法
好而不同(个体学习器有一定的准确性并且学习器间具有差异)
集成学习往往可以得到比单一学习器显著优越的泛化性能,对“弱学习器”(泛化能力略优于随机,例如二分类问题上精度略高于50%)尤为明显,但实际上往往会使用比较强的学习器(如考虑使用较少学习器)

boosting(ababoost、gbdt、xgboost)
- 从初始训练集训练出一个基学习器(每个训练数据的权重相等),再根据基学习器的表现对训练样本分布进行调整,使得先前学习器做错的训练样本在后续受到更多关注(预测错误的训练数据加大权重),然后基于调整后的样本分布来训练下一个基学习器,如此重复直至基学习器数目达到指定值T,最终对这T个基学习器加权组合。
- 每个个体学习器是underfitting,减少偏度
adaboost (即adaptive boosting)
- 论文:A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting
gradient boosting(如lightGBM ,xgboost )
- 论文:Greedy Function Approximation: A Gradient Boosting Machine
- 论文:XGBoost: A Scalable Tree Boosting System
adaptive boosting和gradient boosting区别
训练模型时:
- adaptive boosting——侧重样本权重
- gradient boosting——侧重真实数据与预测数据的差值
集成模型时:
- adaptive boosting
二分类:
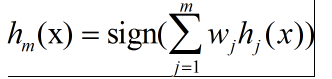 多分类:
多分类:
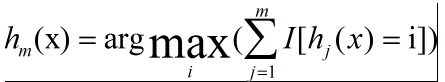
bagging
- 论文:Bagging Predictors
Leo Breiman
Published in Machine Learning 1996 - 思想:在原始数据集有放回抽样,选k个数据集分别训练得到k个学习器(新数据集样本数量与原数据集一致,允许存在重复数据)
- 每个个体学习器是overfitting的,减小方差
随机森林(决策树+随机选择特征+bagging)
- 为每棵树随机选择特征
- 论文:The random subspace method for constructing decision forests
- 使用所有特征,为树的每一个节点随机选择特征
- 论文:Random Forests Machine Learning
stacking
- 训练多个不同模型,再以之前训练的各个模型的输出作为输入训练一个新模型
- 论文:Stacked Generalization
- 缺点:容易过拟合(如果第一层的模型已经过拟合,第二层的模型基于过拟合的数据很容易过拟合)














 1163
1163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









