







一、概述
对于一个由多个子系统组成的分布式系统而言,上述章节讲到,不同的业务子系统数据库独立。从本质上看,交互的还是数据。那我们需要看下数据一般有哪些特性。
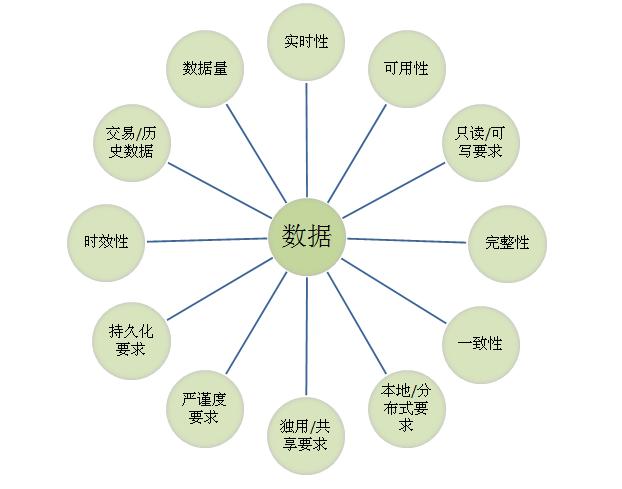
子系统之间的数据交互,也需要根据交互的数据特性来区分不同的交互方式。粗略来划分,系统的数据大致分为静态数据(基础数据,机构,品牌,商品信息,门店信息,基础设置信息,用户账号等),和动态数据(各类业务单据)以及报表类数据、日志数据。
从系统架构上,SOA上,这个角度,貌似这些数据应该有一个统一的系统维护,对外提供API访问接口。实际上,我们确实有这样一个系统基础主数据系统。设计上,也可以是提供API数据接口访问,增量数据走异步通知(实际上通知只是通知了改变事件,数据同步还是API接口)。这样,如果基于这样的设计,设计上需要考虑到控制同步粒度,同步的范围,以及同步的时间。
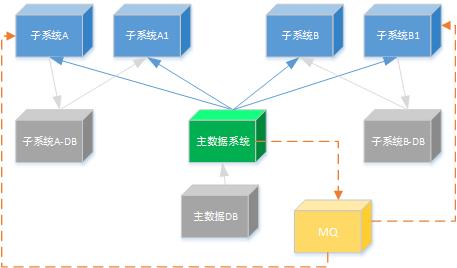
那就是说主数据提供数据服务接口,哪个子系统使用什么数据,就访问哪些接口。看上去,真的是一个比较符合标准的一个方案。但是,还有些细节我们还需要考虑。比如,每个子系统同步的数据有异同,每个子系统需要记录每次同步的时间点,mysql的时间戳到秒级,精确性的要求,需要考虑唯一同步的编码。特别是对大批量修改操作,或是批量导入生成的基础数据,设计处理复杂性陡升。
我们再回头看看,对于静态性质的部分数据,比如,机构,品牌,商品信息等,会在几个系统中同时用到,比如做一些数据过滤,或是一些统计查询,特别是有的子业务系统与自己系统的业务数据的一些关联查询,确实是需要这些数据在本系统存储下来。
还有没有一些别的方案呢?
还是先从我们的基础数据特性说起。
基础数据特性
数据量 最多10w级别
更新频率 低(但有批量的更新与新增)
时效性 最新
一致性 要求高
完整性 要求高
持久化 需要本地持久
基础数据同步到子业务中,以后就是查询使用。
有没有什么工具能够帮助解决这些数据同步的问题呢?还真有,Otter
https://github.com/alibaba/otter
工作原理:
原理描述:
1. 基于Canal开源产品,获取数据库增量日志数据。
2. 典型管理系统架构,manager(web管理)+node(工作节点)
a. manager运行时推送同步配置到node节点
b. node节点将同步状态反馈到manager上
3. 基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作.
canal 支持mysql系列的5.1 ~ 5.6版本,目前maridb经测试暂不支持. (全面支持ROW/STATEMENT/MIXED几种binlog格式的解析)
mysql做为master,otter只支持ROW模式的数据同步,其他两种模式不支持. (只有ROW模式可保证数据的最终一致性)
1. 基于Canal开源产品,获取数据库增量日志数据。
2. 典型管理系统架构,manager(web管理)+node(工作节点)
a. manager运行时推送同步配置到node节点
b. node节点将同步状态反馈到manager上
3. 基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作.
canal 支持mysql系列的5.1 ~ 5.6版本,目前maridb经测试暂不支持. (全面支持ROW/STATEMENT/MIXED几种binlog格式的解析)
mysql做为master,otter只支持ROW模式的数据同步,其他两种模式不支持. (只有ROW模式可保证数据的最终一致性)
二、后续
架构设计过程也是一个多方平衡的过程,没有一种完美的架构解决所有的问题。站在项目全局上,我们使用这样的工具1是可以减少程序开发人员绝大数工作量,(各种中间件的出现也是在解决这种应用中的共性问题。)从而加快整个项目开发的进程。2是,也减少系统交互上设计的复杂性。(引入新的设计模型,在解决面对的问题上,引入了多少问题)。3是,Otter这种同步场景与我们的需求也比较匹配。那我们其他数据是不是也需要采用这个工具同步呢?或是什么场景下我们采用呢?
最终还是需要看
数据关键特性上。说到更具体一点,还是需要分析各个子系统间需要同步哪些数据,一一列出来,然后,根据以下维度做下区分。
数据同步维度划分:
全量/子集
基础数据/交易数据/历史数据
持久化需求
时效性
一致性
完整性
数据量
我们常常讲重大需求决定概念架构设计。
架构设计一直在路上。















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









