










文章目录
- deep image matting(2017)
- Context-Aware Image Matting for Simultaneous Foreground and Alpha Estimation(2019)
- Indices matter
- Semantic Human Mattimg
- Towards Real-Time Automatic Portrait Matting on Mobile Devices
- A Late Fusion CNN for Digital Matting
- Learning to Composite Context-Realistic Data for Image Matting
- Real-time deep hair matting on mobile devices
- Efficient Semantic Video Segmentation with Per-frame Inference
- Soft Instance Segmentation
- SOLOv2
- SOLOv1
pymatting这个网站很不错
matting技术旨在分出前景背景和过渡区域用于抠图,他的理论基于以下公式
I
=
α
×
F
+
(
1
−
α
)
×
B
I= \alpha \times F + (1-\alpha)\times B
I=α×F+(1−α)×B
以上表示一张图像是由前景和背景通过
α
\alpha
α称之为alpha matte,作为一个蒙版,得到的,因此抠图技术多称之为alpha matting,即给出图片预测出
α
\alpha
α。
- 但是怎样通过
α
\alpha
α得到前景呢?又是一个病态问题?是不是
α
≠
0
\alpha\neq0
α=0的地方抠出来就是前景?好像也不是?没有什么结果
α I = α F \alpha I=\alpha F αI=αF
( 1 − α ) I = ( 1 − α ) B (1-\alpha)I=(1-\alpha)B (1−α)I=(1−α)B
至少可以得到前景的抠图替换任意背景
早期的alpha-matting主要是通过trimap/scribble+img通过采样统计或者区域传播,获取matting结果
- bayes matting
- knn matting
- closed formed matting
- 等
算法没有复现,不再赘述
- 基于深度学习的方法
deep image matting(2017)
- Architecture
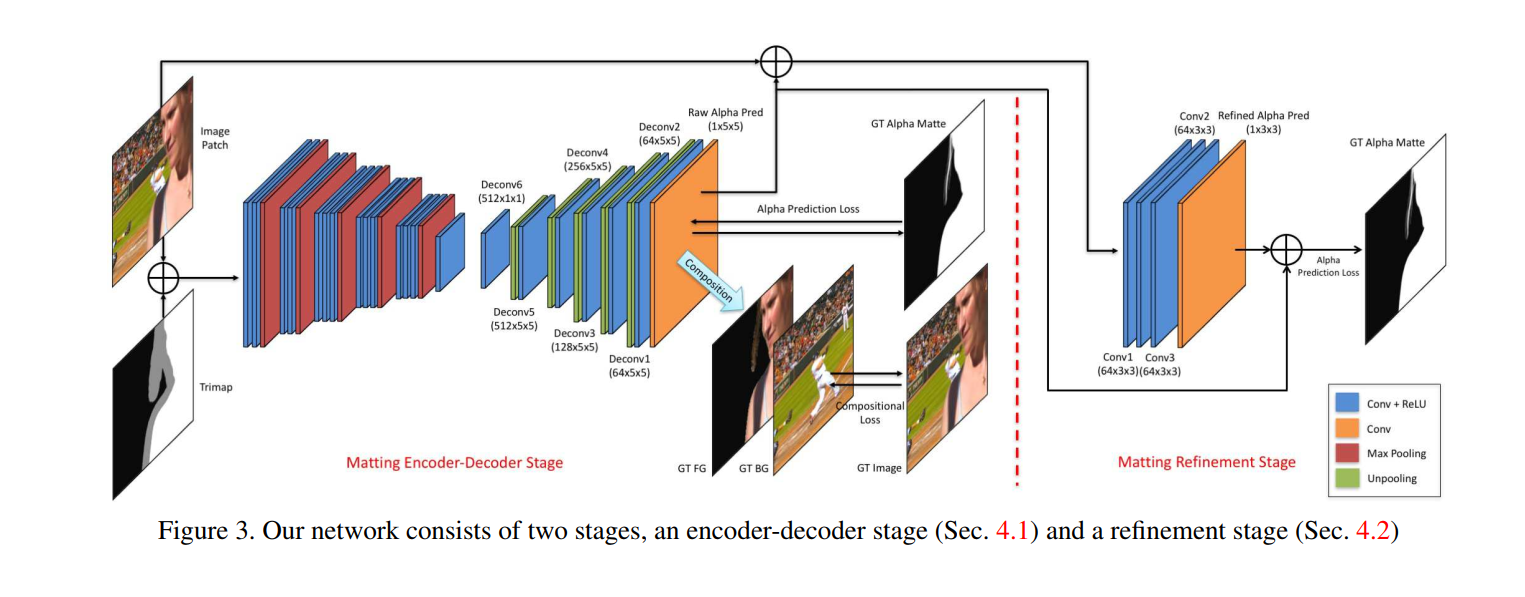
借鉴语义分割网络-SegNet,使用对称的vgg结果,上采样通过unpooling - loss
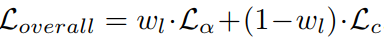
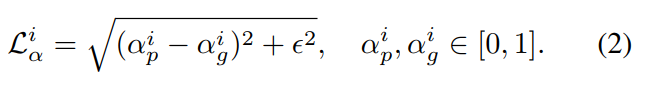
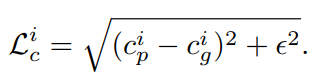
损失函数是alpha loss + composition loss
训练时先训练第一个网络,再训练第二个网络,最后finetune
Context-Aware Image Matting for Simultaneous Foreground and Alpha Estimation(2019)
- architecture
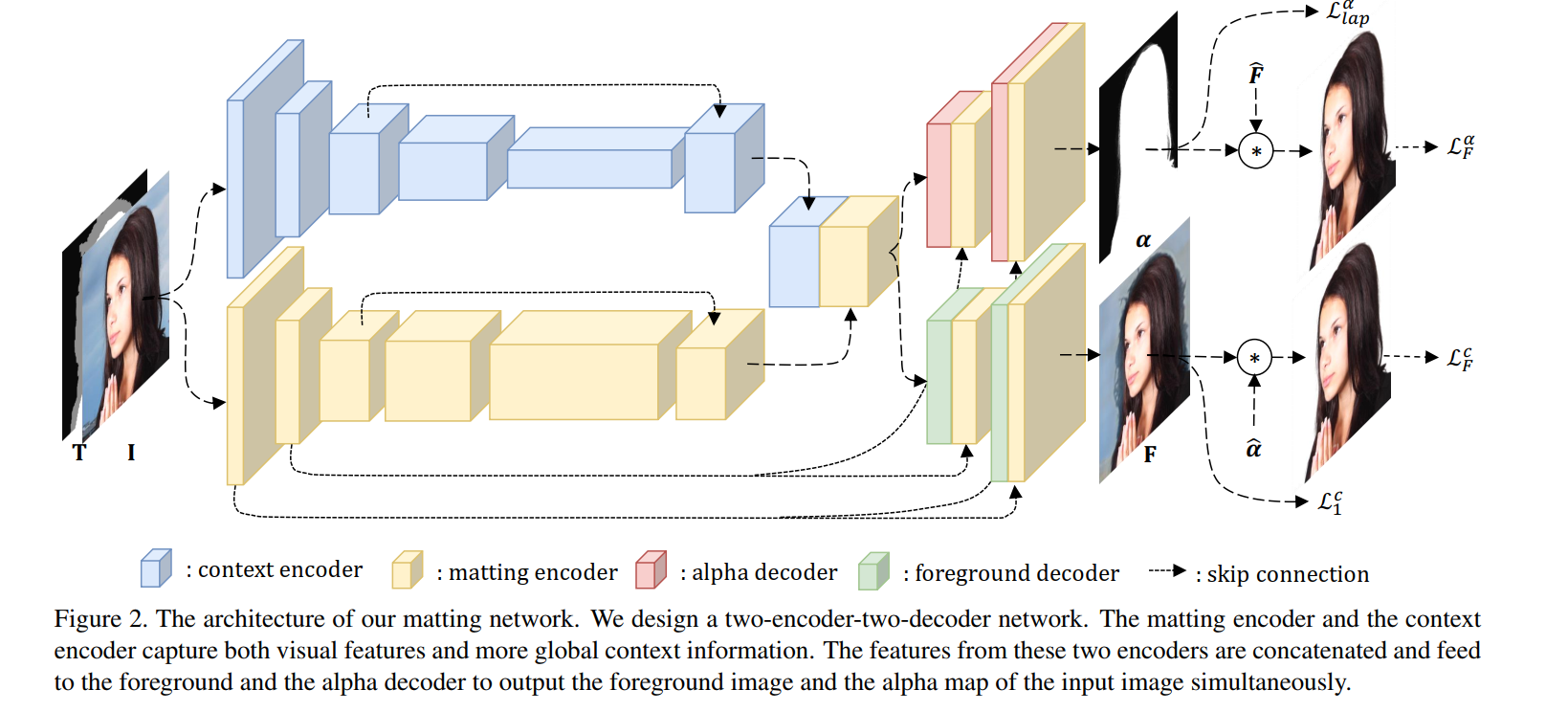
matting encoder - local feature
context encoder - global context information(larger down-sampleing factor) - loss
L_lap 对alpha进行laplance分解多尺度计算loss
vgg16 perceptural loss
共四个loss
Indices matter
沈老师文章,思考上采样对于不同任务的影响,进而提出可学习的上采样模块,采样不过是feature的函数
文章有句话我觉得说的挺好的:
下采样过程中,我们怎么避免信息的丢失,二上采样过程中怎样充分利用储存的信息-下采样通道数加倍,上采样unpooling等都是尝试
- IndexNet module 可以耦合再任意采样操作中,在我看来类似于attention的操作
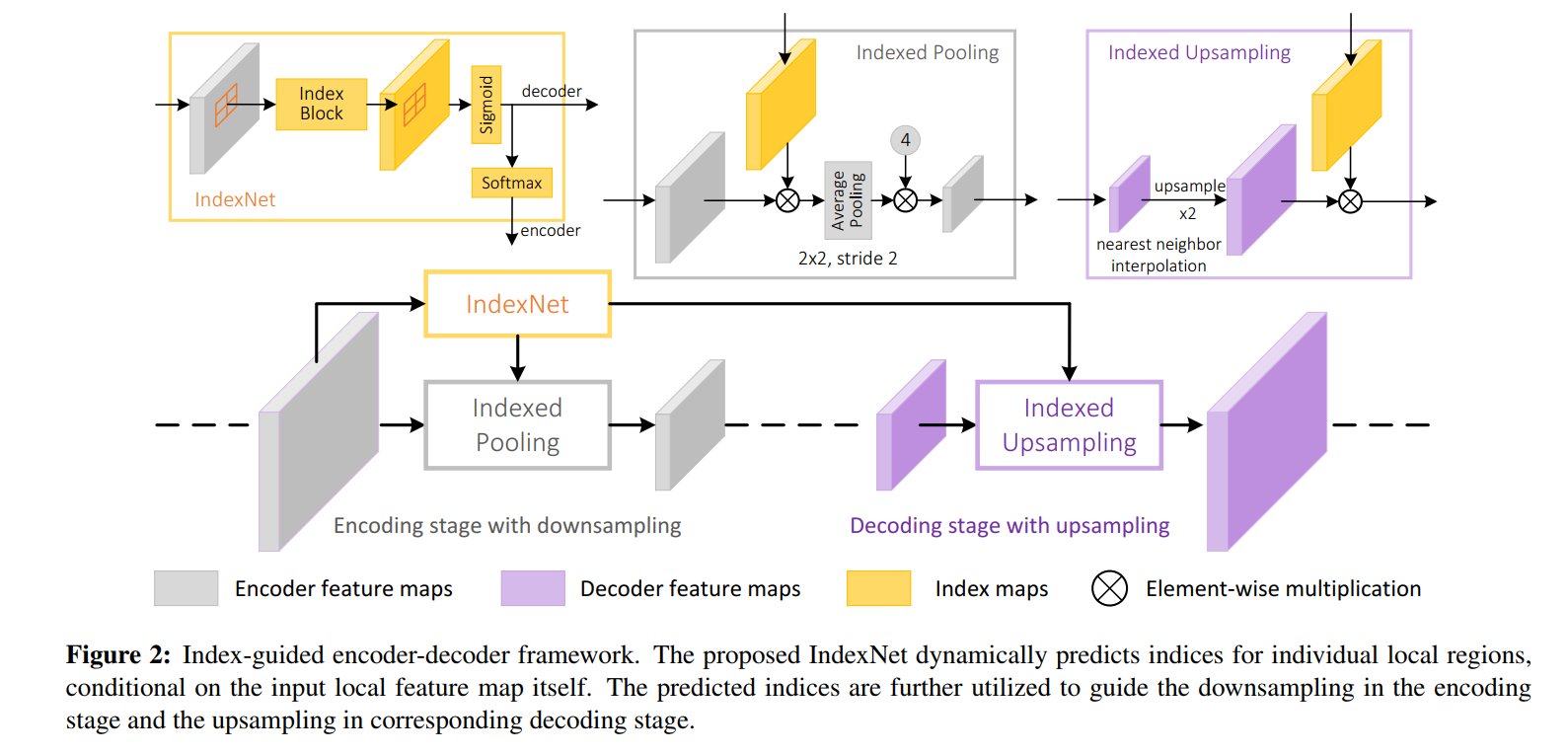
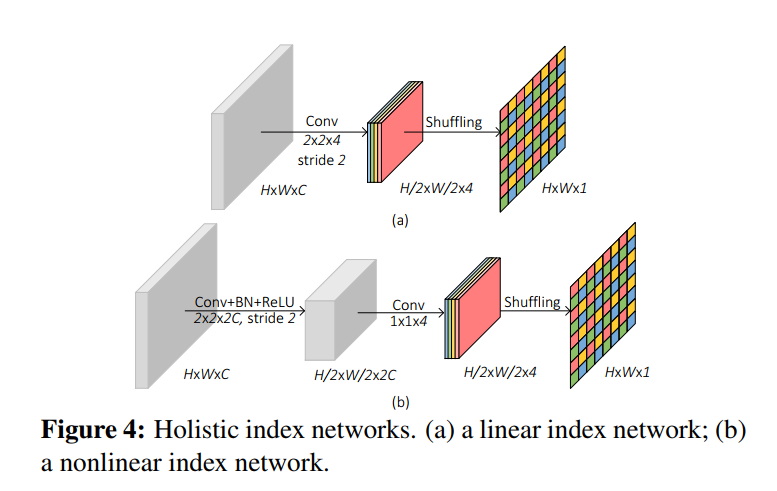
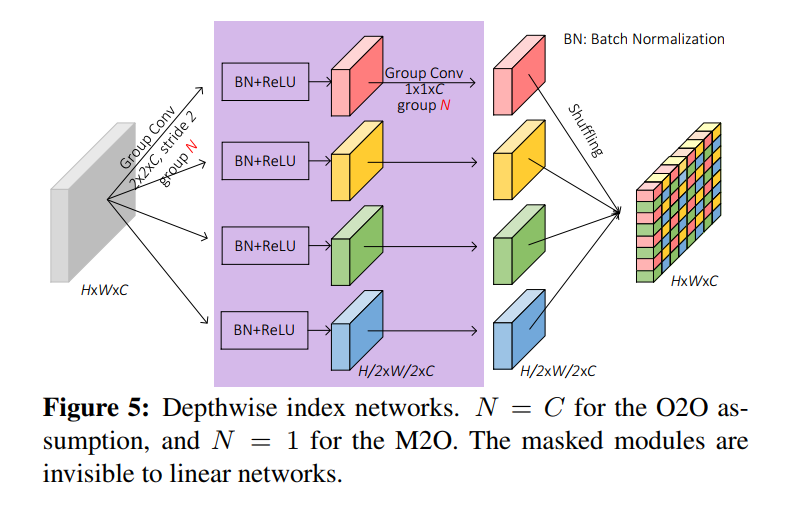
从上面可以看出,根据feature map 计算出index function作为一种信息,feature上采样或者下采样中带入到feature中以储存更多的信息
还有诸如guided contextual attention等通过输入img+trimap输入alpha matte的方法
显然trimap不是所有输入都具有的,需要人工标注或交互操作,那么怎样可以自动抠图而不借助其他额外操作呢?
对于特定的事物我们好像可以有一种方法,就是输入任意图像,然后总是抠出同一事物,这好像可以做到自动抠图的功能
最简单的想法
Semantic Human Mattimg
- Architecture
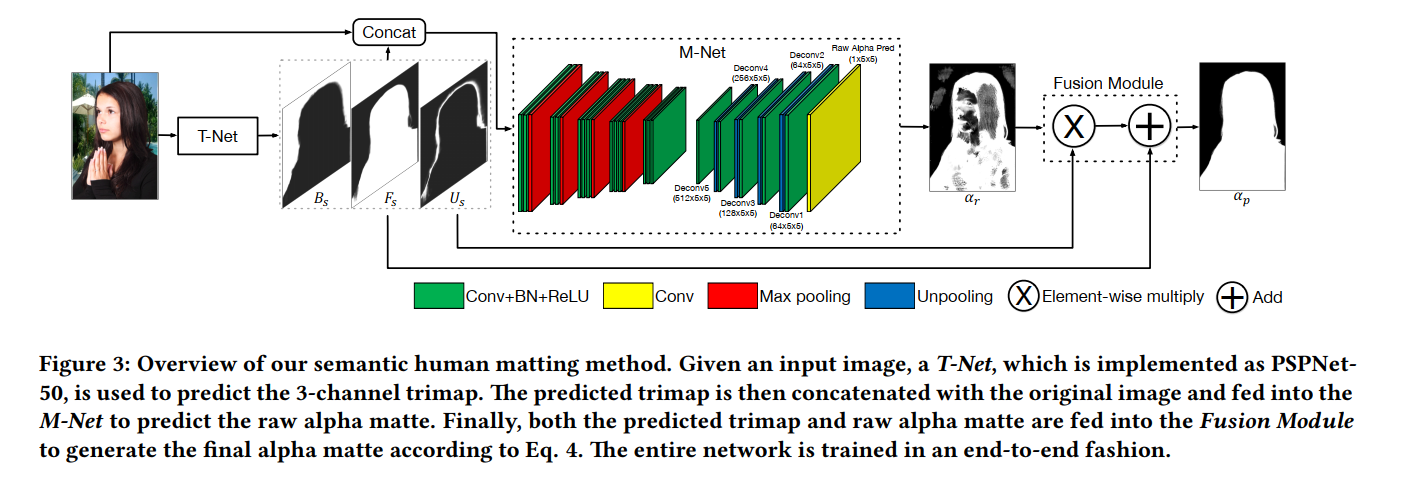
通过一个语义分割网络,预测一个比通用的trimap更精细的trimap,然后再用一个matting网络即可实现全自动的抠图流程 - fusion module
我看沈老师的alpha输出就是这样fusion的,不知是否可以借鉴 - loss
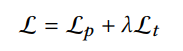
两个平平无奇的loss,其实是三个,第一项经典的alphaLoss+compositionLoss( λ = 0.01 \lambda=0.01 λ=0.01),第二项为trimap的分类loss,沈老师的代码也可以看到
然而这样的网络似乎过于臃肿,下面这篇文章似乎挺符合要求的,这也是我复现的文章
Towards Real-Time Automatic Portrait Matting on Mobile Devices
- Architecture
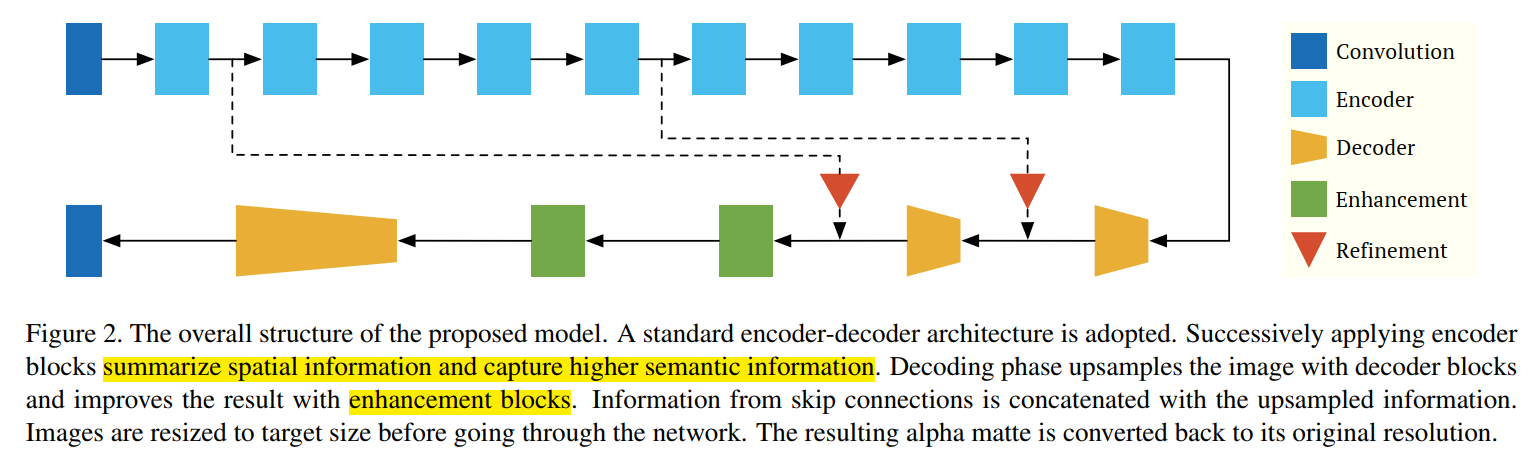
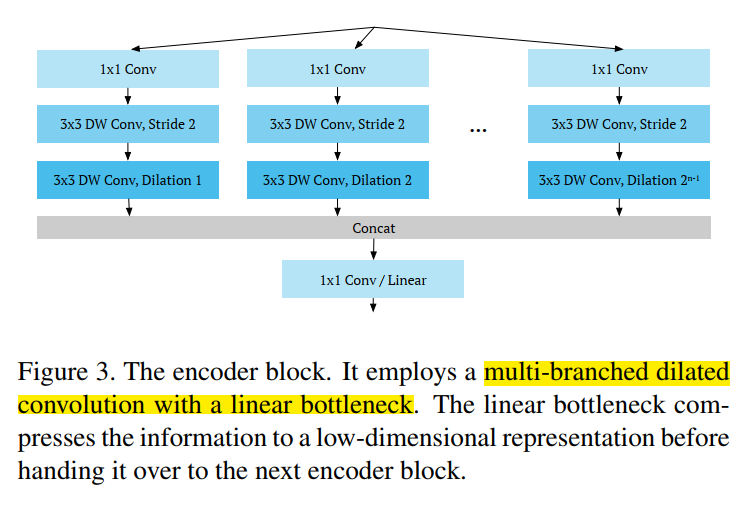
网络结构大概分为三类: - encoder
depthwise separable aspp module 深度可分离卷积的ASPP模块 - EncoderBlock
以下为encoderblock的torch实现,将深度可分离卷积和aspp模块融合在一起,模仿tf写的,可以学习一下
def multiply_depth(depth, depth_multiplier, min_depth=8, divisor=8):
'''
get output num of channel, multiplies of divisor, determined by depth_multiplier
'''
multiplied_depth = round(depth * depth_multiplier)
divisible_depth = (multiplied_depth + divisor // 2) // divisor * divisor
return max(min_depth, divisible_depth)
class EncoderBlock(nn.Module):
'''
for dilation rates
conv_1x1 + [stride=2: sep_conv] + sep_conv_dilation
'''
def __init__(self, input_depth, expanded_depth, output_depth, depth_multiplier, rates, stride, shortcut_depth=None):
super(EncoderBlock, self).__init__()
input_depth = multiply_depth(input_depth, depth_multiplier)
if shortcut_depth is not None:
input_depth = input_depth + multiply_depth(shortcut_depth, depth_multiplier)
expanded_depth = multiply_depth(expanded_depth, depth_multiplier)
output_depth = multiply_depth(output_depth, depth_multiplier)
self.op = nn.ModuleList()
num_of_branch = 0
for i, rate in enumerate(rates):
conv = []
conv += [nn.Conv2d(input_depth, expanded_depth, 1), nn.LeakyReLU(0.2, True)]
if stride > 1:
conv += [nn.Conv2d(expanded_depth, expanded_depth, kernel_size=3, stride=stride, padding=1, groups=expanded_depth), nn.LeakyReLU(0.2, True)]
conv += [nn.Conv2d(expanded_depth, expanded_depth, kernel_size=3, padding=rate, dilation=rate, groups=expanded_depth), nn.LeakyReLU(0.2, True)]
self.op.append(nn.Sequential(*conv))
num_of_branch += 1
self.out = nn.Conv2d(expanded_depth*num_of_branch, output_depth, 1)
def forward(self, x):
ops_out = [ops(x) for ops in self.op]
ops_out = torch.cat(ops_out, dim=1)
out = self.out(ops_out)
return out
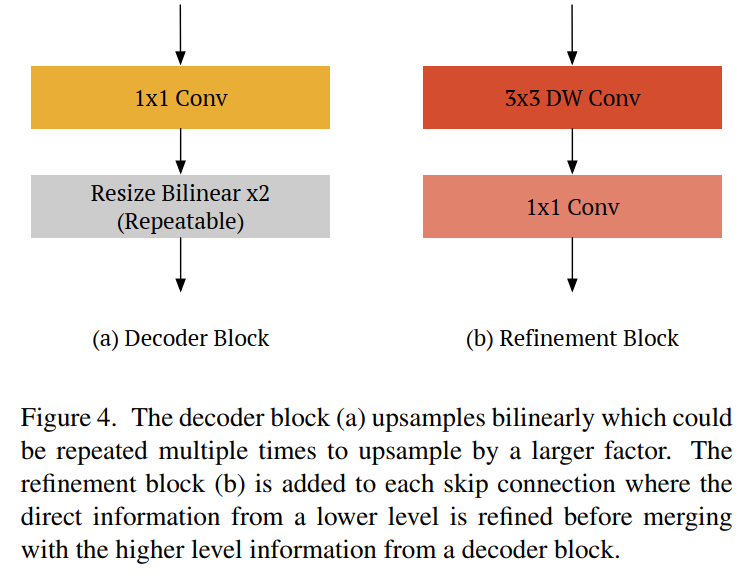
- decoder
1x1 卷积 + 双线性插值 - refinement
depthwise + pointwise
- los
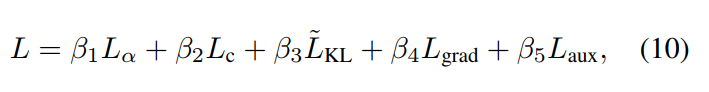
第一项:alpha loss (l1 loss)
第二项:composition loss(l1 loss)
第三项:crossEntropy loss
第四项:x,y方向梯度loss
第五项:暂时没有用,用encoder的最后一层,也就是#encoder10和下采样后的alpha gt之间算交叉熵
- 数据预处理
- 保证宽高比缩放
- 旋转后crop有效区域
下面准备复现下late fusion matting具体再看,也是一篇end2end的matting
A Late Fusion CNN for Digital Matting
使用two deocder branches+fusion branch
This design provides more degrees of freedom than a single decoder branch for the network to obtain better alpha values during training
他认为两个branch分别预测前景和背景给了alpha matte更多的自由度,这个是不是和mmnet最后预测结果为两个层,但是他计算loss是用的softmax后的结果,继续往下看看。
- 暂时没时间看了,有空再填
Learning to Composite Context-Realistic Data for Image Matting
以上都是合成数据作为训练集,怎样评价数据质量,运用到实际场景中又是否会和超分一样存在问题?这篇文章对于数据集做了一些工作
…忘记保存了,写了好多都没了。。。但是这篇文章可能是下一步工作的重点,二次阅读的时候在补上
Real-time deep hair matting on mobile devices


- ddpthwise的卷积不出意外
- skip-connect只使用的1x1的卷积,并且变cat为add
- 下采样了32倍,没有dilation卷积,可能下采样给的已经够多了吧
- 0-1归一化,Adadelta优化器,lr=1?, weight_decay=2e-5
- 但是在视频帧上,连续一致性好像也是非常重要的一部分,视频帧的分割/matting该怎么做呢?
google 这个新闻提到可以使用上一帧的结果来指导下一帧的分割,但是这样增加了计算量
Efficient Semantic Video Segmentation with Per-frame Inference
沈老师的这篇文章,使用了帧间信息蒸馏的方法,在没有增加计算量的情况下实现了小网络的效果
在训练阶段使用了tempral consistency
- 以前的工作主要使用两种方法来提升视频分割性能
- 后处理或者使用额外的模块使用多帧之间的信息
- keyframe policy 关键帧的信息,即是在关键帧使用更多的计算资源,再将关键帧的信息传播,这样带来两个问题,一是资源的不平衡,二是距离关键帧越远信息越不准确
- 本文使用一种叫
motion guided temporal loss temporal consistency knowledge distillation- Architecture
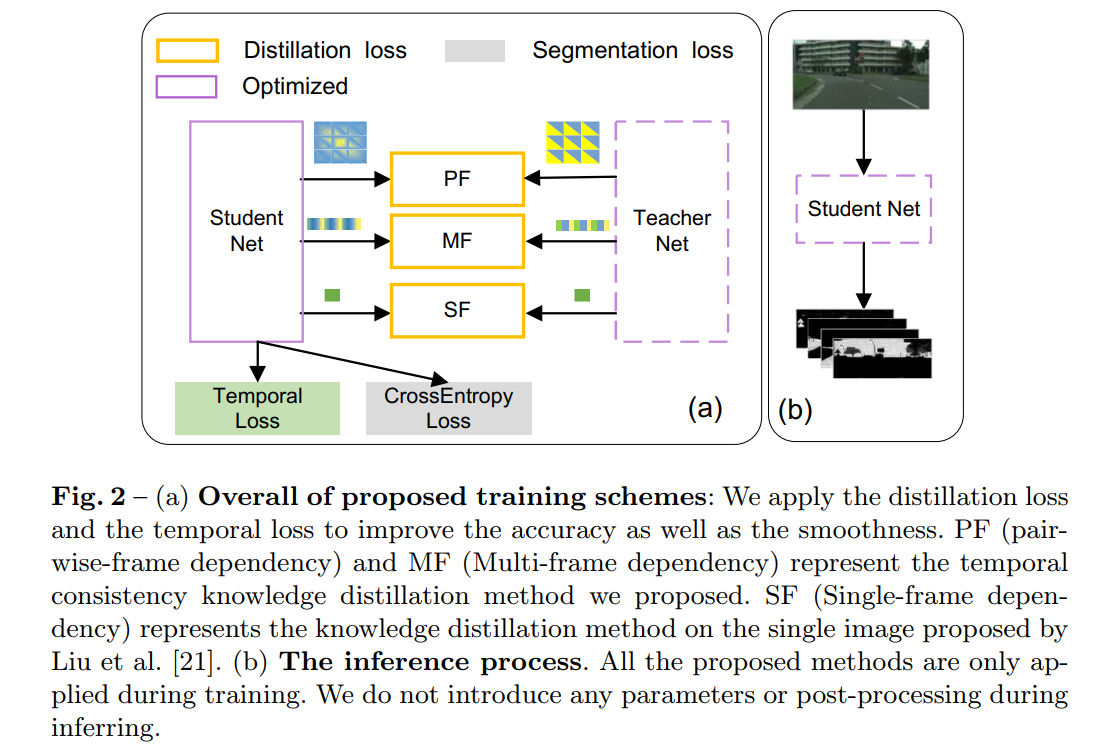
网络具体介绍看上面
PF/MF指的是temporal consistency knowledge distillation
SF就是正常的知识蒸馏loss
temporal consistency loss指的是 - Temporal loss
训练网络使用,可以用在S/T-Net
occlusion指的是,预测的是?
通过运动估计,预计对应的label应该形变为什么样子
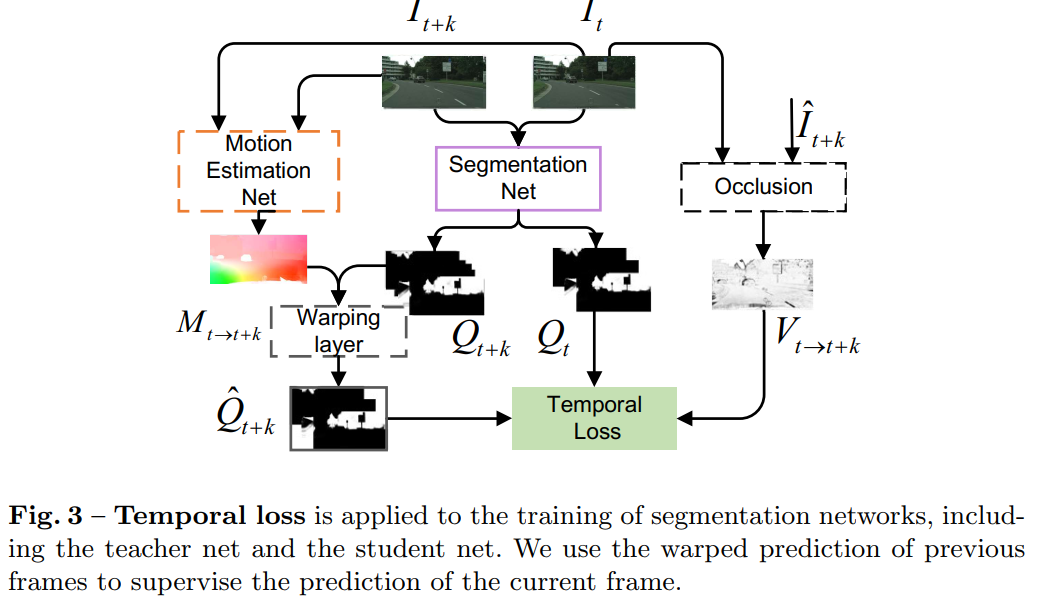

-
PF/MF

-
AT(attention) operator
计算相似map,可以理解为相关矩阵 -
PF
使得S和T之间计算的相似矩阵约束

-
MF
提取分类前最后一层的feature,计算self-similarity map,在经过LSTM获取embed
S和T网络共享LSTMd的参数,文章提到模型会容易崩塌,当LSTM的权重为0时,做了weight clip和enlarges E -
optimization
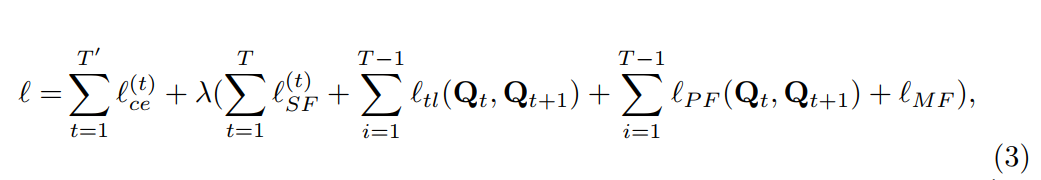
- 交叉熵损失
- SF单帧知识蒸馏的loss
- tl-temporal loss,两帧motion约束
- PF S和T同一帧的AT约束
- MF S和T视频所有帧之间通过LSTM得到embed之间的蒸馏损失
- KaTeX parse error: Undefined control sequence: \lambd at position 1: \̲l̲a̲m̲b̲d̲=0.1
实际上,只是用了mmnet 的网络结构进行训练还有hair matting 中的deeplab
现实中遇到的问题就是,使用现有的数据训练总是会有过拟合的问题出现,就是训练集表现较好但是测试集表现很差,在真实数据中无法泛化,训练了三个月毫无用处
可能这需要预训练的模型来支撑才可以,看完下一篇文章,先复现,再训练自己的模型,这样就可以找到训练中的问题-2020.06.22
Soft Instance Segmentation
soft instance segmentation - SOFI
事实证明它不仅可以提升分割的准确率,也能再matting 上取得很好的结果

- simple instance segmentation framework SOLO [30], termed Soft SOLO (SOSO)
- Dataset
The dataset contains a total of 200 images and 537 high-quality alpha mattes, termed as SOFI-200
- Method
- SOLO
segment objects by location. It conceptually divide the input image into S × S grids. If the center of an object falls into a grid cell, that grid cell is responsible for predicting the object class as well as assigning the per-pixel location categories.
通过位置分割目标。将图像分为若干网格,如果物体的中心落在网格中,那么这个网格负责预测物体的类别和每一个像素的类别 - SOLOv2 [30]
takes a step further by predicting the mask features and convolution kernels separately. Overall, they take an image as input and generate a set of object class probabilities and corresponding binary masks
分别预测掩码特征和卷积内核。总的来说,它们以一幅图像作为输入,生成一组目标类概率和对应的二进制掩码
其实上面都不太懂
- network architecture
基于 SOLOv2 框架
backbone + FPN + prediction head(object category branch + mask kernel branch)[shared weights for different level] - mask feature branch
- fuses feature maps and 1/4 scale
- add Low-level Module(LLM)
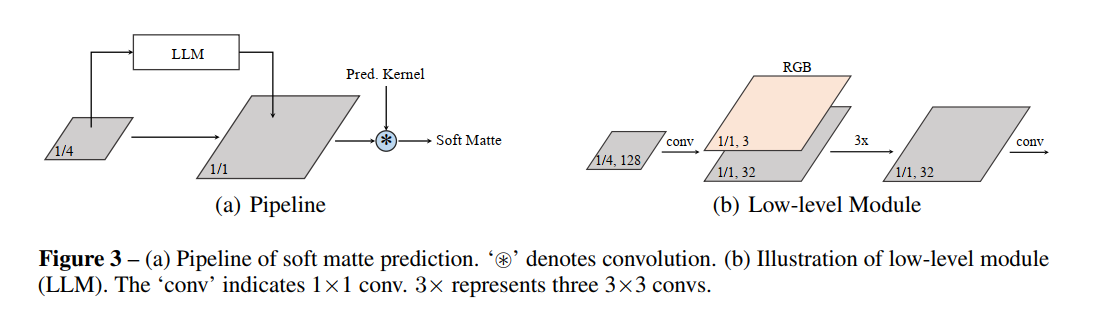
上图怎么看不懂呢? - 1x1 卷积从1/4 scale 到 1/1 scale?
- LLM 的输出通过1x1 卷积扩充到256 channel 然后和先前的1/4 features 相加得到结果,再和pred Kernel 卷积
- 这里的pred Kernel 指的是?
- Loss

L c a t e L_{cate} Lcate 是focal loss 分类
L m a t t e L_{matte} Lmatte 是soft matte prediction

均方误差和Dice 系数,后面的消融实验证明二者缺一不可 - 这里的 cate 和dice 都是分类的损失,cate 是可以为概率的那么dice 呢?
- training
- 训练阶段category branch 权重是固定的,为了保证良好的目标识别能力
- 使用了mixed training strategy,matting 和实例分割的数据集都使用了,前者监督matte,后者监督实例
- inference
the prediction branches execute in parallel after the backbone network and FPN, producing category scores, predicted convolution kernels and mask features
上面这句话怎么看不懂呢?预测的分支不就是category 和mask features?
- category score p_i,j 再grid(i,j ) 使用0.1 的阈值过滤低置信度的预测??
- mask features 使用sigmoid输出结果
- finally,使用matrix NMS 移除冗余的预测,这又是什么操作??
SOLOv2
- Dynamic
dynamically learning the mask head of the object segmenter such that the mask head is conditioned on the location. Specifically, the mask branch is decoupled into a mask kernel branch and mask feature branch, which are responsible for learning the convolution kernel and the convolved features respectively
动态学习目标检测器的mask head,mask head 是位置约束的
mask branch 解耦为mask kernel branch 和 mask feature branch 分别负责学习convolution kernel 和 convilved features
上面的操作不太懂 - Matrix NMS(non maximum sup-pression)
更高更快更强
这个操作也不太懂
改进了SOLOv1 的 mask learning and mask NMS
看不懂,先看SOLOv1 吧
SOLOv1
mainstream approaches either follow the “detect-then-segment” strategy, as used by, e.g., Mask R-CNN, or predict embedding vectors first then use clustering techniques to group pixels into individual instances
主流的方法要么遵循“检测-分割”的策略,例如Mask R-CNN, 或者预测编码向量然后像素聚类分割实例
都不太懂。。。。
We view the task of instance segmentation from a completely new perspective by introducing the notion of “instance categories”, which assigns categories to each pixel within an instance according to the instance’s location and size, thus nicely converting instance mask segmentation into a classification-solvable problem
文章将实例分割问题从“实例分类”概念的角度出发,根据实例的位置和大小将每个像素分类,这样将实例mask 分割问题转为分类可解的问题
也不是很懂,分割不就是像素分类?
所以现在实例分割任务分解为两个分类任务
类别分类和像素分类?这不就是本来的概念,再看看
- intruction
- motivation
COCO 数据集中,每个98.3% 的实例中心距离都是大于30个像素的,剩下的1.7%中又有40.5% 的实例大小比例是超过1.5倍的,所以我们是不是可以认为实例之间的拥有不同的中心位置或者不同的尺寸大小。基于此观察我们是否可以直接通过中心位置和目标大小来区分不同的实例?
两个实例连在一起了,你是怎么知道他们不是同一个实例?逻辑不应该是知道有几个实例然后再通过这个方法区分他们。
- SOLO: Segment objects by locations
- Locations
将一幅图像分为SxS 个网格区域,这样就有S平方个中心点位置类
根据目标中心的坐标,将实例分配给其中的一个网格单元,作为其中心位置的类别
[这里的“其”指的是,可能指的是网格单元?]
这样输出的类别分支不再是hwc,而是ssc?好像不是这样的,为什么要分类别呢?直接预测类别个mask 不就行了吗,这又和语义分割一样了,category branch 是用来区分实例的吗?和多目标检测又有什么联系?目标检测的输出是什么?
同时输出的channel map 预测属于当前类别的instance mask















 1933
1933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









