






算法思想
按路径长度递增次序产生算法:
把顶点集合V分成两组:
(1) S: 已求出的顶点的集合 (初始时只含有源点V0)
(2) V-S=T: 尚未确定的顶点集合
将T中顶点按递增的次序加入到S中,保证:
(1)从源点VO到S中其他各顶点的长度都不大于从VO到T中任何顶点的最短路径长度
(2)每个顶点对应一个距离值
S中顶点: 从VO到此顶点的长度
T中顶点: 从V0到此顶点的只包括S中顶点作中间顶点的最短路径长度
依据:可以证明V0到T中顶点Vk的,或是从VO到Vk的直接路径的权值; 或是从V0经S中顶点到Vk的路径权值之和
理解最短路径
既可以是路线最少的路径,也可以是为路径设置的任意含义的数值的最小值(eg. 耗时最少、消费金额最少)
我们称路径关联的含义数值为图的权重(weight)
算法核心在于找到从起点到终点间的每个节点的最少开销,最后再计算出起点到终点的路径.这是基于广度优先的经典算法之一.
在解决问题的途中,需要存储以下三种数据:
(1)原图
(2)每个节点的最少开销
(3)导致节点最少开销的父节点(用以帮助回溯出最短路径)

上图为一有权有向图,每条边上的权重即为该路径的开销,此时显示从起点到B的最少开销是20,是通过A到达B的,则记录B的父节点是A。
遍历:
1)起点状态初始化
2)下一步去哪儿。选择开销最短的节点作为下一个遍历其邻接边的节点
3)对当前节点的处理。计算当前节点到其它节点的开销,如果出现更小的开销就更新2个表:开销散列表、父节点散列表
遍历结束:
4)根据开销表和父节点表,获取路径和最短开销
算法分解:
<1> 当前位置:A。最初,从起点开始遍历,开销表和父节点表处于初始状态。此时从起点可以到达的节点只有B、C,遍历A后,因开销表中C的开销最少,所以,下一步,前往C。

<2> 当前位置:C。此时,计算从C可以到达的邻接点的开销,如果有更少的开销,就更新开销表和父节点表。此时,从C到B只需要8,小于原先的20,那么更新表。遍历完C节点后,开销表中,除开已遍历的C节点,开销最短的节点是B,所以,下一步,前往B。
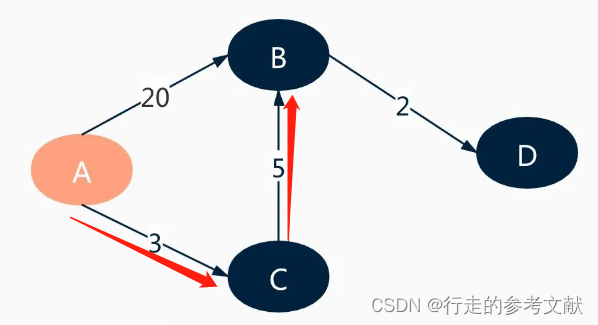
<3> 当前位置:B。与上一轮更新方法相同,更新表。因D节点即终点,遍历结束。
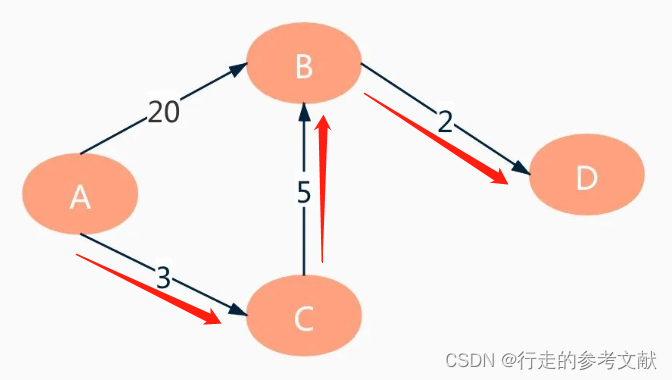
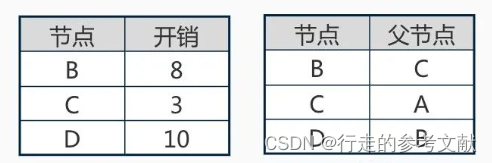
<4> 计算最短路径和最少开销。如开销表中记录,到终点D的最短开销是10。从父节点表中获取最短路径,终点D的父节点是B,B的父节点是C,C的父节点是起点A,所以,得到最短开销的路径是:A->C->B->D。
注:该算法适用于无向图和有向图,但不适用于带负权重的图
附:matlab代码
function [d, p] = dijkstra(adj, s, t)
% 使用dijkstra求最短路径
% adj 输入 矩阵 邻接矩阵
% s 输入 整数 起点
% t 输入 整数 或 [] 终点
% d 输出 向量 路径长度,若t==[],则返回从起点到所有节点的路径长度
% p 输出 向量 或 元胞 路径,若t==[],则返回从起点到所有节点的路径(cell)
nodes_num = size(adj, 1);
dist = inf(nodes_num, 1);
previous = inf(nodes_num, 1);
Q = [1:nodes_num]';
% 求邻居
neighbors = cell(nodes_num, 1);
for i = 1:nodes_num;
neighbors{i} = find(adj(i, :) > 0);
end
dist(s) = 0;
while ~isempty(Q)
% 取出距离最小点
[~, min_ind] = min(dist(Q));
min_node = Q(min_ind);
Q = setdiff(Q, min_node);
% 若是终点,则结束程序
if min_node == t
d = dist(min_node);
p = dijkstra_generate_path(previous, t);
return;
end
% 更新邻居的距离
for i = 1:length(neighbors{min_node})
neighbor = neighbors{min_node}(i);
alt = dist(min_node) + adj(min_node, neighbor);
if alt < dist(neighbor)
dist(neighbor) = alt;
previous(neighbor) = min_node;
end
end
end
d = dist;
p = cell(nodes_num, 1);
for i = 1:nodes_num;
p{i} = dijkstra_generate_path(previous, i);
end
end

















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











