







1.背景:
该版本在conductor进行了二次开发,目前验证发现其http task的执行非常高效,从这个角度发出分析下其实现原理(原生的http task的实现可参考 conductor server端源码解析(3)-systemTask )
2.http task:
实现了一个同步执行的http task实现类:
io.orkes.conductor.execution.tasks.HttpSync
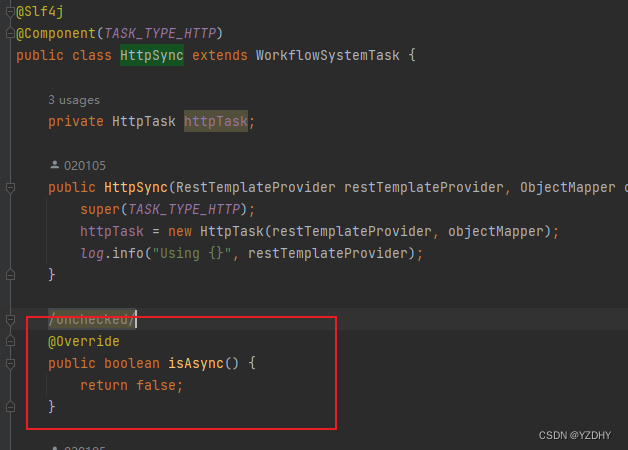
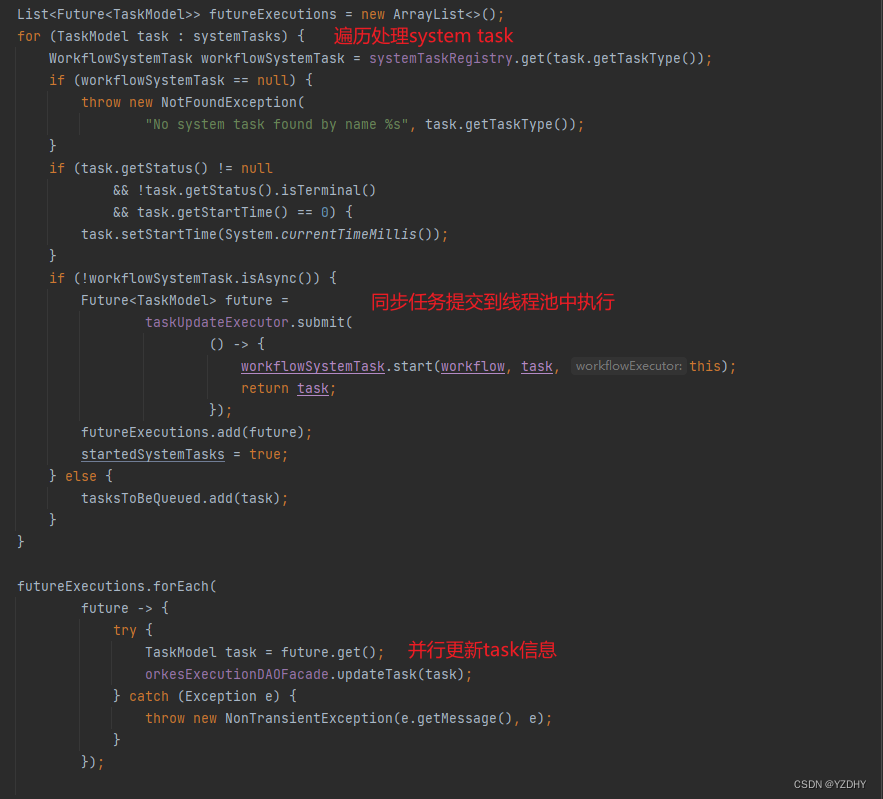
对同步执行的system task进行并行化处理,提交到现成池执行:
com.netflix.conductor.core.execution.OrkesWorkflowExecutor#scheduleTask
2.1 task的信息更新:
com.netflix.conductor.core.dal.ExecutionDAOFacade#updateTask
——> com.netflix.conductor.core.dal.ExecutionDAOFacade#updateTask
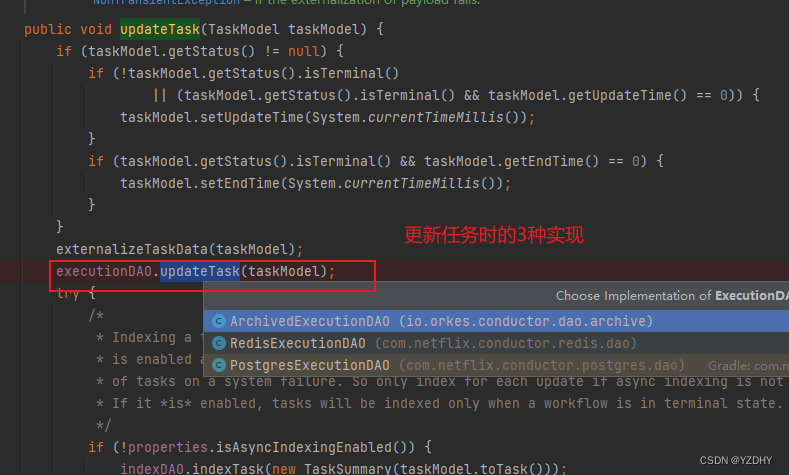
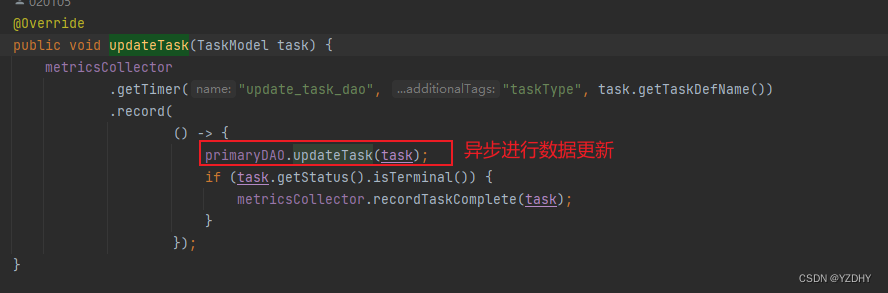
默认的归档实现:
io.orkes.conductor.dao.archive.ArchivedExecutionDAO#updateTask
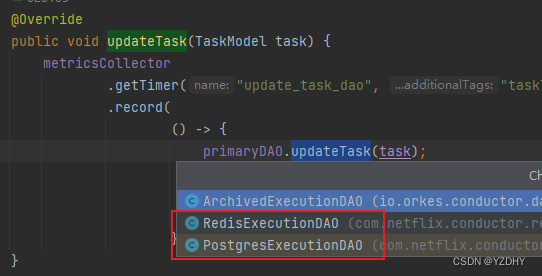
3.System Task的同步执行:
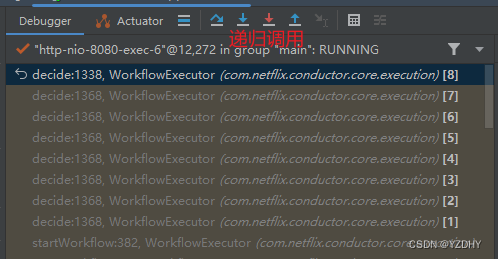
开始一个workflow实例(具体参考 conductor server端源码解析(5)-注册、启动一个流程 )是接收一个http请求开始的,会同步调用到
com.netflix.conductor.core.execution.WorkflowExecutor#decide
该方法是任务调度的核心,对于同步的http task而言,在此方法中递归完成整个workflow的执行
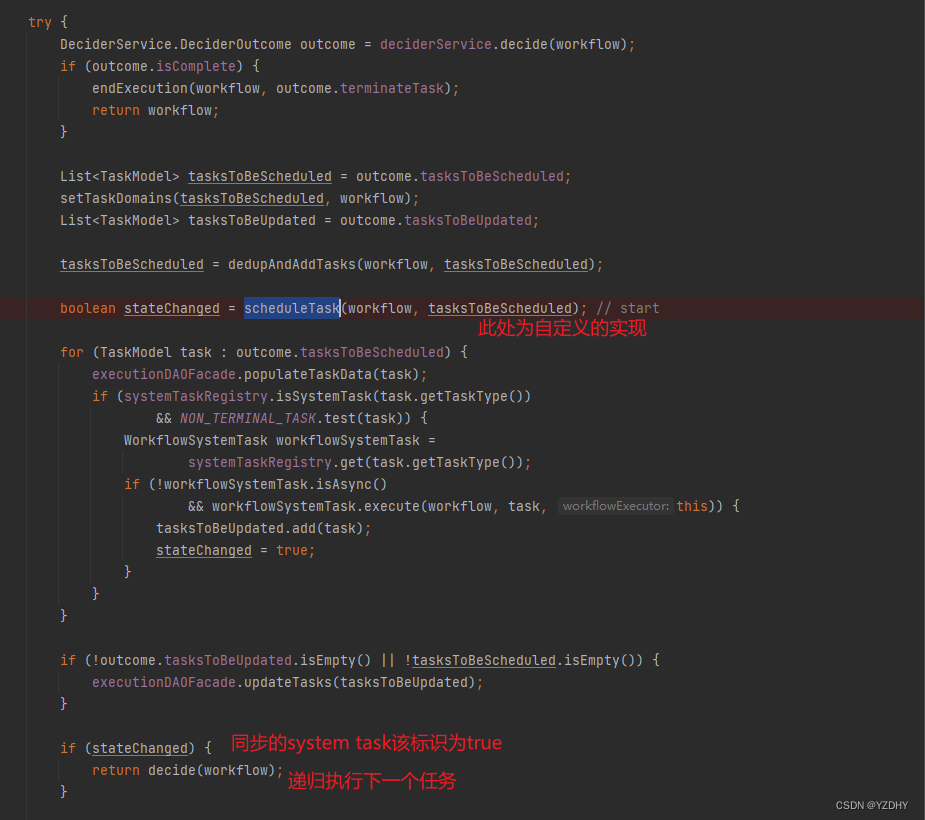
上图中的 scheduleTask() 方法 即为上一节中提到的:
com.netflix.conductor.core.execution.OrkesWorkflowExecutor#scheduleTask
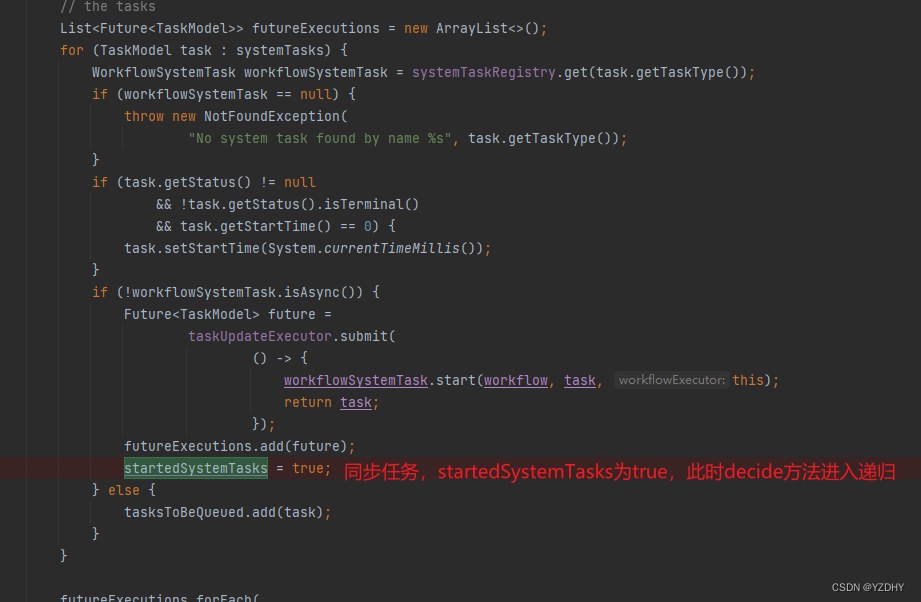
4.结论
orkes-conductor 的http-task的执行相比于原生conductor高效的原因是 将异步条用改成了同步调用,由server端完成流程中各节点的rpc调用;
个人认为,这是对conductor能力的增强,能在编排场景解决一些对执行耗时有一定要求的场景,但不不应作为主要场景使用,server端调用、递归执行,都会增加server端的负载。














 730
730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









