







Introduction
图像检测有两大挑战:
1. 需要处理大量的候选对象(proposals or candidate objects)
2. 提供的候选对象的位置通常是粗略的,需要修缮
本文一大特点:在single stage 进行model:区分proposal和其位置信息(spatial location)同时进行
RCNN缺点
- Training is a multi-stage pipeline:先ImageNet Classification欲训练,然后finetuning 训练目标检测网络,已提取特征。之后又使用svm分类器,最后进行 bounding-box regression。
- Training is expensive in space and time:
- Object detection is slow
RCNN 没有 sharing computation
Fast R-CNN contribution
- Higher detection quality (mAP) than R-CNN, SPPnet
- Training is single-stage, using a multi-task loss
- Training can update all network layers
- No disk storage is required for feature caching
Fast R-CNN architecture and training
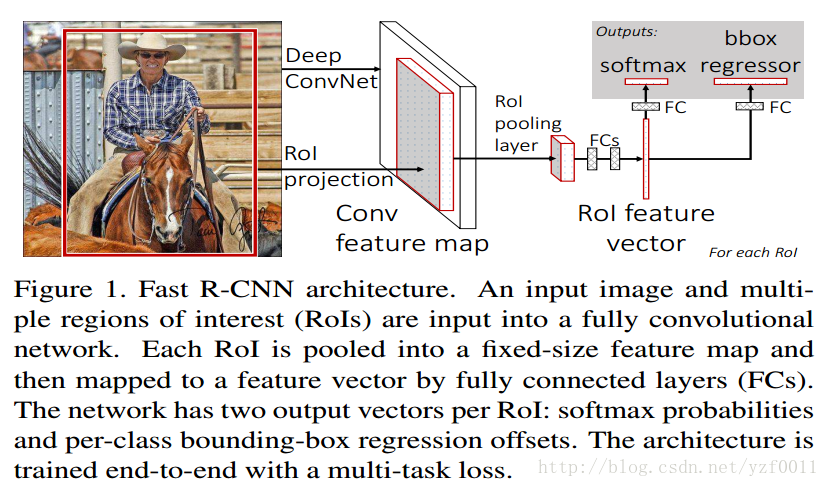
整体流程:
1. 从图片中使用selective选出候选区(proposals),差不多2k个左右。
2. 把它们输入到FCN(全卷积网络)中
3. 然后进过ROI pooling,以得到固定长度的feature vector 特征表示,输入到全连接网络中
4. 将得到的feature 一分为二,一个输入到proposal 分类的全连接,另一个输入到用于bounding box regression的全连接中去。
这是网上一个人总结的:Fast R-CNN论文详解
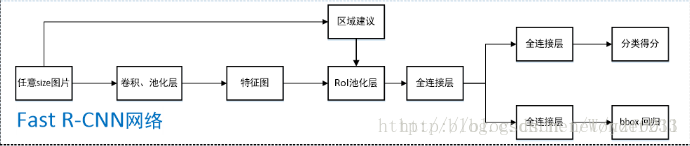
1. 任意size图片输入CNN网络,经过若干卷积层与池化层,得到特征图;
2. 在任意size图片上采用selective search算法提取约2k个建议框;
3. 根据原图中建议框到特征图映射关系,在特征图中找到每个建议框对应的特征框【深度和特征图一致】,并在RoI池化层中将每个特征框池化到H×W【VGG-16网络是7×7】的size;
4. 固定H×W【VGG-16网络是7×7】大小的特征框经过全连接层得到固定大小的特征向量;
5. 第4步所得特征向量经由各自的全连接层【由SVD分解实现】,分别得到两个输出向量:一个是softmax的分类得分,一个是Bounding-box窗口回归;
6. 利用窗口得分分别对每一类物体进行非极大值抑制剔除重叠建议框,最终得到每个类别中回归修正后的得分最高的窗口。
______________________________________________________________________________________________________________________________
2.1 The RoI pooling layer
我们都知道输入的size是可变的,但是FCN参数大小是不变的,所以输入到RoI poolinglayer的size也是千变万化的,但输入到FC(全连接)大小是固定的。如果我们继续使用传统的max pooling,那么输入到全连接的vector的size必将不匹配,那么该是如何是好?SPP 就是解决这样的问题,使得变化size的输入vector得到固定(fixed-size)size的输出。
______________________________________________________________________________________________________________________________
2.2 Initializing from pre-trained networks
作者预训练了3个网络CaffeNet,VGG_CNN_M_1024,VGG-16,以用来初始化fast R-CNN 网络参数。当初始化的时候需要经历3个过程:
1. 使用ROI pooling layer 代替最后一个maxpooling层。
2. 网络最后的全连接和softmax需要使用FC + softmax over categories 和 FC + categor-specific bounding-box regressors这两个相邻的层来代替
3. 网络输入修改为:以组图片以及这些图片上得到的RoIs(Region of Interests)。
______________________________________________________________________________________________________________________________
2.3 Fine-tuning for dectection
作者抛出了这样一个问题:SPPnet 不能够在spatial pyramid pooling layer之下来update parameter?
因为他们的输入(training samples)是不同,导致他们在BP(back propagation)时,是高度低效的。这种低效也源于他们的RoI拥有一个很大的接受域(receptive field), 甚至是整张图片(也就是说,在一个batch训练中,你一开始ROI源于这张图片,而下一个RoI源于另一张图片,……。如果ROI很大的话,这就导致在BP效率会很低)。
为了解决这样的问题,在同一个batch中训练,作者为了减少图片的使用量,做出了这样的调整:每个batch中,选择N张图片,再在每个图片中选择
R/N
个RoIs,这样就很好的解决了上述问题。试验中作者R=128, N=2,得到了不错的实验结果。
前面我们提到了在Single stage中完成我们的训练,但实际包含了:multi-task loss, mini-batch sampling, RoI pooling, BP throungh RoI pooling layers, SGD hyper-parameters.
Multi-task loss(摘自RCNN学习笔记(2):Fast R-CNN, 有修改)
Fast R-CNN网络分类损失和回归损失如下图所示【仅针对一个RoI即一类物体说明】,黄色框表示训练数据,绿色框表示输入目标:
上图画错的是绿色Label只有1个,不可能是
1∗(K+1)
个(因为1个Proposal 只会有一个ground truth 以及对应的类别), 还有黄色的bbox_predict为
K∗4
个(论文中有)
-cls_score层用于分类,输出K+1维数组
p(p0,p1,...pK)
,表示属于背景和K类物体的概率;
-bbox_predict层用于调整候选区域位置,输出4*K维数组,也就是说对于每个类别都会训练一个单独的回归器;
对于每个ROI输出一个离散的离散类别概率分布
p(p0,p1,...pK)
和4k个可能的Boundding-box回归位移
tk=(tkx,tky,tkw,tkh),k∈K
, 这样作者得到了一个由classification和bounding-box regression联合的损失函数:
从上面我们可看出背景proposal是不纳入计算bounding-box regression损失的。
Mini-batch sampling
如何sampling,前面提过。在2张图片中每张sample64个RoI
正反样本比例和IOU(intersection over union)大小
| 类别 | 比例 | 方式 |
|---|---|---|
| 前景 | 25% | 与ground-truth bbox边界框重叠区间在[0.5,1] |
| 背景 | 75% | 与ground-truth bbox边界框重叠区间在[0.1,0.5) |
Back-propagation through RoI pooling layers.
说实话,我也不知道如何求导,论文中作者描述的也让我精神错乱。
从这篇借鉴理解RoI池化层:Fast R-CNN论文详解
首先看普通max pooling层如何求导,设xi为输入层节点,yi为输出层节点,那么损失函数L对输入层节点xi的梯度为:
δ Lδ xi={0,δ Lδ yj,δ(i,j)=falseδ(i,j)=true
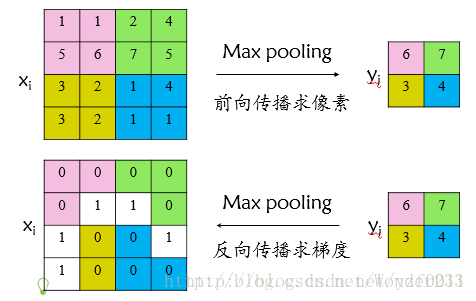
其中判决函数δ(i,j)表示输入i节点是否被输出j节点选为最大值输出。
不被选中【δ(i,j)=false】有两种可能:xi不在yi范围内,或者xi不是最大值。
若选中【δ(i,j)=true 】则由链式规则可知损失函数L相对xi的梯度等于损失函数L相对yi的梯度×(yi对xi的梯度->恒等于1),故可得上述所示公式;
对于RoI max pooling层,设xi为输入层的节点,yri 为第r个候选区域的第j个输出节点,一个输入节点可能和多个输出节点相关连,如下图所示,输入节点7和两个候选区域输出节点相关连;
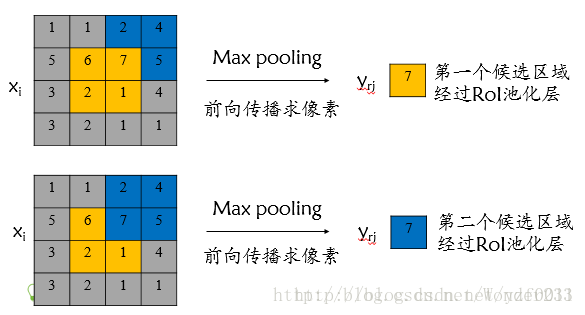
该输入节点7的反向传播如下图所示。
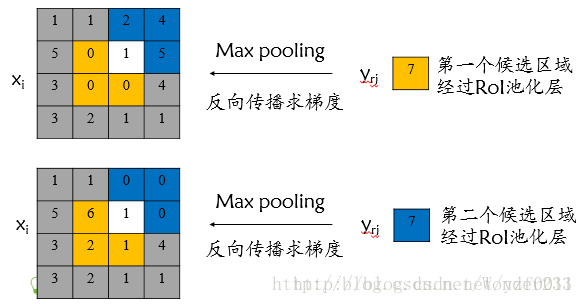
对于不同候选区域,节点7都存在梯度,所以反向传播中损失函数 L 对输入层节点 xi 的梯度为损失函数 L 对各个有可能的候选区域 r 【 xi 被候选区域r的第j个输出节点选为最大值 】输出 yri 梯度的累加,具体如下公式所示:
判决函数 [i=i∗(r,j)] 表示 i 节点是否被候选区域r 的第j 个输出节点选为最大值输出,若是,则由链式规则可知损失函数L相对 xi 的梯度等于损失函数 L 相对 yri 的梯度×( yrj 对 xi 的梯度->恒等于1),上图已然解释该输入节点可能会和不同的 yrj 有关系,故损失函数L相对 xi 的梯度为求和形式
______________________________________________________________________________________________________________________________
SGD hyper-parameter.
也就是参数选择
除了修改增加的层,原有的层参数已经通过预训练方式初始化:
用于分类的全连接层以均值为0、标准差为0.01的高斯分布初始化;
用于回归的全连接层以均值为0、标准差为0.001的高斯分布初始化,偏置都初始化为0;
针对PASCAL VOC 2007和2012训练集,前30k次迭代全局学习率为0.001,每层权重学习率为1倍,偏置学习率为2倍,后10k次迭代全局学习率更新为0.0001;
动量设置为0.9,权重衰减设置为0.0005。
______________________________________________________________________________________________________________________________
Scale invariance
实现尺度不变有两种方式:
1. “brute force”(单一尺度,原图)
2. “image pyramids”(经过尺度变换)
image pyramids 是当我们的数据量少的时候,一种增加数据的方式(augmentation).
______________________________________________________________________________________________________________________________
Fast R-CNN detection
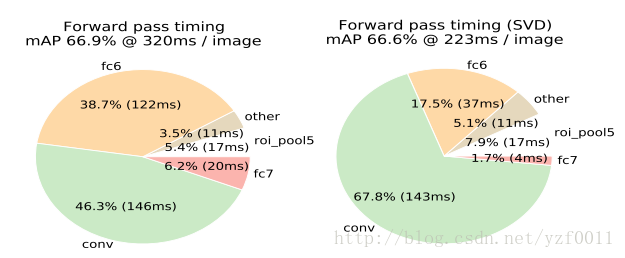
Truncated SVD for faster detection
这里作者只是想减少检测的时间。在全连接层使用SVD来代替全连接层权重W,因为参数大量减少,导致计算量减少,速度会加快,是一种压缩的思想(compression)
______________________________________________________________________________________________________________________________
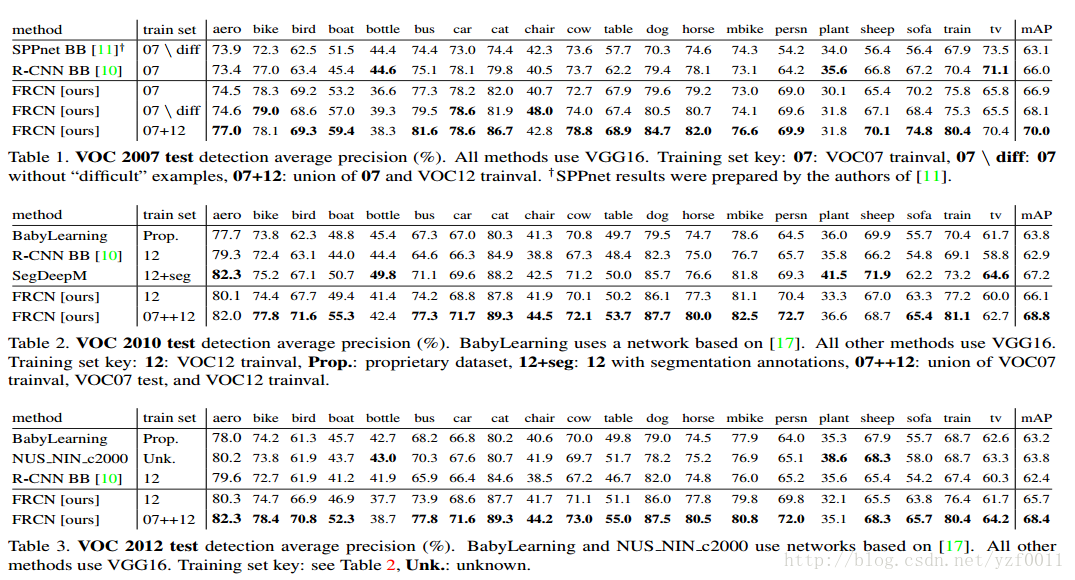
Main results
average precision
______________________________________________________________________________________________________________________________
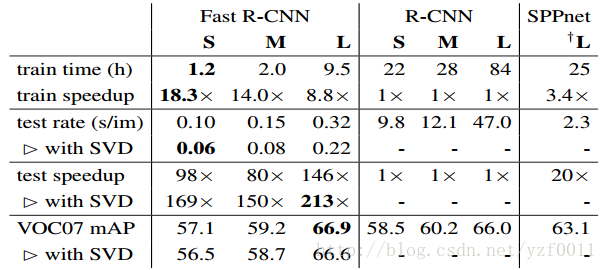
Training and testing time
______________________________________________________________________________________________________________________________















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









