









欠拟合、过拟合
在线性回归问题中,我们可以通过改变
θ的个数或者x的指数大小来获得不同形状的拟合曲线
看下面的图:
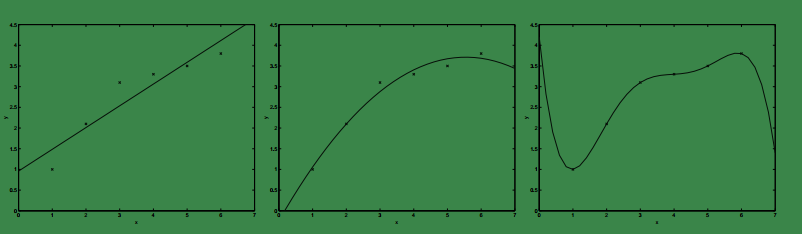
左边的曲线是在假设
y=θ0+θ1x
时的拟合结果,但显然中间的曲线要比左边的拟合效果更好。我们称左边的情况为欠拟合(underfitting)。
这样看来右边的不是比左边更好吗?!。。。NO!我们称右边的情况为过拟合(overfitting)!因为它已经不能反应出样本的整体分布情况!
局部加权线性回归(LWR)
在之前的线性回归中,我们的流程是:
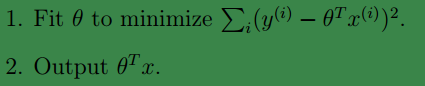
现在,在LWR中,与上面的不同之处只是在代价函数中加了个非负的权值
w(i)
:
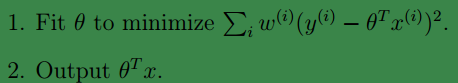
当我们给w(i)一个很大的值时,在计算选择θ时,就会更加...更加尽可能的让(y(i)−θTx(i))2的值小。也就是说我们更加重视第i个样本。同理,当w(i)很小很小时,也就代表我们基本可以忽略第i个样本
一般而言我们选择权重w的规则如下:
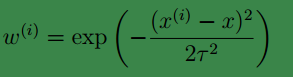
其中x是要预测的样本,可以看出:当|x(i)−x|越小时,权重w(i)越接近1;当|x(i)−x|越大时,权重w(i)越接近0
其实可以理解为:对于距离非常大的样本,我们更加倾向于将其当成噪声。
但是他有一个缺点:每次预测时都要重新计算预测样本与“参考样本”(训练样本)的距离,确定新的权重。因此当训练样本量很大时,该方法效率很低。
在上式中,
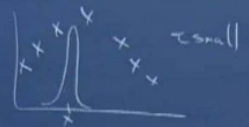
τ称为波长(bandwidth)参数,它控制了权值大小相对于距离的变化速度,τ越小,w变化越快;τ越大,w变化越慢。
















 1282
1282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









