









聚类就是将样本{ x1,x2,...xn }按照属性分类,注意这里样本的表已经不再是(x,y)了,现在只有属性x,因此聚类属于非监督学习法。
K-means聚类,就是将样本分为k类,其思想是:
1、先随机选择k个聚类中心(即随机选择k个样本)
2、将每个样本划分到与它距离最小的中心所属类别
3、根据2划分的结果重新计算k个聚类中心(每个类别中所有样本的均值)转到2,直至收敛
算法描述如下:

上面k表示我们要将样本分为k类,我们有k个聚类中心,
μj
代表第当前迭代中的j个聚类中心。
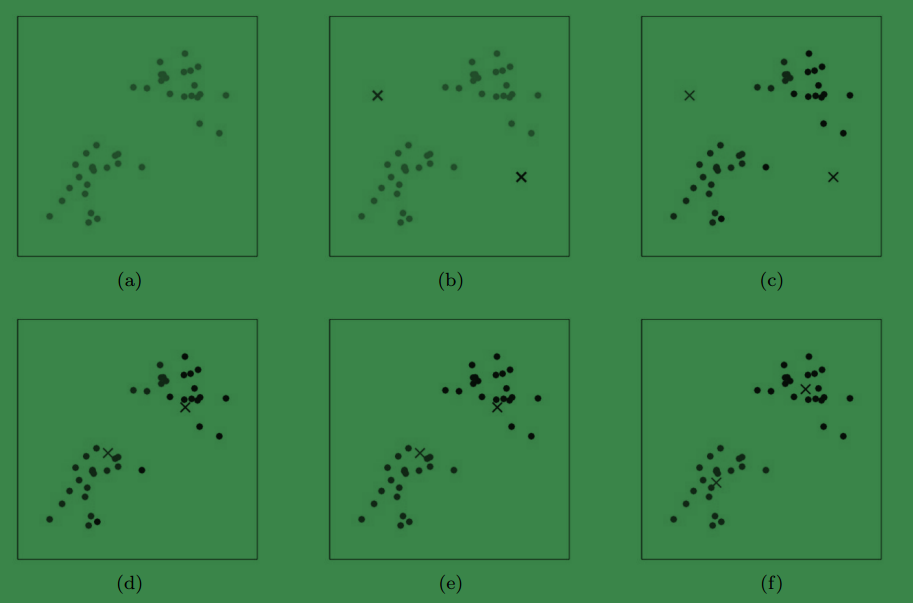
上图是2个聚类中心的情况,a是原始样本,b中随机选择了两个聚类中心(这里并没有选取样本来初始化,而是任意选择了两个点),cdef是每次迭代逐渐收敛的过程。
下面我们来看看,k-means是否收敛,定义畸变函数:
J(c,μ)=∑i=1m||x(i)−μc(i)||2
可以看出 J 就是每个类别中所有样本
由于畸变函数 J 是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说 k-means 对质心初始位置的选取比较感冒,但一般情况下 k-means 达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍 k-means,然后取其中使得 J(c,μ) ,以该 μ 作为初始化的聚类中心,最终得到聚类中心c。















 5127
5127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









