









转载 http://www.cnblogs.com/jerrylead自己也做了些添加修改
问题
之前我们考虑的训练数据中样例
x(i)
的个数 m 都远远大于其特征个数 n,这样不管是进行回归、聚类等都没有太大的问题。然而当训练样例个数 m 太小,甚至
m<<n
的时候,使用梯度下降法进行回归时, 如果初值不同, 得到的参数结果会有很大偏差(因为方程数小于参数个数)。另外,如果使用多元高斯分布(Multivariate Gaussian distribution)对数据进行拟合时,也会有问题。让我们来演算一下,看看会有什么问题:
多元高斯分布的参数估计公式如下:
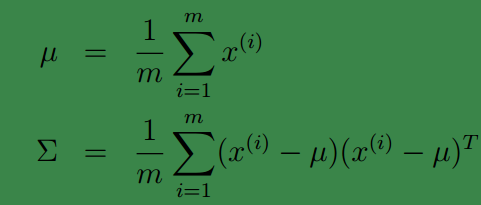
它们分别是求 mean 和协方差的公式,
x(i)
表示样例,共有 m 个,每个样例 n 个特征,因此
μ
是 n 维向量,
Σ
是
n×n
协方差矩阵。
当
m<<n
时, 我们会发现Σ是奇异阵
(|Σ|=0)
,也就是说
Σ−1不
存在,没办法拟合出多元高斯分布了,确切的说是我们估计不出来
Σ
。
如果我们仍然想用多元高斯分布来估计样本,那怎么办呢?
限制协方差矩阵
当没有足够的数据去估计
Σ
时,那么只能对模型参数进行一定假设,之前我们想估计出完全的
Σ
(矩阵中的全部元素),现在我们假设
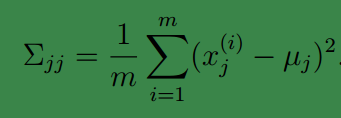
回想我们之前讨论过的二维多元高斯分布的几何特性,在平面上的投影是个椭圆,中心点由
μ
决定,椭圆的形状由
有时我们还会给协方差矩阵更大的限制,可以假设对角线上的元素都是等值的,即:
其中
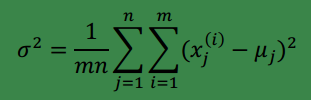
此时高斯分布的轮廓图由椭圆变成圆(在二维上)。
当我们要估计出完整的
Σ
时,我们需要
这样做的缺点也是显然易见的,我们认为特征间独立,这个假设太强。
接下来,我们给出一种称为因子分析的方法,使用
边缘和条件高斯分布
在讨论因子分析之前,先看看多元高斯分布中条件和边缘高斯分布的求法。这个在后面因子分析的 EM 推导中有用。
假设
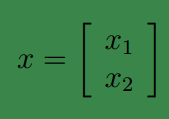
其中
x1∈Rr,x2∈Rs
,
x∈Rr+s
。假设
x
服从多元高斯分布

其中
μ1∈Rr,μ2∈Rs
,那么
Σ11∈Rr×r,Σ12∈Rr×s
,由于协方差矩阵是对称阵,因此
Σ12=ΣT21
。
这说明 x1 和 x2 的联合分布符合多元高斯分布。
begin-补充-边缘概率
如果我们把每一个变量的概率分布称为一个概率分布,那么边缘分布就是若干个变量的概率加和所表现出的分布。举个例子,假设 P(B),P(C),P(A|B),P(A|C) 已知,求 P(A) 。那么 P(A)=sum(P(B)∗P(A|B)+P(C)∗P(A|C)) 。
再举个简单的例子:对于一个任意大小(n*n)的概率矩阵X,每一个元素表示一个概率,对于其中任一行或任一列求和,得到的概率就是边缘概率。如果写成式子,就是第i行有以下边缘分布: P(i)=sum(P(i,j),foreachjinn) 。
对,定义就是这么简单。就是指的某一些概率的加和值的分布,其实就对应一个等式,让它等于某种概率加和运算。
end-补充
那么只知道联合分布的情况下,如何求得
x1
的边缘分布呢?从上面的
μ
和
第一个很明显就能得到,第二个也不难理解,我们来看下第二个怎么得到的:
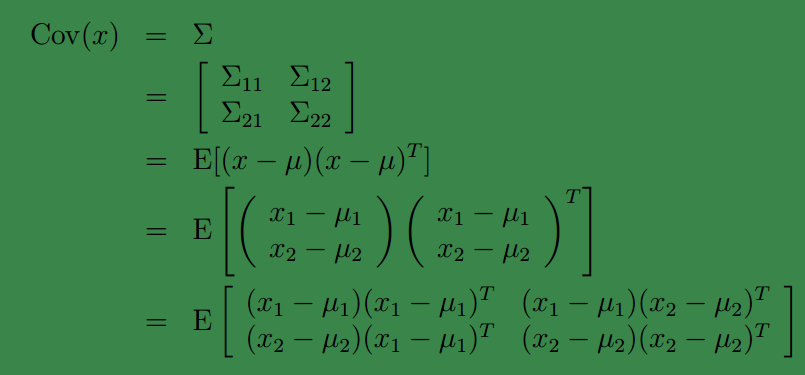
由此可见, 多元高斯分布的边缘分布仍然是多元高斯分布。也就是说
x1∼N(μ1,Σ11)
.
上面 Cov(x) 里面的 Σ12 评价的是两个随机向量之间的关系。比如 x1 ={身高,体重}, x2 ={性别,收入},那么 Σ11 求的是身高与身高,身高与体重,体重与体重的协方差。而 Σ12 求的是身高与性别,身高与收入,体重与性别,体重与收入的协方差,反映了 x1与x2 之间的某些属性的关联度,当 Σ12 越小说明构成 Σ12 的各个属性间的关联度越小。
上面求的是边缘分布,让我们考虑一下条件分布的问题,也就是
x1|x2
的问题。根据多元高斯分布的定义,
x1|x2∼N(μ1|2,Σ1|2)
.
且:
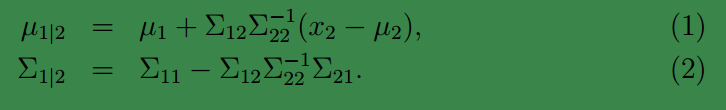
这是我们接下来计算时需要的公式,这两个公式直接给出,没有推导过程。如果想了解具体的推导过程,可以参见 Chuong B. Do 写的《 Gaussian processes》。
因子分析例子
下面通过一个简单例子,来引出因子分析背后的思想。
因子分析的实质是认为
m
个
1、 首先在一个
k
维的空间中按照多元高斯分布生成
2、 然后存在一个变换矩阵 ∧∈Rn×k ,将 z(i) 映射到 n 维空间中,即:
因为 z(i) 的均值是0(因为 z(i)∼N(0,I) ),映射后均值仍然是 0
3、 然后将
∧z(i)
加上一个均值
μ
(
对应的意义是将变换后的 ∧z(i)(n 维向量)中心移动到变换后样本的均值处.
4、 由于真实样例
x(i)
与上述模型生成的有误差,因此我们继续加上误差
ϵ
(
5、 最后的结果认为是真实的训练样例 x(i) 的生成公式:
让我们使用一种直观方法来解释上述过程:
假设我们有 m=5 个 2 维的样本点
x(i)
(两个特征),如下:
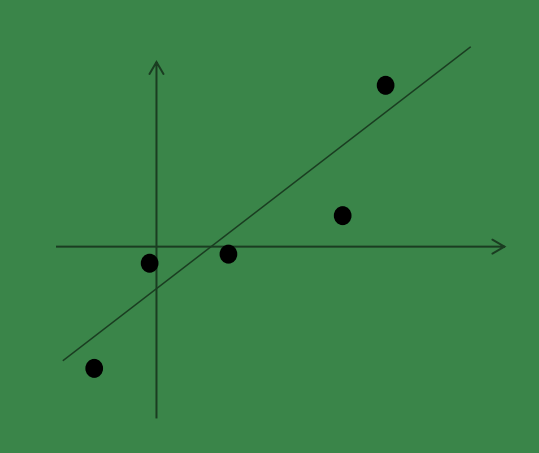
那么按照因子分析的理解,样本点的生成过程如下:
1、 我们首先认为在 1 维空间(这里 k=1), 存在着按正态分布生成的 m 个点
z(i)
,如下:

均值为0,方差为1.
2、 然后使用某个
∧=(a,b)T
将一维的
z
映射到 2 维,图形表示如下:
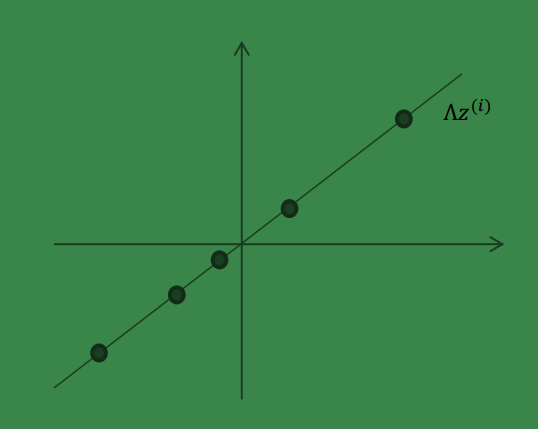
3、 之后加上
μ(μ1,μ2)T
,即将所有点的横坐标移动
μ1
,纵坐标移动
μ2
,将直线移到一
个位置,使得直线过点
μ
,原始左边轴的原点现在为
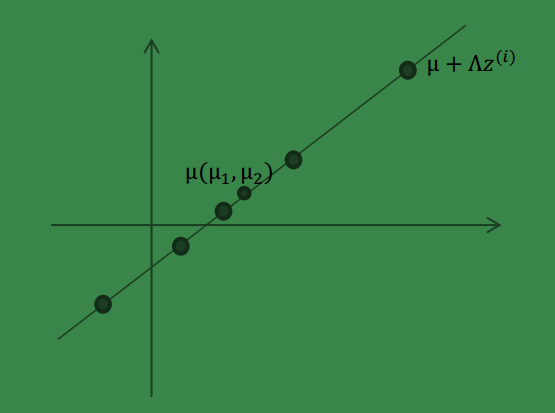
然而,样本点不可能这么规则,在模型上会有一定偏差, 因此我们需要将上步生成
的点做一些扰动(误差),扰动
ϵ∼N(0,Ψ)
。
4、 加入扰动后,我们得到黑色样本
x(i)
如下:
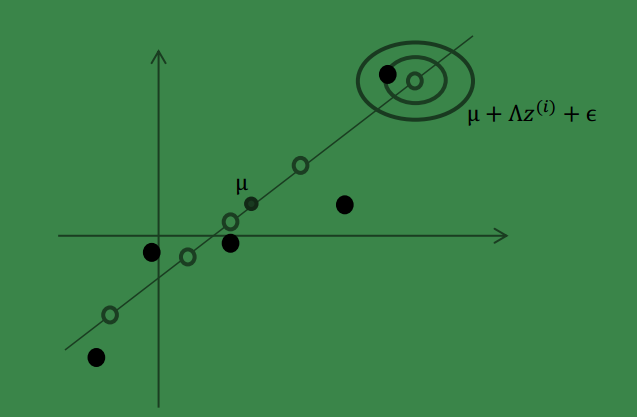
5、 其中由于
z
和
ϵ
的均值都为 0, 因此
由以上的直观分析,我们知道了因子分析其实就是认为高维样本点实际上是由低维样本点经过高斯分布、线性变换、误差扰动生成的,因此高维数据可以使用低维来表示。
因子分析模型
上面的过程是从隐含随机变量
z
经过变换和误差扰动来得到观测到的样本点。其中 z被称为因子,是低维的
我们将式子再列一遍如下:
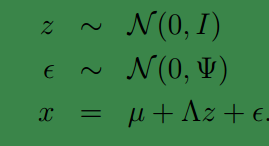
其中误差
下面使用的因子分析表示方法是矩阵表示法,在参考资料中给出了一些其他的表示方法,如果不明白矩阵表示法,可以参考其他资料。
矩阵表示法认为
z
和
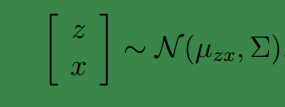
下面我们将求
μzx和Σ
首先我们知道
E[z]=0,E[ϵ]=0
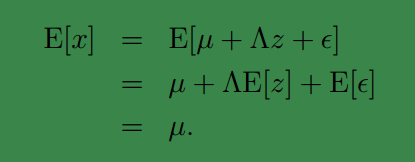
因此
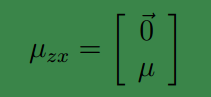
下一步是计算
Σ
:
我们需要获得:
由于
z∼N(0,I)
,我们容易得到
Σzz=Cov(z)=I
,以及:
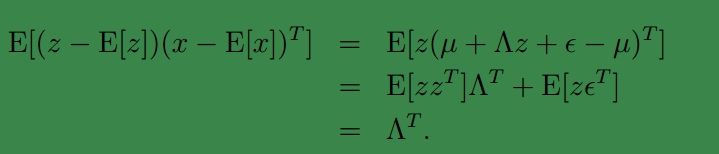
这个过程中利用了
E[zzT]=Cov(z)
(因为z的均值是0) ,以及
E[zϵT]=E[z]E[ϵT]=0
(基于
z
和
ϵ
独立假设,
接着求
Σxx
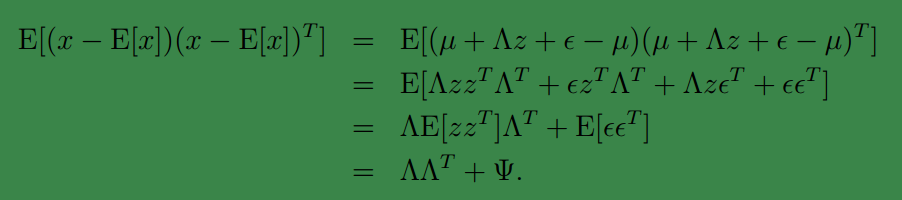
然后得出联合分布的最终形式
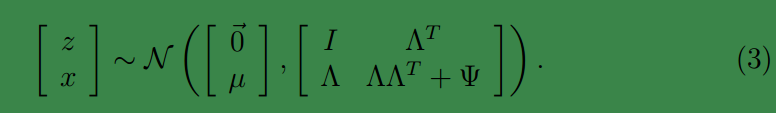
从上式中可以看出
x
的边缘分布
那么对样本{
x(i);i=1,…,m
}进行最大似然估计
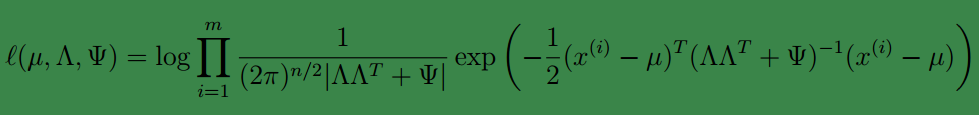
然后对各个参数求偏导数不就得到各个参数的值了么?
可惜我们得不到 closed-form。想想也是,如果能得到,还干嘛将 z 和 x 放在一起求联合分布呢。根据之前对参数估计的理解,在有隐含变量 z 时,我们可以考虑使用 EM 来代替求最大似然值的方法进行估计。
因子分析的 EM 估计
我们先来明确一下各个参数,
z
是隐含变量,
E步就是要计算:
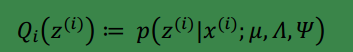
根据第 3 节的条件分布讨论,
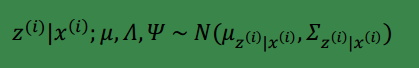
因此
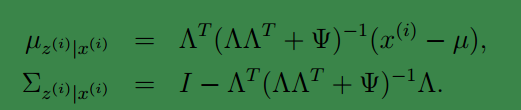
那么根据多元高斯分布公式,得到E步的计算公式:
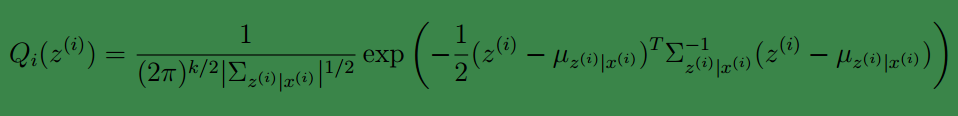
下面来看M步:
M步最大化的目标是:
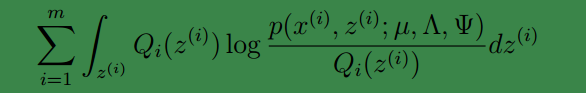
其中待估参数是
µ,Λ,Ψ
,
loge,lne
在这里并没有区别
loge=1
下面我们重点求
Λ
的估计公式
首先将上式简化为:
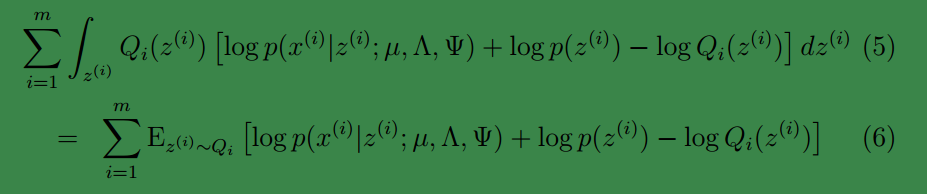
这里
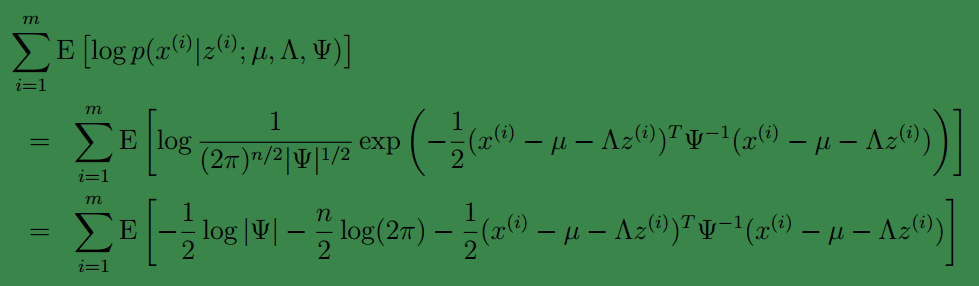
去掉不相关的前两项后,对
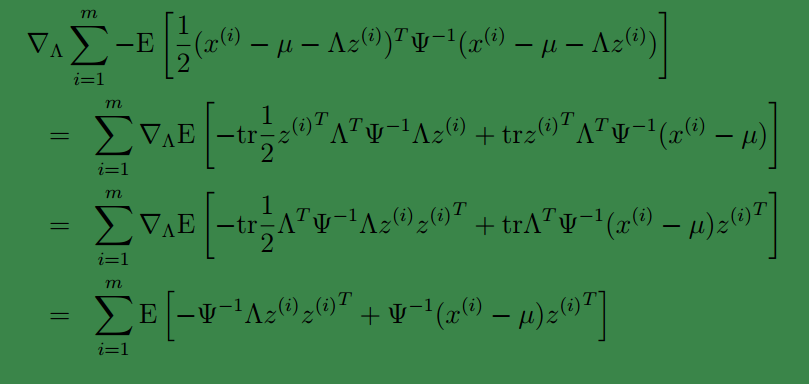
第一步到第二步利用了
tr a=a
( a 是实数时)和 tr AB = tr BA。最后一步利用了
∇AtrABATC=CAB+CTABT
tr 就是求一个矩阵对角线上元素和。
最后让其值为 0,并且化简得:
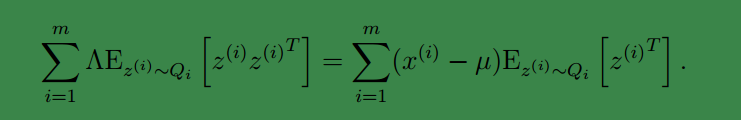
然后得到
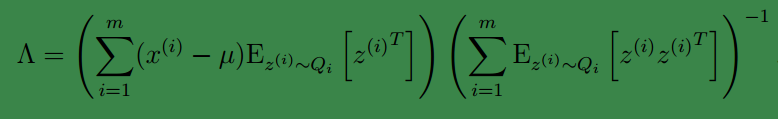
到这里我们发现,这个公式有点眼熟,与之前回归中的最小二乘法矩阵形式类似:
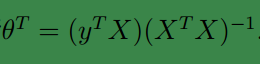
这里解释一下两者的相似性,我们这里的
x
是
到这还没完,我们需要求得括号里面的值
根据我们之前对
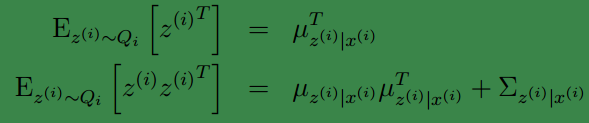
第二个式子是根据:
Cov(Y)=E[YYT]−E[Y]E[Y]T
即
E[YYT]=E[Y]E[Y]T+Cov(Y)
得到的。
此时可得:
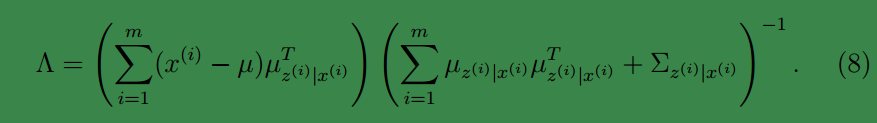
至此,我们得到了
Λ
,注意一点是
其他参数的迭代公式如下:
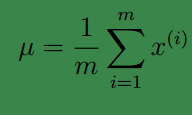
均值
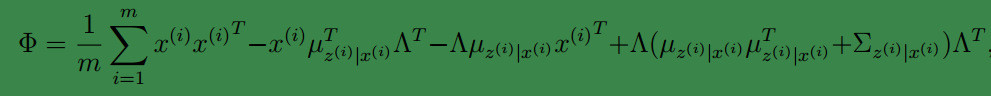
然后将
Φ
上的对角线上元素抽取出来放到对应的
总结
根据上面的EM的过程,要对样本
因子分析实际上是降维,在得到各个参数后,可以求得
z
。但是
下面从一个 ppt 中摘抄几段话来进一步解释因子分析。
因子分析(factor analysis)是一种数据简化的技术。它通过研究众多变量之间的内部依赖关系,探求观测数据中的基本结构,并用少数几个假想变量来表示其基本的数据结构。这几个假想变量能够反映原来众多变量的主要信息。原始的变量是可观测的显在变量,而假想变量是不可观测的潜在变量,称为因子。
例如,在企业形象或品牌形象的研究中,消费者可以通过一个有 24 个指标构成的评价体系,评价百货商场的 24 个方面的优劣。
但消费者主要关心的是三个方面,即商店的环境、商店的服务和商品的价格。因子分析方法可以通过 24 个变量,找出反映商店环境、商店服务水平和商品价格的三个潜在的因子,对商店进行综合评价。而这三个公共因子可以表示为:
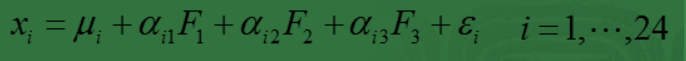
这里的
xi
就是样例
x
的第
称
Fi
是不可观测的潜在因子。
24
个变量共享这三个因子,但是每个变量又有自己的个性,不被包含的部分
ϵi
,称为特殊因子。
注:
因子分析与回归分析不同,因子分析中的因子是一个比较抽象的概念,而回归因子有非常明确的实际意义;
主成分分析分析与因子分析也有不同,主成分分析仅仅是变量变换,而因子分析需要构造因子模型。
主成分分析:原始变量的线性组合表示新的综合变量,即主成分;
因子分析:潜在的假想变量和随机影响变量的线性组合表示原始变量。
PPT 地址
http://www.math.zju.edu.cn/webpagenew/uploadfiles/attachfiles/2008123195228555.ppt
其他值得参考的文献
An Introduction to Probabilistic Graphical Models by Jordan Chapter 14















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









