






随着 AI 技术发展,向量指令在微处理器上逐渐显现出它的重要性,例如自动驾驶、图像识别,这些技术都需要使用矩阵和向量进行运算。相较于标量单时钟周期内只能一次计算,矢量处理能够对多组数据进行成批计算,意味着矢量毫无疑问成为未来的发展方向。
RISC-V 属于一种基于既定精简指令集计算机(RISC)原理的开放标准指令集架构,始于2010年加州大学伯克利分校。在众多的指令架构中,RISC-V 由于他的开放性和可扩展性吸引了一大批编译器开发者,其中矢量指令集 RISC-V Vector 指令集由此诞生。与传统 Arm 的 SIMD 指令不同,RISC-V Vector 指令更加灵活,且对开发工程师更加友好。
RISC-V 常见扩展有:
• M. Integer multiplication and division (mul, div, rem, …)
• A. Atomic instructions(load reserve + store conditional, atomic read-modify-write)
• F. Single-Precision Floating-Point (IEEE 754 Binary32)
• D. Double-Precision Floating-Point (IEEE 754 Binary64)
• C. Compressed Instructions (16-bit encodings for common I/F/D instructions)
• Zb*. RISC-V Bit-Manipulation ISA-extensions
• Zfh*. "Zfh" and "Zfhmin" Standard Extensions for Half-Precision Floating-Point
完整详见Specifications – RISC-V International
RISC-V Vector 基本介绍
RISC-V Vector 拥有其他架构矢量指令没有的两大优点:硬件维护方便与指令长度可变。对于某一个矢量操作,即使硬件中的寄存器长度变化,代码也不需要作更改,相反的,在同一硬件中,即使指令长度作相应改变,代码也不需要更改。这意味着任何 RISC-V 兼容处理器编写的代码在其余 RISC-V 处理器上依然适用,这对于用户来说,简易性直线上升。
此两大优点得益于 RISC-V Vector 的 vset(i)vl(i) 指令机制,在面对不同的寄存器大小以及数据长度的时候,vset(i)vl(i) 指令会设置其中的 vl 以及 vtype 来面对不同情况。其中 RISC-V Vector 通过7个 CSR 寄存器来共同处理指令的多样性,分别为 vstart、vxsat、vxrm、vcsr、vl、vtype、vlenb。
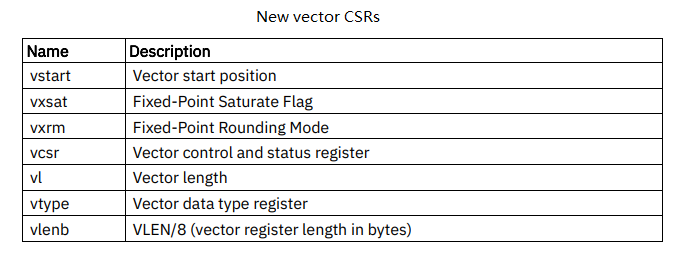
vstart:开始位置的索引
vxsat:定点饱和标志
vxrm:定点数舍入模式
vcsr:矢量状态控制寄存器
vl:矢量长度寄存器
vtype:矢量数据属性寄存器
vlenb:矢量寄存器长度
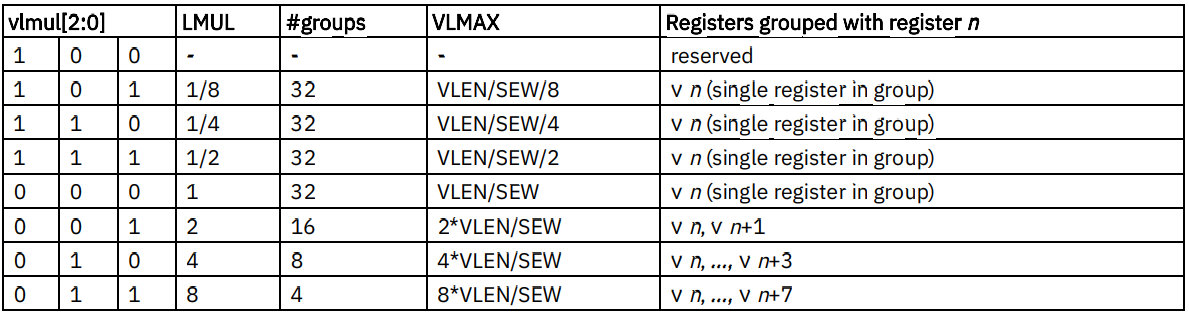
其中,vl 以及 vtype 是用户涉及最多的寄存器,vl 通过 vset(i)vl(i) 来计算指令向量长度,vtype 则是包含 vill、vma、vta、vlmul、vsew 几个字段来表示各指令中元素属性,例如:vill 是非法标志符,如果值为1,则其他几个字段失效;vma 掩码位;vmul 段代表向量寄存器分组,可以是分数可以是整数,整数n代表n个寄存器为一组进行计算,分数1/n代表1个寄存器拆分成n个寄存器进行计算;vsew 代表元素宽度。
vtype 中 vlmul 和 vsew 主要影响 vlmax 的值,而 vlmax 影响每次处理元素的数量,vl = min (vlmax, AVL)。其中 AVL 全称 Application Vector Length,表示应用程序指定要处理的元素总数。
vset(i)vl(i) 这类指令在使用上一般是 vl 或者 vtype 发生改变时才会去使用。但是实际上 LLVM 在这一块处理并不完善,如果写 instrinsic 测试就会发现,如果指令可能涉及 vl 或者 vtype 变动,它很有可能会在变动前插入一条 vset(i)vl(i) 来保证正确性,即使现已存在 VSRVLI pass 判断 vtype 块前块后是否一致来减少部分 vset(i)vl(i) 插入,但反向推导的过程中可以发现一些 vset(i)vl(i) 是冗余的,所以这块社区还在不断地演进中。
对于 RISC-V Vector 指令的应用现有 NX27V 芯片、C906 芯片、SG2042 芯片、siFive Performance 系列芯片等,其中 NX27V 芯片、siFive Performance 系列芯片支持 RISC-V Vector 1.0 版本,但是 C906、SG2042 芯片支持的是 RISC-V Vector SPEC 0.7.1版本,与现在上游编译器 RISC-V Vector SPEC 1.0 版本不兼容。现社区有 RISC-V Vector rollback 脚本,可将 RISC-V Vector Extension v1.0 的汇编代码转换为 v0.7.1,因此上游编译器代码编出的 .s 中的 RVV SPEC v1.0 版本指令可通过此脚本转换成 RISC-V Vector SPEC v0.7.1 标准指令,这样就可以将代码最终执行在 C906、SG2042 芯片上。
当然,其他架构也存在矢量指令,例如 Arm 架构的 Neon,虽然 Neon 和 RISC-V Vector 同为矢量指令,但是 Neon 是固定长度的矢量指令,这会存在一个问题,即指令越加越多,复杂度提升,且需要绑定特定的硬件配置,而 RISC-V Vector 相较于 Neon,它有 vsetvli 可以适配宽度和判断循环次数,只需在执行前给予总的数据量即可。例如一段 memory copy 对于 Arm 的代码部分,LDP 和 STP 分别为128位宽的 load 和 store 操作,每次循环操作96个字节。宽度固定,数据变化代码可能就需大改(Arm SVE 解决这个问题)。
RISC-V Vector 在 LLVM 社区中演进
从2019年底开始,LLVM 社区开始实现 RISC-V Vector SPEC 功能,从汇编侧开始,从IR向后端,最后延至前端。至 LLVM15 已基本实现 RISC-V Vector 1.0 全部内容。
从使用上来看,从 LLVM12 开始支持 RISC-V Vector Intrinsic,前端接口使用 tablegen 进行生成,在 riscv_vector.td 中定义前端指令生成 builtin 接口,此接口头文件会存在工具链的 lib/clang/12.0.1/include/riscv_vector.h,此文件包含 RISC-V Vector 所有的前端 builtin 接口(只是生成所有接口,但部分接口的功能还不能完整支持),直至 LLVM 12.0.1 版本已经能正常支持 RISC-V Vector 0.10版本的大部分指令,此时 v 指令还是处于试验阶段,所以需要加入选项 -menable-experimental-extensions 进行支持,此时半精度浮点 float 16 支持是存在一定的问题。但由于此文件将所有类型全部写在头文件中,导致头文件巨大。对于一些无返回值的接口,即使使用变量接收返回值也是不会报错的只会报 warning,到 LLVM15 时 return-type 已设置成 error 了,所以当遇到此错误时,需要把返回类型改成 void 或者加上 -Wno-return-type。
升级至 LLVM15 后,RISC-V Vector 采用 OpenCL 动态检验接口方式(⚙ D111617 [RISCV] Lazily add RVV C intrinsics.),原先的 riscv_vector.h 接口只有类型没有完整的静态接口,只是因为 RISC-V Vector 现在根据 tablegen 生成的 clang/Basic/riscv_vector_builtin_sema.inc 文件去读取指令前缀,然后在运行时通过 clang/lib/Sema/SemaRISCVVectorLookup.cpp 文件中 InitRVVIntrinsic 函数进行拼接加入到 map 中以此生成 RISC-V Vector 接口表,此函数会自动为接口添加 _builtin_rvv_ ,所以在使用时不能再添加,否则会重复添加导致找不到接口,例如 vrgather_vv_i8mf8(op1, index, vl),而不是 _builtin_rvv_vrgather_vv_i8mf8(op1, index, vl),和以前的接口使用是有差异的,此时文件很小,这个优化方式不仅减小了最后的编译器工具链大小,也加快了运行时编译速度。
此时,已实现 RISC-V Vector 1.0 版本,半精度浮点和矢量中的半精度浮点,分别需要开启 zfh 和 zvfh0P1,因为 zvfh 还在试验性阶段所以需要加 -menable-experimental-extensions,具体可参考 clang/test/CodeGen/RISCV/rvv-intrinsics/vfclass.c 测试用例,用到了 zvfh。另外,一部分指令也根据 SPEC 演进做了相应的更改,例如:vmandot 和 vmornot 已更改为 vmandn 和 vmorn 等。
自动矢量化
虽然 LLVM15 版本已经支持了 RISC-V Vector Intrinsic,但是对于大工程来说,将代码转换成 RISC-V Vector Intrinsic 接口使用是一件非常繁杂的事情,这时候支持自动向量化是一件非常有意义的事情。
1. 相关选项
| 选项 | 说明 |
|---|---|
| -fno-vectorize | 循环矢量化开关,默认开启 |
| --riscv-v-vector-bits-min | 指定 zvl 最小的 VLEN,不能低于配置的最大 zvl 数(因为 v 自动开启 zvl128b,所以没指定具体 v 扩展时此选项需要开启128以上) |
| -force-vector-width | 向量化宽度(VF) |
| -force-vector-interleave | 向量化展开因子(UF) |
| -Rpass=loop-vectorize | 开启将提示能矢量化的循环 |
| -Rpass-analysis=loop-vectorize | 开启将提示各种错过矢量化机会的原因 |
| -Rpass-missed=loop-vectorize | 开启将提示不能矢量化的循环 |
2. 自动矢量化要求
LLVM15 以后开始支持 RISC-V 自动矢量化,其中需要3个条件:
(1)开启自动矢量化需要开启 -O1 以上选项
(2)添加 -mllvm --riscv-v-vector-bits-min 配置 VLEN
(3)march 选项中加入 v
自动矢量化主要是循环向量化居多,所以尽量将循环写法维持在可矢量化状态。
调试过程中可以通过 -Rpass=loop-vectorize、-Rpass-analysis=loop-vectorize、-Rpass-missed=loop-vectorize 去查看分析 loop 过程中的矢量化。
3. 矢量化代码格式要求
使用简单的循环。避免复杂的循环终止条件——迭代上限在循环中必须是不变的。
void test(int *a, int *b, int *c)
{
for (int i = 0; i <= a[i]; i++)
c[i] = b[i];
}此时使用 -Rpass-analysis=loop-vectorize 可以发现提示:
loop not vectorized: could not determine number of loop iterations迭代上限变化时无法确定迭代次数,如果在循环中加入 break、return,亦是无法向量化的,向量化循环需要单进单出。
避免使用分支语句,或者使用大多数函数调用。
void test1();
void test(int n, int *a, int *b)
{
for (int i = 0; i <= n; i++) {
test1();
a[i] = b[i];
}
}此时使用 -Rpass-analysis=loop-vectorize 可以发现提示:
loop not vectorized: call instruction cannot be vectorized循环中有调用无法进行矢量化。
避免循环迭代之间的依赖关系,或者至少避免写后读取依赖关系。
void test(int n, int *a)
{
for (int i = 0; i <= n; i++) {
a[i] += a[i - 1];
}
}此时使用 -Rpass-analysis=loop-vectorize 可以发现提示:
value that could not be identified as reduction is used outside the loop这是因为循环中,多次迭代如果同时执行,后序读取数据的迭代可能在前一次写入之前,这可能会导致不正确的结果。
4. 自动矢量化流程
首先中端部分用的是公共矢量化分析,这一块 LLVM 有两种类型的自动矢量化实现:SLP 矢量化器和循环矢量化器。SLP Vectorizer 将多个标量指令聚合为一条向量指令,该指令通常在单个基本块上运行。而循环向量化器则扩大循环体内的标量指令以一次执行多个迭代。在这项工作中,我们将自动矢量化算法集成到循环矢量化器中,以通过扫描循环并行化循环。(自动矢量化分析可以参考编译器优化那些事儿(12):LLVM 自动向量化
RISC-V 后端转 RISC-V Vector 通过多种优化组合进行转换,首先依靠插入 vmv 来进行标量矢量转换,然后对于转换后的数据中的 load、store 转化为 vse、vle 来进行矢量存读,当然,其中的 add 指令也转化为 ADD_VL,smin 转化成 SMIN_VL 进行矢量运算。
例如:
Legalizing: t28: ch = store<(store (s128) into %ir.lsr.iv31, align 2, !tbaa !12, !alias.scope !24, !noalias !26)> t23:1, t78, t2, undef:i32, test.c:7:8
Legalizing store operation
Optimizing float store operations
Trying custom lowering
Creating constant: t83: i32 = TargetConstant<8428>
Creating new node: t84: ch = llvm.riscv.vse<(store (s128) into %ir.lsr.iv31, align 2, !tbaa !12, !alias.scope !24, !noalias !26)> t23:1, TargetConstant:i32<8428>, t77, t2, Constant:i32<8>, test.c:7:8
... replacing: t28: ch = store<(store (s128) into %ir.lsr.iv31, align 2, !tbaa !12, !alias.scope !24, !noalias !26)> t23:1, t78, t2, undef:i32, test.c:7:8
with: t84: ch = llvm.riscv.vse<(store (s128) into %ir.lsr.iv31, align 2, !tbaa !12, !alias.scope !24, !noalias !26)> t23:1, TargetConstant:i32<8428>, t77, t2, Constant:i32<8>, test.c:7:8最后在 insertVSETVLI pass 中分析在指令中插入 vset(i)vl(i) 来保证结果正确性。
5. RISCV自动矢量化前后对比
以下例子分析矢量化前后差异:
void test(int n, int *a, int *b)
{
for (int i = 0; i <= n; i++) {
a[i] = b[i];
}
}以下左边为开启 v 的自动矢量化生成的汇编文件,右边没有开启矢量化
左边命令: clang -march=rv32imfdcv -O2 -w -S -mllvm --riscv-v-vector-bits-min=128
右边命令: clang -march=rv32imfdc -O2 -w -S
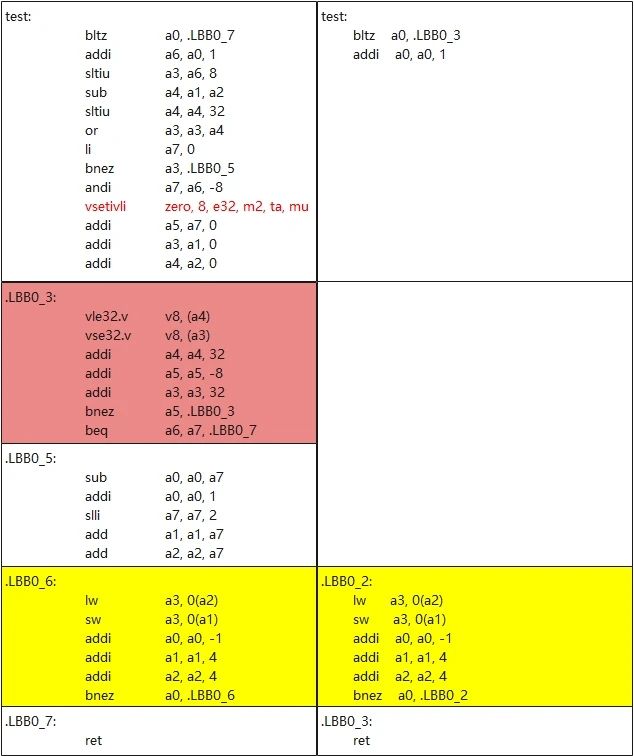
可以看出,左边开启自动矢量化时因为向量长度不可知,所以导致还是存在尾部用原指令处理的问题。中间矢量化序列的 vsetivli 中可以看出,因为我们开启的是 vlen=128,用两个寄存器拼接长度为256,元素大小为32,所以相当于一次处理8个数据,而右边一次处理一个数据。从整体看来,codesize 膨胀近3倍,但是可以分析看出来左边 .LBB0_3 块进行循环一次相当于右边 .LBB0_2 块循环8次,只需要总循环为8次以上,左边整体的指令数就能低于右边。
RISC-V Vector 优劣分析
RISC-V Vector 优点很多,但是现有的功能方面存在不足,如 predication/mask,向量长度不可知向量化支持不完善导致尾部处理存在问题。

RISC-V Vector 有三种主要的循环向量化方法:
使用时总是占满整个矢量寄存器组,当固定长度的 SIMD 用,缺点是存在尾循环。此方式可利用 Loop Vectorizer 实现,因此相对简单,不需要特殊的 LLVM IR,但会丢失 RISC-V Vector 的许多特性。(现在LLVM就是使用这种方法)
将尾循环合并到向量循环中。(相当于每次使用前用 vsetvl) 这种是通过在每次选代中设置向量长度来实现的。这会在循环的所有向量指令上产生配置指令,需要一些特殊的IR,这里使用 LLVM VP (Vector Predication) intrinsics。
一种折中方法就是在向量体中使用整个寄存器,然后设置 vl 执行剩下的。(相当于每次用整个,当用不了整个的时候,设置 vl 执行剩下的)
总结
本文简单介绍了 RISC-V Vector 的发展情况以及 LLVM 演进过程,介绍了自动矢量化的大致过程,主要的矢量化还是依靠中端的分析,后端还在不断优化中。
总而言之,向量化大势所趋,但优化之路还很漫长。
参考
https://en.wikipedia.org/wiki/RISC-V
RISC-V Vector自动向量化及在llvm中的实现 - 兆松科技
articles/20230629-rvv-note.md · aosp-riscv/working-group - Gitee.com
https://github.com/RISCVtestbed/rvv-rollback
https://itnext.io/grokking-risc-v-vector-processing-6afe35f2b5de
Auto-Vectorization in LLVM — LLVM 19.0.0git documentation
Andes RISC-V Vector Processor NX27V is Upgraded to RVV 1.0 - Andes Technology
转载自鲲鹏社区:https://www.hikunpeng.com/zh/developer/techArticles/20240228-7















 2770
2770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









