






naive_bayes_text_classification.py
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB, BernoulliNB
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# 第一部分:多项式朴素贝叶斯用于垃圾邮件分类
print("===== 多项式朴素贝叶斯用于垃圾邮件分类 =====")
# 训练数据
emails = [
"Buy cheap watches. Discount prices on all watches.",
"Meeting agenda for our project meeting next week.",
"Great offers! Get a free gift with your purchase.",
"Important update: Please attend the project meeting tomorrow."
]
# 对应的标签(0 表示垃圾邮件,1 表示非垃圾邮件)
labels = [0, 1, 0, 1]
# 文本特征提取,使用词袋模型
vectorizer = CountVectorizer()
X_train = vectorizer.fit_transform(emails)
# 创建多项式朴素贝叶斯分类器
multi_classifier = MultinomialNB()
# 训练分类器
multi_classifier.fit(X_train, labels)
# 测试数据
test_emails = [
"Special discount on watches today!",
"Project meeting agenda for next week."
]
# 对测试数据进行特征提取
X_test = vectorizer.transform(test_emails)
# 预测分类标签
predicted_labels = multi_classifier.predict(X_test)
# 输出预测结果
for i, email in enumerate(test_emails):
label = "垃圾邮件" if predicted_labels[i] == 0 else "非垃圾邮件"
print(f"邮件 '{email}' 被分类为: {label}")
# 第二部分:伯努利朴素贝叶斯用于文本情感分类
print("\n===== 伯努利朴素贝叶斯用于文本情感分类 =====")
# 训练数据(正面情感为 1,负面情感为 0)
texts = [
"I love this product, it's amazing!",
"Terrible product, wouldn't recommend it to anyone.",
"Great purchase, very satisfied with the quality.",
"Disappointed with the performance, not worth the price.",
"Best choice I've ever made, highly recommended!",
"I hated it, worst purchase ever!"
]
# 对应的标签(1 表示正面情感,0 表示负面情感)
sentiment_labels = [1, 0, 1, 0, 1, 0]
# 文本特征提取,使用二元特征(是否出现)
binary_vectorizer = CountVectorizer(binary=True)
X_train_binary = binary_vectorizer.fit_transform(texts)
# 创建伯努利朴素贝叶斯分类器
bernoulli_classifier = BernoulliNB()
# 训练分类器
bernoulli_classifier.fit(X_train_binary, sentiment_labels)
# 测试数据
test_texts = [
"I hate it, the worst weather ever",
"Absolutely fantastic, exceeded my expectations.",
"Not bad, but not great either."
]
# 对测试数据进行特征提取
X_test_binary = binary_vectorizer.transform(test_texts)
# 预测情感标签
predicted_sentiments = bernoulli_classifier.predict(X_test_binary)
# 输出预测结果
for i, text in enumerate(test_texts):
label = "正面情感" if predicted_sentiments[i] == 1 else "负面情感"
print(f"文本 '{text}' 被分类为: {label}")
# 第三部分:对比分析
print("\n===== 对比分析 =====")
# 生成一些测试数据用于对比
np.random.seed(42)
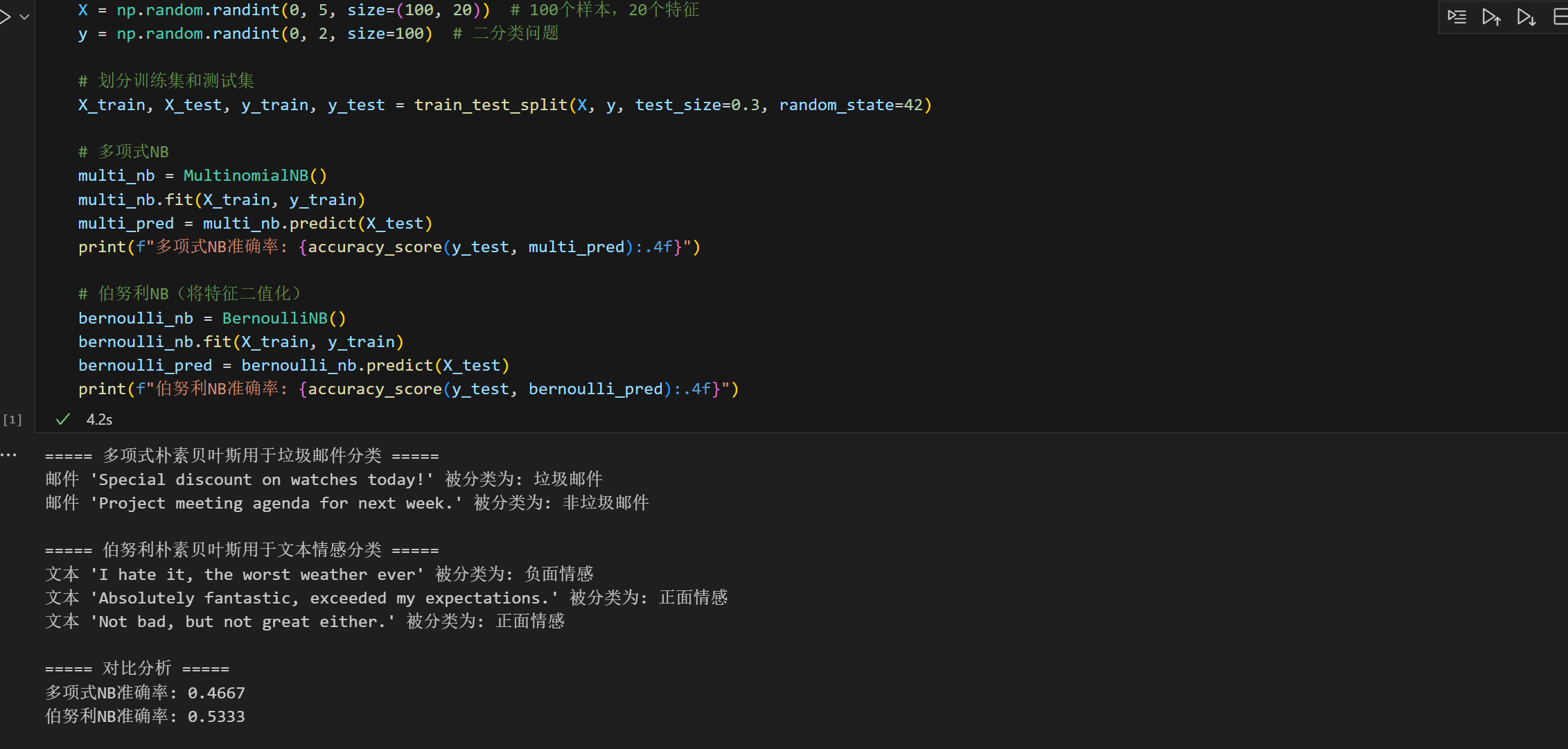
X = np.random.randint(0, 5, size=(100, 20)) # 100个样本,20个特征
y = np.random.randint(0, 2, size=100) # 二分类问题
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 多项式NB
multi_nb = MultinomialNB()
multi_nb.fit(X_train, y_train)
multi_pred = multi_nb.predict(X_test)
print(f"多项式NB准确率: {accuracy_score(y_test, multi_pred):.4f}")
# 伯努利NB(将特征二值化)
bernoulli_nb = BernoulliNB()
bernoulli_nb.fit(X_train, y_train)
bernoulli_pred = bernoulli_nb.predict(X_test)
print(f"伯努利NB准确率: {accuracy_score(y_test, bernoulli_pred):.4f}")




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











