






一、为什么需要代码优化?
在软件开发中,「代码优化」是一个贯穿项目生命周期的关键环节。它不仅能提升程序的运行效率、降低资源消耗,还能增强代码的可读性、可维护性,甚至影响系统的可扩展性。
典型场景:
- 当程序运行速度慢(如 API 响应超时),需性能优化;
- 当代码晦涩难懂(如复杂逻辑嵌套),需可读性优化;
- 当系统架构臃肿(如模块耦合过强),需架构优化。
误区提醒:避免过早优化!优先保证代码功能正确,再针对瓶颈进行优化(参考 Knuth 名言:“过早优化是万恶之源”)。
二、代码优化的核心方向
(一)性能优化:让程序跑更快
1. 算法与数据结构优化
原则:选择时间复杂度更低的算法,避免冗余计算。
案例:
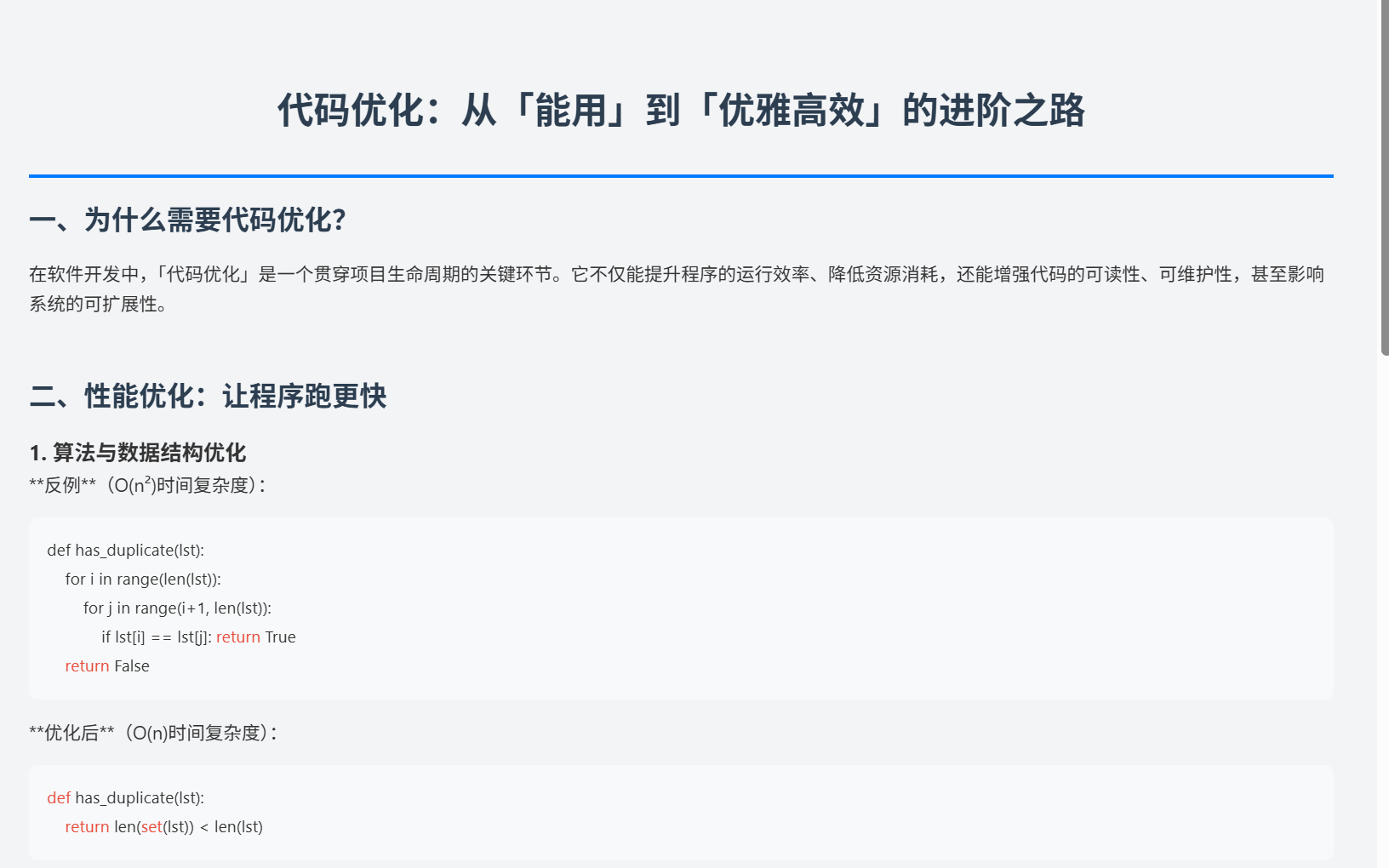
- 低效示例(O (n²) 时间复杂度的重复查找):
python
运行
# 检查列表中是否存在重复元素(低效) def has_duplicate(lst): for i in range(len(lst)): for j in range(i+1, len(lst)): if lst[i] == lst[j]: return True return False - 优化方案(利用集合的 O (1) 查找,O (n) 时间复杂度):
python
运行
def has_duplicate(lst): return len(set(lst)) < len(lst)
2. 减少 IO 与网络操作
策略:批量处理 IO 操作,避免频繁读写磁盘或调用接口。
案例:
- 低效示例(逐行写入文件):
python
运行
with open("data.txt", "w") as f: for line in data: f.write(line + "\n") # 每次调用write触发系统IO - 优化方案(一次性写入缓冲区):
python
运行
with open("data.txt", "w") as f: f.writelines([line + "\n" for line in data]) # 减少IO次数
3. 利用缓存与记忆化(Memoization)
场景:重复计算相同参数的函数时,缓存结果避免重复运算。
工具:Python 的lru_cache装饰器、Redis 分布式缓存。
案例:
python
运行
from functools import lru_cache
# 计算斐波那契数列(带缓存)
@lru_cache(maxsize=None)
def fib(n):
if n <= 1:
return n
return fib(n-1) + fib(n-2)
(二)可读性优化:让代码更易读
1. 变量与函数命名语义化
原则:命名应清晰表达用途,避免单字母变量或模糊词汇。
反例:
python
运行
# 难以理解的命名
def f(x):
for i in x:
if i > 100:
return True
优化后:
python
运行
# 语义化命名
def has_large_number(numbers):
for number in numbers:
if number > 100:
return True
2. 拆分长函数与复杂逻辑
策略:将超过 50 行的函数拆分为小函数,遵循 “单一职责原则”。
案例:
python
运行
# 冗长的单函数(反例)
def process_data(data):
# 1. 数据清洗
cleaned_data = data.strip().split(",")
# 2. 格式转换
converted_data = [int(item) for item in cleaned_data if item.isdigit()]
# 3. 统计分析
average = sum(converted_data) / len(converted_data)
return average
# 优化后(拆分为独立函数)
def clean_data(data):
return data.strip().split(",")
def convert_to_numbers(items):
return [int(item) for item in items if item.isdigit()]
def calculate_average(numbers):
return sum(numbers) / len(numbers)
def process_data(data):
cleaned = clean_data(data)
numbers = convert_to_numbers(cleaned)
return calculate_average(numbers)
3. 添加必要注释
原则:注释应解释 “为什么” 而非 “是什么”,避免冗余。
示例:
python
运行
# 计算用户年龄(根据生日日期)
def calculate_age(birth_date):
today = date.today()
age = today.year - birth_date.year # 先计算年份差
if (today.month, today.day) < (birth_date.month, birth_date.day):
age -= 1 # 若未过今年生日,年龄减1
return age
(三)架构优化:提升系统可维护性
1. 减少模块耦合:依赖注入与接口抽象
案例:
python
运行
# 强耦合代码(反例)
class UserService:
def __init__(self):
self.db = Database() # 直接依赖具体数据库类
# 优化后(依赖注入)
class UserService:
def __init__(self, database):
self.db = database # 通过接口注入依赖
# 使用时传入具体实现
db = MySQLDatabase()
user_service = UserService(db)
2. 引入设计模式
场景:
- 单例模式:确保全局唯一实例(如配置管理器);
- 工厂模式:解耦对象创建逻辑(如根据类型生成不同报表)。
工厂模式示例:
python
运行
class ChartFactory:
@staticmethod
def create_chart(chart_type):
if chart_type == "pie":
return PieChart()
elif chart_type == "bar":
return BarChart()
raise ValueError("Invalid chart type")
3. 分层架构设计
典型分层:
- 表现层(UI/API):处理用户输入输出;
- 业务逻辑层:封装核心业务规则;
- 数据层:负责数据库交互。
优势:各层职责分离,修改某层不影响其他层。
三、代码优化的工具与方法
1. 性能分析工具
- Profiler:Python 的
cProfile、Java 的VisualVM,定位代码瓶颈; - 内存分析:Python 的
memory_profiler、Chrome DevTools 的 Memory 面板。
2. 静态代码检查
- 工具:
- Python:
flake8、pylint(检查代码风格与潜在问题); - JavaScript:
ESLint、Prettier(统一代码格式)。
- Python:
- 示例:
bash
# 使用pylint检查Python代码 pylint my_script.py
3. 自动化测试保障
优化前编写单元测试,确保修改后功能不变:
python
运行
# 单元测试示例(使用pytest)
def test_has_duplicate():
assert has_duplicate([1, 2, 3]) is False
assert has_duplicate([1, 2, 1]) is True
四、代码优化的最佳实践
- 优先解决关键瓶颈:用 Profiler 定位耗时最长的函数,避免在非热点代码上浪费时间;
- 保持代码简洁:遵循 KISS 原则(Keep It Simple, Stupid),避免过度设计;
- 团队协作优化:通过代码审查(Code Review)发现集体智慧下的优化点;
- 持续迭代:优化是渐进过程,结合用户反馈和性能监控逐步调整。
五、总结
代码优化是开发者从 “完成功能” 到 “打造高质量软件” 的必经之路。它不仅需要扎实的算法基础和设计思维,还需结合具体场景权衡取舍(如空间换时间、可读性与性能的平衡)。
记住:优秀的代码如同优雅的诗歌 —— 既要有运行时的高效,也要有阅读时的清晰。通过持续实践和工具辅助,你将逐渐掌握优化的艺术,让代码兼具实用性与美感。



















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











